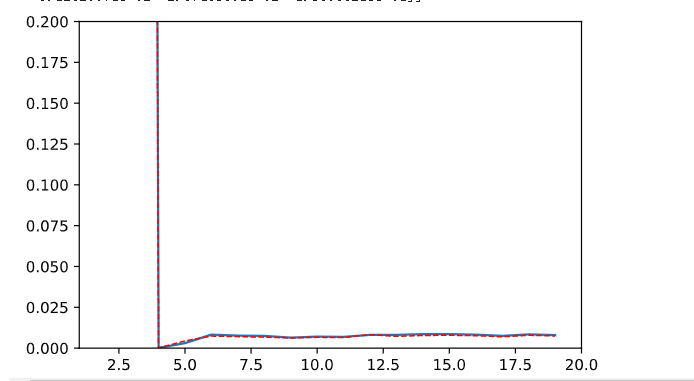

按代码跑出来的结果,好像没过拟合的既视感,
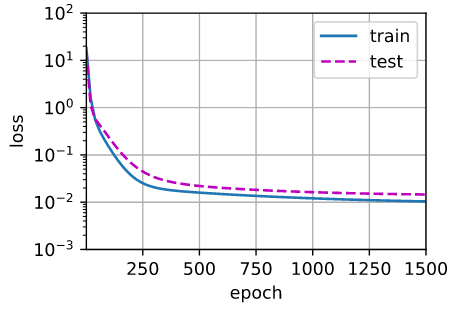

很遗憾,为了避免后面的同学再次进坑,不得不指出你的解释存在问题。
正确的写法就是loss = nn.MSELoss(reduction=‘none’),
这样求出来的是【张量】,如果不指定reduction则默认是均值(标量)。
新版的train_epoch_ch3函数接受的loss就是一个张量,函数里通过l.mean().backward()求出均值【标量】以进行梯度计算。
上古版本的train_epoch_ch3代码错误的将loss梯度计算处理为l.backward(),则要求接受的loss就是一个标量,
所以需要使用loss的均值即 loss = nn.MSELoss(),
否则标量和张量格式不匹配无法进行梯度运算,才会报错RuntimeError: grad can be implicitly created only for scalar outputs 。
这与当时使用的优化器是pytorch内置还是d2l自己实现的有关,pytorch内置优化器求均值是在loss计算中完成的,d2l自己定义的优化器求均值是在sgd时完成的。一个要求的loss是均值(标量),一个要求的loss是求和(l.sum(),l是张量),所以各种写法只要对应上,基本也不会差太多(只要标量和张量别搞错,就算mean和sum搞错,最多就差一个batch_size量级learning rate)。
请问你这个是怎么画的吖?我没想出来,谢谢 ![]()
为什么代码复制到 pycharm运行每次拟合出来的值会变 是没设定随机种子嘛 但是jupyter就不变啊 我是错过一开始哪里有设置随机种子的环节了嘛
而且每次在pycharm拟合出来的结果不对拟合的 好奇怪 不知道自己哪儿错了
把它视作单个输入x,得到单个输出y的情况下,比例子中只给出前两个维度更容易导致欠拟合。
在实际情况下,当输入参数很少时,也许需要去分析寻找更多的特征(参数)和输出的关系,毕竟即便再庞大再复杂的模型若仅输入了非常有限(不足)的参数,也很难正确拟合数据。
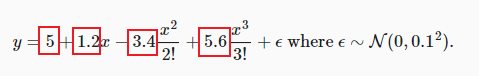
我理解这个例子其实不算拟合多项式,因为输入模型的feature时poly_feature,模型是在拟合前面的系数。
2:
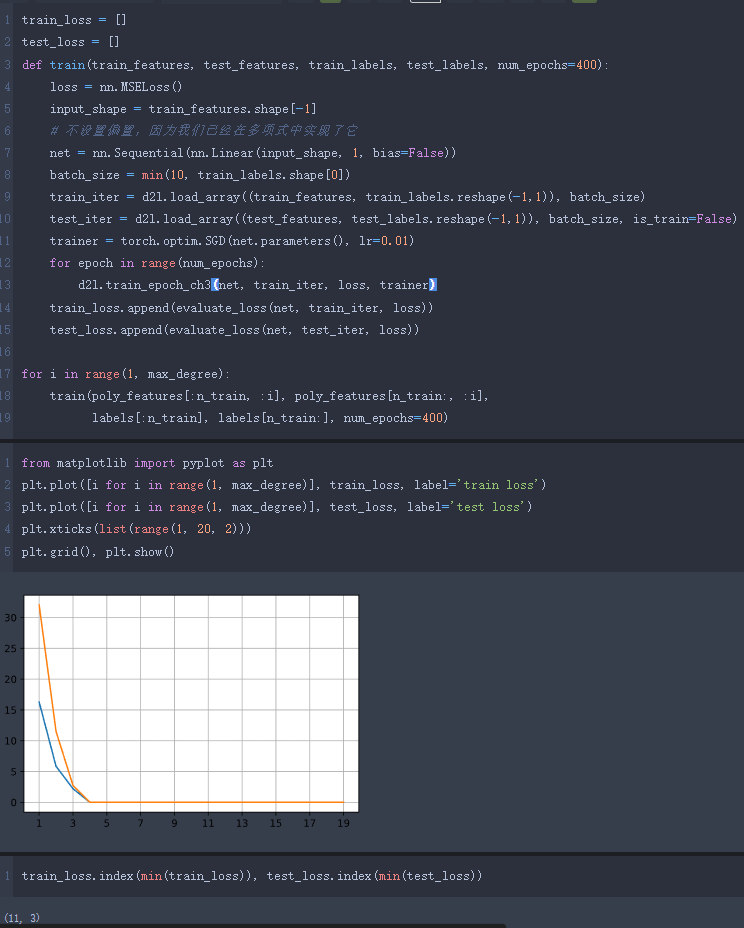
随着多项式次数增加 train_loss 逐渐减小,但是到达11次的时候,开始出现精度下降的情况 产生这种现象可能的原因是数据量太小 不足以训练出弹性大的模型
在测试训练集上表现最好的依然是3次多项式,根据拉格朗日多项式可以知道如果训练数据集size=100,那么就需要一个100次多项式就可以完全拟合训练数据集 但是会出现龙格现象导致在test上面表现很差
3、如果不除以阶乘,那么很有可能会出现指数(上或下)溢出 导致结果出现nan。我的解决思路是
对每一项取log
4、不可能期待看到泛化误差为0,即使数据再有干扰项的情况下 不设置随机数种子,就算按照原来的生成方式都不能达到每次完全一致

为什么将训练数据features改为0-1000之后做训练会导致神经网络输出none值,但是将其限制在0-1或0-2的较小区间中就不会出现这个问题
方便放一下源代码嘛,不太知道应用在此处问题所在,只知道grad can be implicitly created only for scalar outputs一般为非标量求导错误
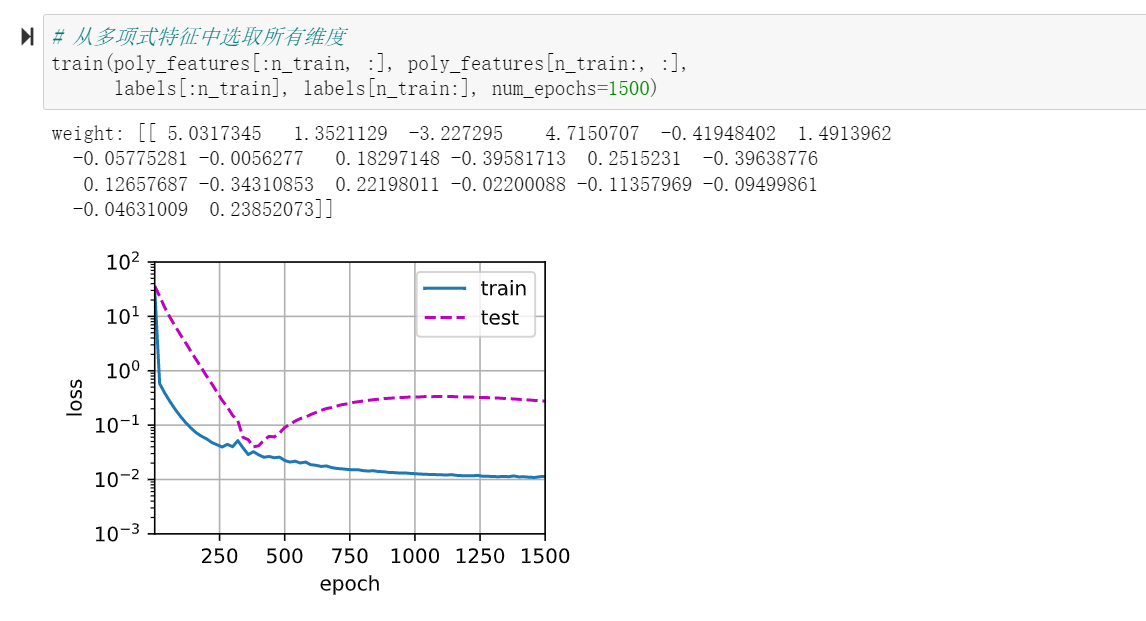
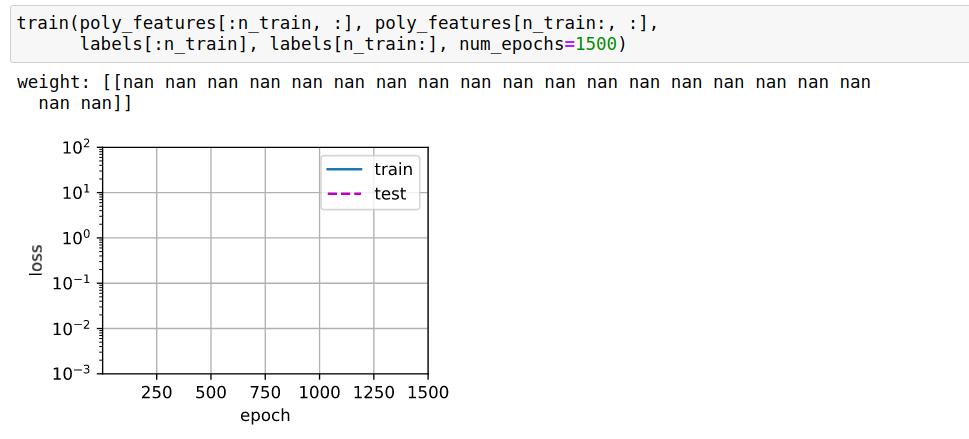
是的我的代码跑出来也是这个情况,不知道是什么原因
max_degree =20,都运行出来了,但是不是很理解这个变量的含义,请问有大佬可以帮忙解释一下吗?呜呜呜:)
为什么我按照书上的代码运行,正常 欠拟合 过拟合三个图像的test loss 和 train loss 都很接近
my answer to 模型复杂度与损失关系图
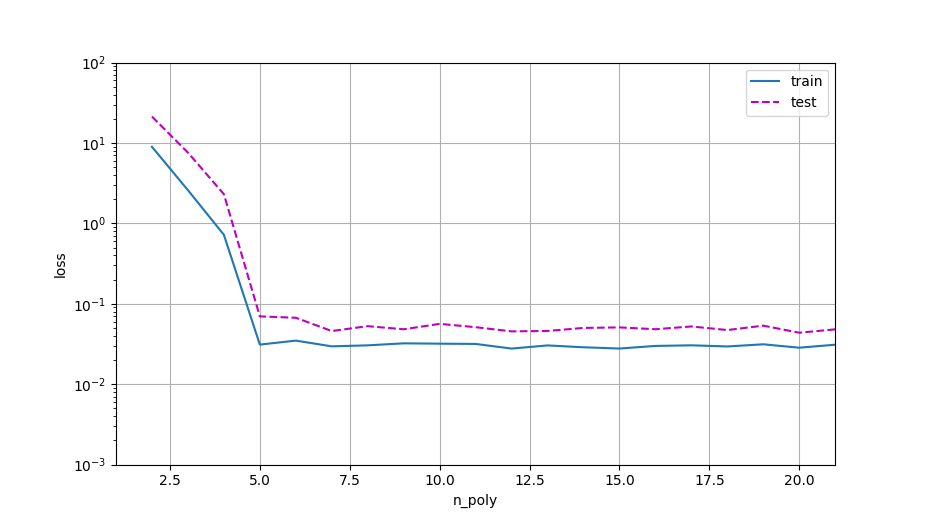
def train(train_features, test_features, train_labels, test_labels, num_epochs=400):
global trainloss
global testloss
loss = nn.MSELoss()
input_shape = train_features.shape[-1]
net = nn.Sequential(nn.Linear(input_shape, 1, bias=False))
batch_size = min(10, train_labels.shape[0])
train_iter = d2l.load_array((train_features, train_labels.reshape(-1,1)),
batch_size)
test_iter = d2l.load_array((test_features, test_labels.reshape(-1,1)),
batch_size, is_train=False)
trainer = torch.optim.SGD(net.parameters(), lr=0.01)
animator = d2l.Animator(xlabel=‘epoch’, ylabel=‘loss’, yscale=‘log’,
xlim=[1, num_epochs], ylim=[1e-3, 1e2],
legend=[‘train’, ‘test’])
for epoch in range(num_epochs):
d2l.train_epoch_ch3(net, train_iter, loss, trainer)
if epoch == 0 or (epoch + 1) % 20 == 0:
animator.add(epoch + 1, (evaluate_loss(net, train_iter, loss),
evaluate_loss(net, test_iter, loss)))
trainloss = evaluate_loss(net, train_iter, loss)
testloss = evaluate_loss(net,test_iter, loss)
print(‘weight:’, net[0].weight.data.numpy())
print(‘trainloss:’, trainloss)
print(‘testloss:’, testloss)
return(trainloss , testloss)
jieshu=np.arange(1, 21, 1)
print(jieshu)
animator = d2l.Animator(xlabel=‘n_poly’, ylabel=‘loss’, yscale=‘log’,
xlim=[1, 21], ylim=[1e-3, 1e2],
legend=[‘train’, ‘test’])
for i in jieshu:
train(poly_features[:n_train, : i], poly_features[n_train:, :i],
labels[:n_train], labels[n_train:])
animator.add(i+1, (trainloss, testloss))
plt.show()