同感,而且感觉欠拟合那部分如果通过增加模型复杂度啥的,加入激活函数,非线性层应该也能学出来
“如果一个理论能拟合数据,且有具体的测试可以用来证明它是错误的,那么它就是好的”
没有理解这句话啥意思呢?

对于np数组是不是无法直接通过load_array来读取,要先把np组转转成张量元组才能读取,np数组的size属性是个int。
![]()
这里判断的时候size返回的不是维度,size(0)会异常
d2l.train_epoch_ch3这个属性是没是没有了
训练数据可视化,红线是神经网络输出,蓝点是训练数据,绿点是测试数据
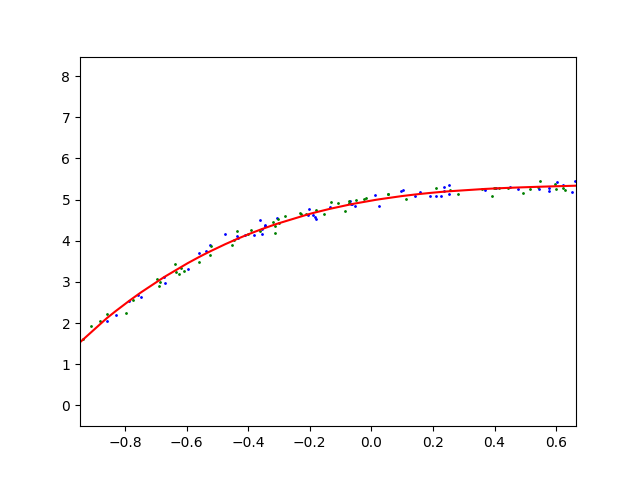
三阶多项式函数拟合(正常)
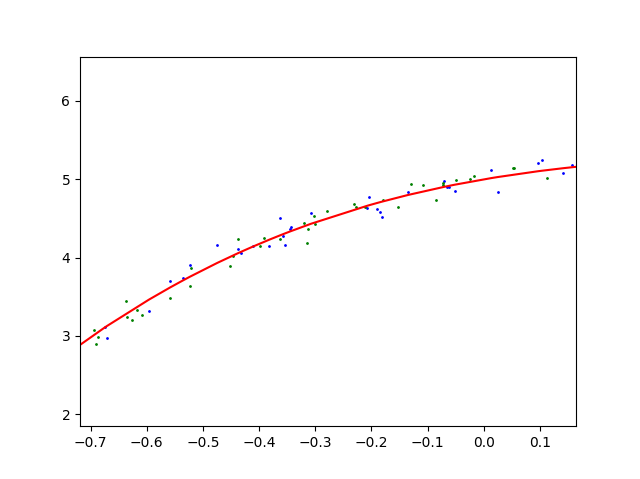
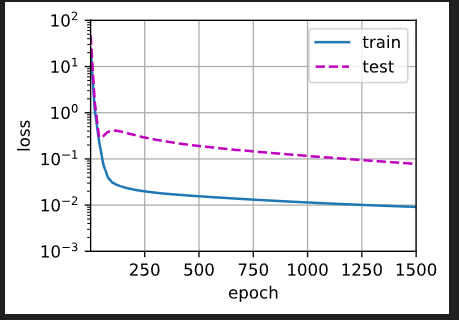
线性函数拟合(欠拟合)
这里神经网络实际上是用线性函数去拟合三阶多项式函数,很明显误差很大
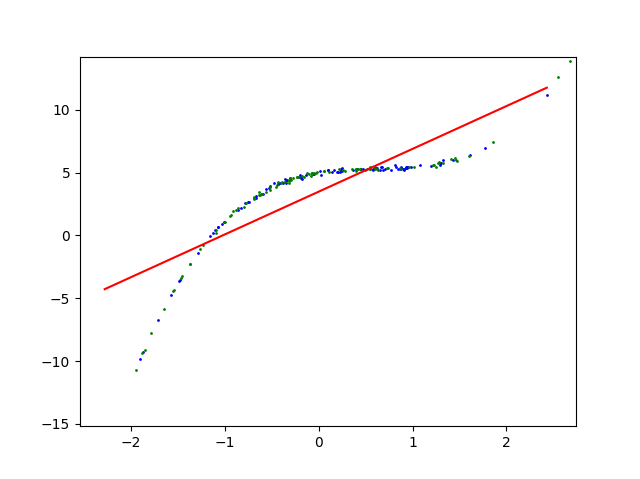
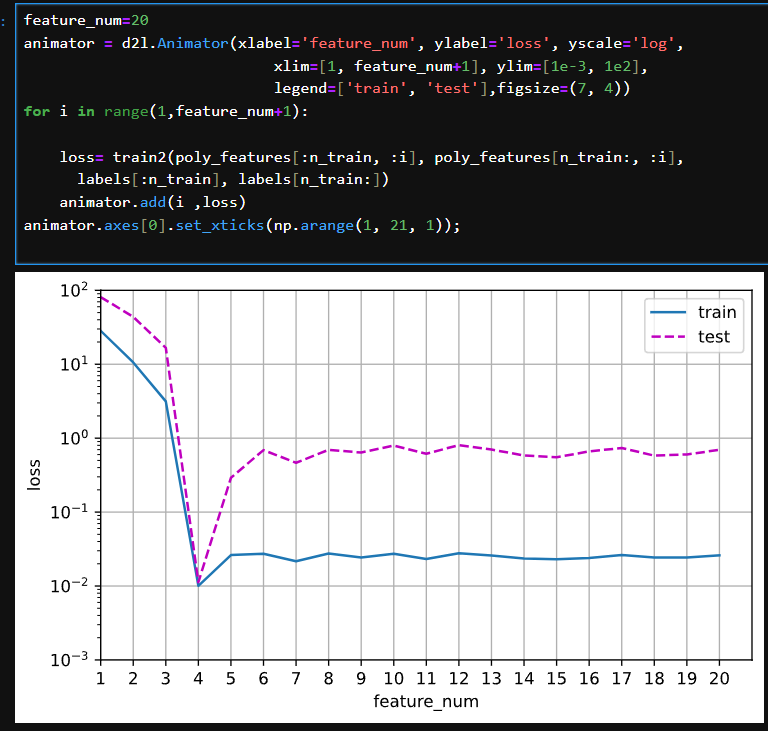
高阶多项式函数拟合(过拟合)
从图里看不出来过拟合
不过可以推断,神经网络是在用高(非常高)阶多项式函数去拟合三阶多项式函数,因为高阶多项式函数有更丰富的曲线,所以应该是拟合噪音去了,导致过拟合
1 Like
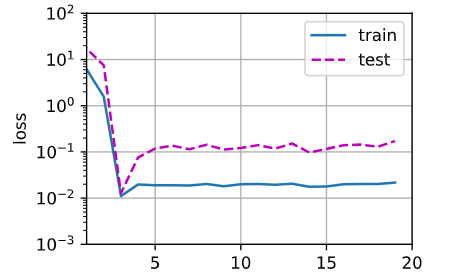
我的为什么是这样?
因为这里用的测试集在训练集/验证集区间内,相当于用训练集去验证的模型,所以看不出来过拟合,需要把features取值范围变大才能看出来
表示5,1.2,3.4这些参数的个数,也就是true_w这个向量的元素个数。max_degree=20,就表示这个多项式最大项为w * x^19

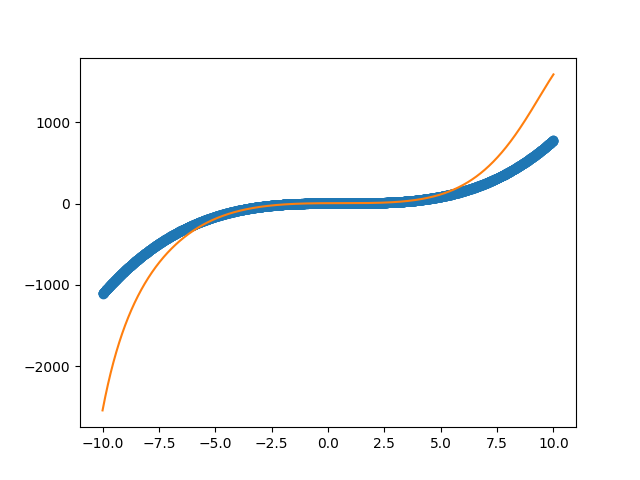
过拟合参考的图像应该是这样的
没问题的,nn.MSELoss(reduction=‘none’)这里是批次里面的每一个样本返回一个loss
但实际上我们MSELoss需要的是一个标量loss,而不是一个批次
所以方法1:直接nn.MSELoss(),默认我们取reduction=‘mean’,这个时候模型里面就不要写求平均了,它直接返回批次里面的平均值,即一个标量值
方法2:我们按照这样的方法写nn.MSELoss(reduction=‘none’),后面计算loss=loss.mean(),同样是一个平均值标量
图4.4.1的纵坐标是不是写成“误差”更好,写成“损失”会与loss混淆
样本数大,也不会过拟合,把样本调到100试下
上文提到:是否过拟合或欠拟合可能取决于模型复杂性和可用训练数据集的大小。既然是研究两个变量的影响,那么在研究数据集大小的时候自然应该控制变量,保持同样的模型复杂度才有研究的必要。
为什么我感觉这里并没有证明过拟合和欠拟合啊?因为这里在生成labels是使用的true_w只有前四个值是非0的,意味着我们仅使用了poly_features的前四列,而这里的点积相当于做了一个线性变换,那当且仅当后面训练线性模型是poly_features的前四列时就一定能得到较好的结果,只要不是前四列就一定会得到一个较差的结果。感觉这本质上还是线性模型与多项式没啥关系,也和过拟合和欠拟合没关系吧。实在是没能理解这里的意思。。。
请教一下,在实际使用中我们是否无需纠结究竟用mean还是sum,只需要在调超参的时候看哪个lr合适就可以
x^n(n>1)是人为构建的新的特征,算是一种特征工程了
样本在初始化的时候,多随机几次,应该可以的。