[注] : module ‘d2l.torch’ has no attribute ‘train_epochs_ch3’ 可能开发人员把 ch3 章节代码删了
解决办法:
import d2l
print(d2l._file_)
查出你的电脑里d2l的包的地址
然后进去 torch.py
把 之前 softmax的0开始实现里的 train_epoch_ch3 和 train_ch3 复制粘贴进去,然后就可以了
-
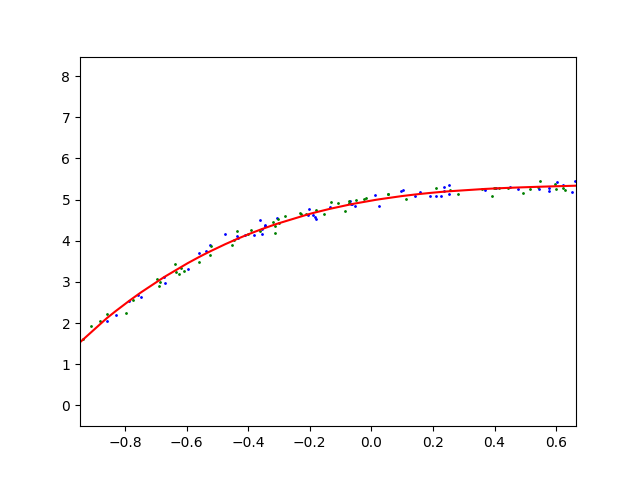
这个多项式回归问题可以准确地解出吗?提示:使用线性代数。
答:不怎么会 ,线性代数可以解决 多维度问题么?
-
代码如下:
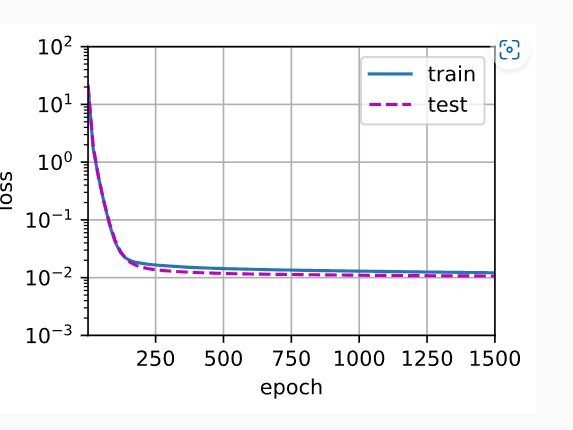
# 随着feature_num的增加 loss的变化
def train1(train_features,test_features,train_labels,
test_labels,num_epochs= 400):
loss = nn.MSELoss(reduction='none')
input_shape = train_features.shape[-1]
net = nn.Sequential(nn.Linear(input_shape,1,bias=False))
batch_size = min(10,train_labels.shape[0])
train_iter = d2l.load_array((train_features,
train_labels.reshape(-1,1)),batch_size)
test_iter = d2l.load_array((test_features,
test_labels.reshape(-1,1)),batch_size,is_train=False)
trainer = torch.optim.SGD(net.parameters(),lr=0.01)
for epoch in range(num_epochs):
d2l.train_epoch_ch3(net, train_iter, loss, trainer)
if epoch == 399:
train_loss=evaluate_loss(net,train_iter,loss)
test_loss = evaluate_loss(net,test_iter,loss)
return train_loss,test_loss
import matplotlib.pyplot as plt
a = range(1,20)
animator = d2l.Animator(xlabel='feature_nums', ylabel='loss', yscale='log',
xlim=[1, 20], ylim=[1e-3, 1e2],
legend=['train', 'test'])
for i in a:
c=0
d=0
c,d=train1(poly_features[:n_train,:i],poly_features[n_train:,:i],
labels[:n_train],labels[n_train:])
animator.add(i,(c,d))
结果:
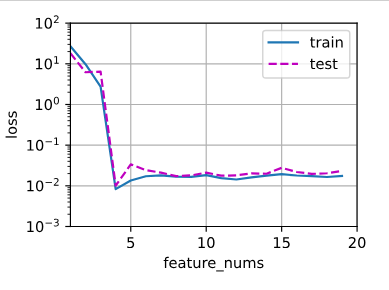
结论 : 随着 feature_nums 的增加模型的 loss 趋于稳定,虽然没有最低点nums=4效果好
但是 误差已经很小了,测试集和训练集相差结果也不是很大,过拟合可以接受
-
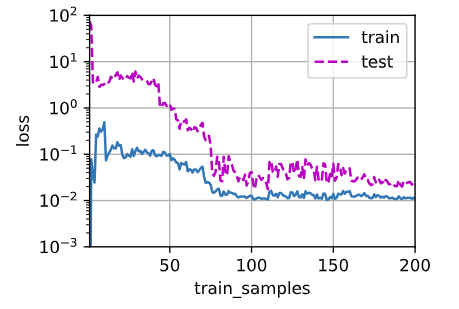
随着训练数据量的增加 loss的变化:
def train2(train_features,test_features,train_labels,
test_labels,num_epochs=400):
loss = nn.MSELoss(reduction='none')
input_shape = train_features.shape[-1]
net = nn.Sequential(nn.Linear(input_shape,1,bias=False))
batch_size = min(10,train_labels.shape[0])
train_iter = d2l.load_array((train_features,
train_labels.reshape(-1,1)),batch_size)
test_iter = d2l.load_array((test_features,
test_labels.reshape(-1,1)),batch_size,is_train=False)
trainer = torch.optim.SGD(net.parameters(),lr=0.01)
for epoch in range(num_epochs):
d2l.train_epoch_ch3(net, train_iter, loss, trainer)
if epoch == (num_epochs-1):
return evaluate_loss(net, train_iter, loss),evaluate_loss(net, test_iter, loss)
b= range(1,n_train)
anm = d2l.Animator(xlabel='data_nums',ylabel='loss',yscale='log',
xlim=[1,n_train],ylim=[1e-3, 1e2],
legend=['train','test'])
for i in b:
c=0
d=0
c,d = train2(poly_features[:i,:4],poly_features[n_train:,:4],
labels[:i],labels[n_train:])
anm.add(i,(c,d))
结果:
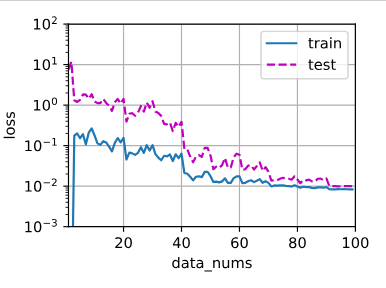
结论: 一开始明显过拟合 ,数据量太小 ,训练集误差小,测试集误差大
随着训练数据量的增加,训练集和测试集的loss 差距逐渐减小
80个epochs 后二者都趋于平稳
-
可能会发生上溢出 , 超过数据表示范围 ,而且数据太大也不利于计算
-
误差误差,泛化误差和训练误差都不可能为0(除非只有一个样本,训练误差为0)