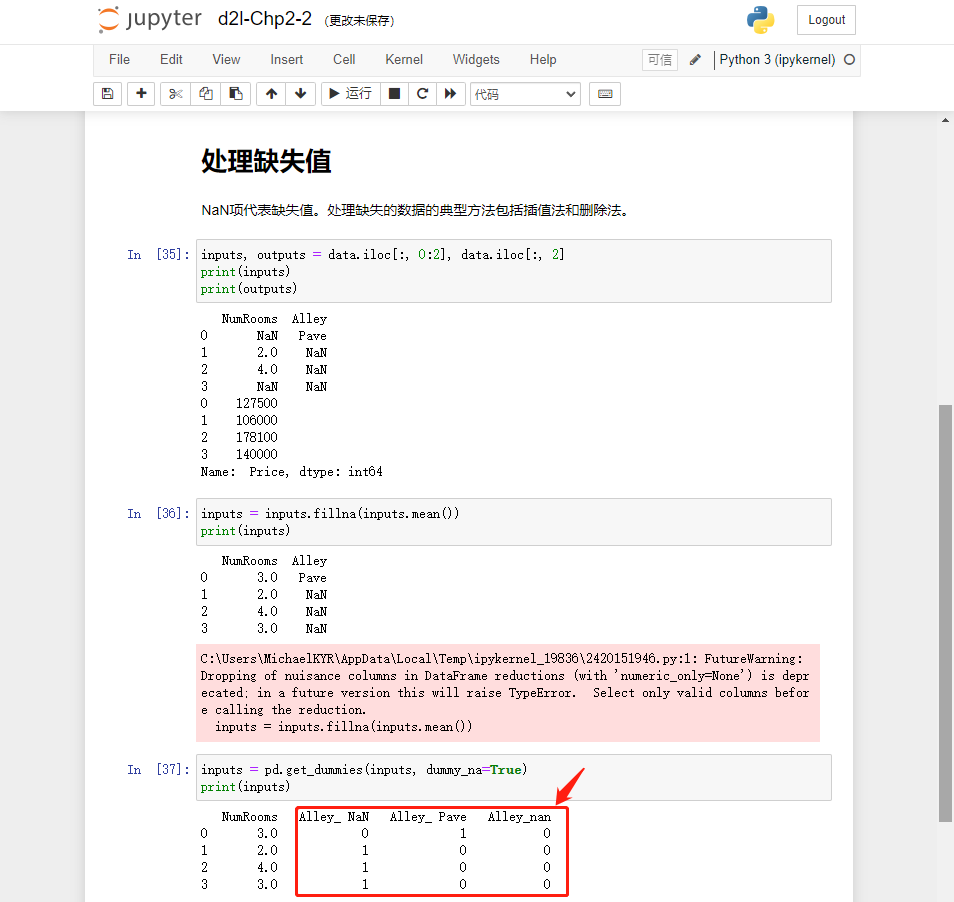
TypeError Traceback (most recent call last)
Cell In[109], line 2
1 inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
----> 2 inputs = inputs.fillna(inputs.mean())
3 print(inputs)
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\generic.py:11556, in NDFrame._add_numeric_operations..mean(self, axis, skipna, numeric_only, **kwargs)
11539 @doc(
11540 _num_doc,
11541 desc=“Return the mean of the values over the requested axis.”,
(…)
11554 **kwargs,
11555 ):
11556 return NDFrame.mean(self, axis, skipna, numeric_only, **kwargs)
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\generic.py:11201, in NDFrame.mean(self, axis, skipna, numeric_only, **kwargs)
11194 def mean(
11195 self,
11196 axis: Axis | None = 0,
(…)
11199 **kwargs,
11200 ) → Series | float:
11201 return self._stat_function(
11202 “mean”, nanops.nanmean, axis, skipna, numeric_only, **kwargs
11203 )
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\generic.py:11158, in NDFrame._stat_function(self, name, func, axis, skipna, numeric_only, **kwargs)
11154 nv.validate_stat_func((), kwargs, fname=name)
11156 validate_bool_kwarg(skipna, “skipna”, none_allowed=False)
11158 return self._reduce(
11159 func, name=name, axis=axis, skipna=skipna, numeric_only=numeric_only
11160 )
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\frame.py:10519, in DataFrame._reduce(self, op, name, axis, skipna, numeric_only, filter_type, **kwds)
10515 df = df.T
10517 # After possibly _get_data and transposing, we are now in the
10518 # simple case where we can use BlockManager.reduce
10519 res = df._mgr.reduce(blk_func)
10520 out = df._constructor(res).iloc[0]
10521 if out_dtype is not None:
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\internals\managers.py:1534, in BlockManager.reduce(self, func)
1532 res_blocks: list[Block] =
1533 for blk in self.blocks:
→ 1534 nbs = blk.reduce(func)
1535 res_blocks.extend(nbs)
1537 index = Index([None]) # placeholder
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\internals\blocks.py:339, in Block.reduce(self, func)
333 @final
334 def reduce(self, func) → list[Block]:
335 # We will apply the function and reshape the result into a single-row
336 # Block with the same mgr_locs; squeezing will be done at a higher level
337 assert self.ndim == 2
→ 339 result = func(self.values)
341 if self.values.ndim == 1:
342 # TODO(EA2D): special case not needed with 2D EAs
343 res_values = np.array([[result]])
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\frame.py:10482, in DataFrame._reduce..blk_func(values, axis)
10480 return values._reduce(name, skipna=skipna, **kwds)
10481 else:
10482 return op(values, axis=axis, skipna=skipna, **kwds)
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\nanops.py:96, in disallow.call.._f(*args, **kwargs)
94 try:
95 with np.errstate(invalid=“ignore”):
—> 96 return f(*args, **kwargs)
97 except ValueError as e:
98 # we want to transform an object array
99 # ValueError message to the more typical TypeError
100 # e.g. this is normally a disallowed function on
101 # object arrays that contain strings
102 if is_object_dtype(args[0]):
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\nanops.py:158, in bottleneck_switch.call..f(values, axis, skipna, **kwds)
156 result = alt(values, axis=axis, skipna=skipna, **kwds)
157 else:
→ 158 result = alt(values, axis=axis, skipna=skipna, **kwds)
160 return result
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\nanops.py:421, in _datetimelike_compat..new_func(values, axis, skipna, mask, **kwargs)
418 if datetimelike and mask is None:
419 mask = isna(values)
→ 421 result = func(values, axis=axis, skipna=skipna, mask=mask, **kwargs)
423 if datetimelike:
424 result = _wrap_results(result, orig_values.dtype, fill_value=iNaT)
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\nanops.py:727, in nanmean(values, axis, skipna, mask)
724 dtype_count = dtype
726 count = _get_counts(values.shape, mask, axis, dtype=dtype_count)
→ 727 the_sum = _ensure_numeric(values.sum(axis, dtype=dtype_sum))
729 if axis is not None and getattr(the_sum, “ndim”, False):
730 count = cast(np.ndarray, count)
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\numpy\core_methods.py:49, in _sum(a, axis, dtype, out, keepdims, initial, where)
47 def _sum(a, axis=None, dtype=None, out=None, keepdims=False,
48 initial=_NoValue, where=True):
—> 49 return umr_sum(a, axis, dtype, out, keepdims, initial, where)
TypeError: can only concatenate str (not “int”) to str
按照案例写的,报错,如何解决呢???