https://zh.d2l.ai/chapter_multilayer-perceptrons/underfit-overfit.html
在4.4.3.2中写道:“训练数据集中的样本越少,我们就越有可能(而且更严重)遇到过拟合”。是不是有一个前提对于相同复杂度的模型来说。英文原文是这样写的“Fixing our model, the fewer samples we have in the training dataset, the more likely (and more severely) we are to encounter overfitting.”
3 Likes
这个例子用的好妙~~~~~~~~~~~啊
1 Like
有人用线代给出解过吗?
zszszszs
此处evaluate_loss的计算似乎存在问题,metric.add(l.sum(), l.numel())似乎应该为metric.add(l*len(out), l.numel())
1 Like
我也感觉是这样,MSELoss() 默认取 mean 了
为什么loss定义为nn.MSELoss(reduction=‘none’)要报错 RuntimeError : grad can be implicitly created only for scalar outputs,而定义为nn.MSELoss()则能运行,但正太、欠拟合、过拟合区别不大
1 Like
RuntimeError: grad can be implicitly created only for scalar outputs
这是什么原因啊?怎么解决呢?
2 Likes
loss定义成nn.MSELoss()就行
你可以利用解析解公式算一下,解析解公式在上一章线性回归基础
在这一节中给了一个多项式的例子,我们可以把它视为一个单个输入参数x,单个输出函数y的情况吗?
我自己这样试了一下,用多个隐藏层,我本来觉得增加隐藏层的效果总会等价于把一个x变成多个多项式项的输入,然而结果的拟合效果远没有例子中的处理方式好。
可是实际情况下,我们也许会遇到这种问题,即输入的参数非常少,而y=f(x)的映射超级复杂我们并不知道具体形式。这种情况下,我们通常应该采用什么办法呢?谢谢!
1 Like
# 以20为最高幂直接给出一个不确切的解析解
w_=torch.linalg.inv(poly_features.t()@poly_features)@poly_features.t()@labels.reshape(200,1)
# 以3为最高幂直接给出解析解
w_=torch.linalg.inv(poly_features[:,:4].t()@poly_features[:,:4])@poly_features[:,:4].t()@labels.reshape(200,1)
3 Likes
生成数据集为何不直接通过 torch.tensor 来完成?poly_features 可无需使用 for 循环。例如:
import math
import torch
max_degree = 20
n_train, n_test = 100, 100
true_w = torch.zeros(max_degree)
true_w[:4] = torch.tensor([5, 1.2, -3.4, 5.6])
features = torch.randn((n_train+n_test, 1))
features = features[torch.randperm(len(features))]
poly_features = torch.pow(features, torch.arange(max_degree))
poly_features /= torch.tensor(
[math.gamma(i+1) for i in range(max_degree)]
)
labels = poly_features @ true_w
labels += torch.randn(labels.shape) * 0.1
labels = labels.reshape(-1, 1)
1 Like
如果不对多项式特征进行标准化,对于20阶多项式计算出来的权重为:
weight: [[nan nan nan nan nan ...]]
请问这里是为什么呀?
1 Like
train(poly_features[:n_train, :4], poly_features[n_train:, :4],
labels[:n_train], labels[n_train:])
在运行这段代码时出现以下问题怎么解决呢?
ValueError : Failed to find font DejaVu Sans:style=normal:variant=normal:weight=normal:stretch=normal:size=10.0, and fallback to the default font was disabled
findfont: Font family [‘STIXGeneral’] not found. Falling back to DejaVu Sans
我认为这个问题和在计算交叉熵的时候面临的问题是一样的,指数计算造成数据上溢。
画了一下从选取3个特征到选取20个特征的loss图
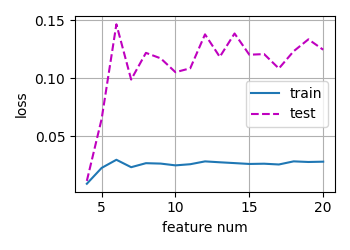
4 Likes
欠拟合过拟合这部分的代码,用沐神书上的原代码跑的(复制粘贴的),报错了,RuntimeError: grad can be implicitly created only for scalar outputs 。把书上的代码loss = nn.MSELoss(reduction=‘none’)改成 loss = nn.MSELoss()就好了。书上的代码都加了reduction=‘none’,沐神的课件里都没加,我之前是按课件走的,这回从书上粘贴了一次,两回的loss求法不一样就出错了
loss = nn.MSELoss(reduction=‘none’)改成 loss = nn.MSELoss()就好了。书上的代码都加了reduction=‘none’,沐神的课件里都没加,我之前是按课件走的,这回从书上粘贴了一次,两回的loss求法不一样就出错了