2.2.2 处理缺失值一节中,<< 由于 “巷子”(“Alley”)列只接受两种类型的类别值 “Alley” 和 “NaN” >> 应该改为 << 由于 “巷子”(“Alley”)列只接受两种类型的类别值 “Pave” 和 “NaN”>>
在2.2.1 pirnt的结果里自动给四组数据标了号, 请问 read_csv 是如何区分 列名 和 列名之下的数据 的呢?
交作业啦,问题一:
def drop_col():
n = len(data)
i = 0
for col_name in(‘NumRooms’,‘Alley’,‘Price’):
cnt = data[col_name].count()
if (n-cnt) > i :
i = (n-cnt)
j = col_name
data.drop(j,axis=1,inplace=True)
drop_col()
data
小白入门,写的可能很复杂,请路过的朋友们多多指导。
边查边做…不知道思路对不对 
def drop_col(m):
num = m.isna().sum() #获得缺失值统计信息
num_dict = num.to_dict() #转为字典
max_key =max(num_dict,key=num_dict.get) #取字典中最大值的键
del m[max_key] #删除缺失值最多的列
return m
drop_col(data)
请问一下,如果数据中有中文,为什么输出一下会乱码
with open(data_file1, ‘w’)as f: #open文件名参数不要打引号
f.write(‘动物,年龄,特点\n’)
f.write(‘马,4,跑的快\n’)
f.write(‘猪,5,喜欢吃\n’)
f.write(‘羊,NA,NA\n’)
f.write(‘鸡,NA,会下蛋\n’)
f.write(‘牛,3,会吃草\n’)
f.write(‘NA,NA,NA\n’)
data = pd.read_csv(data_file1)
data
pb1
number = []
names = [‘NumRooms’,‘Alley’,‘Price’]
for name in names:
a = np.sum(data[name].isnull())
number.append(a)
data = data.drop(names[np.argmax(number)],axis = 1)
data
count = 0
count_max = 0
labels = ['NumRooms','Alley','Price']
for label in labels:
count = data[label].isna().sum()
if count > count_max:
count_max = count
flag = label
data_new = data.drop(flag,axis=1)
data_new
把这个open(data_file1, ‘w’)改成open(data_file1, ‘w’,encoding=‘utf8’)
因为中文需要采用utf-8编码
x=df.isna().sum()
dfs=df.drop(columns=x.index[x.argmax()])
names = list(inputs)
max_nan = inputs.isnull().sum().max()
drop_i = []
for n in names:
if inputs[n].isnull().sum() == max_nan:
inputs_drop = inputs.drop(columns=n)
inputs_drop
maxnanum=0
for i in inputs.columns:
if maxnanum<inputs[i].isnull().sum():
maxnanum = inputs[i].isnull().sum()
inputs=inputs.dropna(1,‘any’,thresh=inputs.shape[0]-maxnanum+1)
max_nan=[]
for i,row in data.iteritems():
max_nan.append(row.isna().sum())
del data[data.columns[max_nan.index(max(max_nan))]]
请问大家直到这是怎么回事吗?
df_count = data.isna().sum()
label = df_count.idxmax()
new_data = data.drop(label, 1)
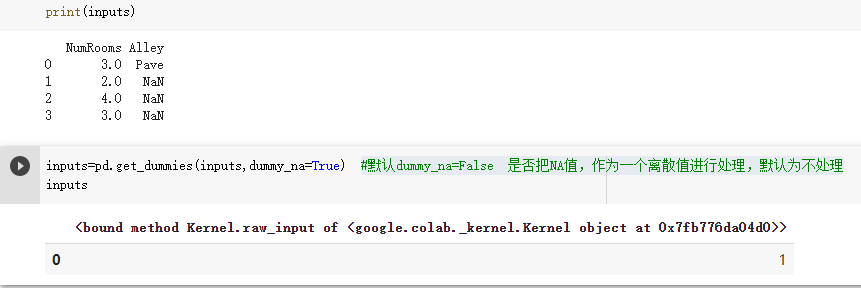
你漏了给get_dummies指定dummy_na=True了
第一题我写的答案,大家一起来玩呀。
data1 = pd.read_csv(data_file)
知道每列的nan数
nan_numer = data1.isnull().sum(axis=0)
找到nan_numer(series)中最大数的索引
nan_max_id = nan_numer.idxmax()
删除nan最大的列
data1 = data1.drop([nan_max_id], axis=1)
data1
小白交作业
- 2021.8.25
def drop_max_nan_col(data):
nanmaxid = data.isna().sum(axis = 0).idxmax()
ndata = data
ndata = ndata.drop(nanmaxid, axis = 1)
inputs, output = ndata.iloc[:,0:-1], ndata.iloc[:,-1]
inputs = inputs.fillna(inputs.mean())
inputs = pd.get_dummies(inputs, dummy_na = True)
X, y = torch.tensor(inputs.values), torch.tensor(output.values)
return X, y