是的,如果想避免这个情况,把NA前面的空格删掉就可以了
1 Like
泪目了 感谢好兄弟 折腾了一个多小时 终于解决了 感谢兄弟
![]()
感谢兄弟提问 我也有同样的问题 感谢汤姆猫老兄的解答!
非常感谢兄弟 dtype=int 以及dummy_na 不加** 也可 另外int换成float也行 ![]()
问题一:
删除列缺值最多的列
data.drop(data.isnull().sum().idxmax(),axis=1)
删除缺值最多的行
data.drop(data.isnull().sum(axis=1).idmax(),axis=0)
问题二:
data = torch.tensor(data.to_numpy(dtype=float))
当csv文件中有中文时,data = pd.read_csv(data_file)会发生’utf-8’ codec can’t decode byte 0xb2 in position 21: invalid start byte的错误
解决方法:加上encoding=‘GB2312’,也就是data = pd.read_csv(data_file,encoding=‘GB2312’)
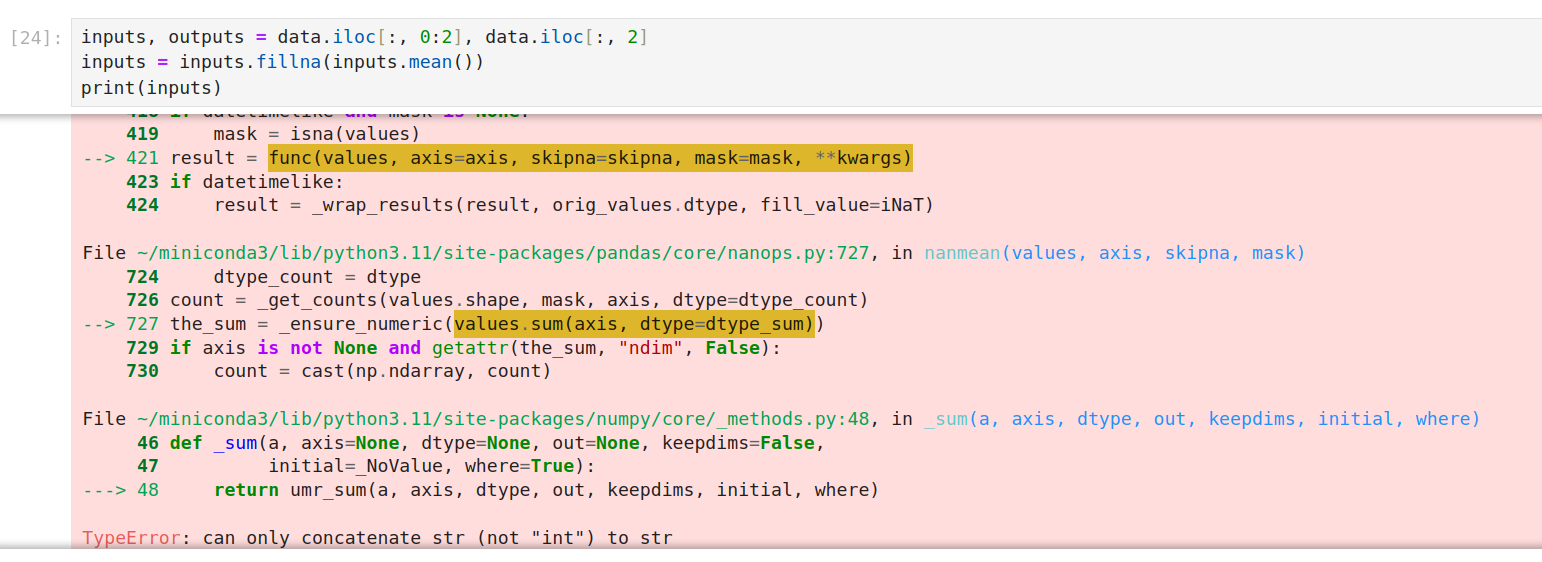
inputs.mean() 更改为 inputs.mean(numeric_only=True)
表示仅处理数字部分,否则程序异常
删除缺失最多的一列最简洁答案
import pandas as pd
创建一个包含缺失值的 DataFrame
df = pd.DataFrame({
‘A’: [1, 2, None, 4],
‘B’: [None, 2, 3, None],
‘C’: [1, None, None, None]
})
print(df)
计算每列的缺失值数量
missing_counts = df.isnull().sum()
找到缺失值最多的列的名称
column_to_drop = missing_counts.idxmax()
删除该列
df = df.drop(columns=column_to_drop)
print(df)
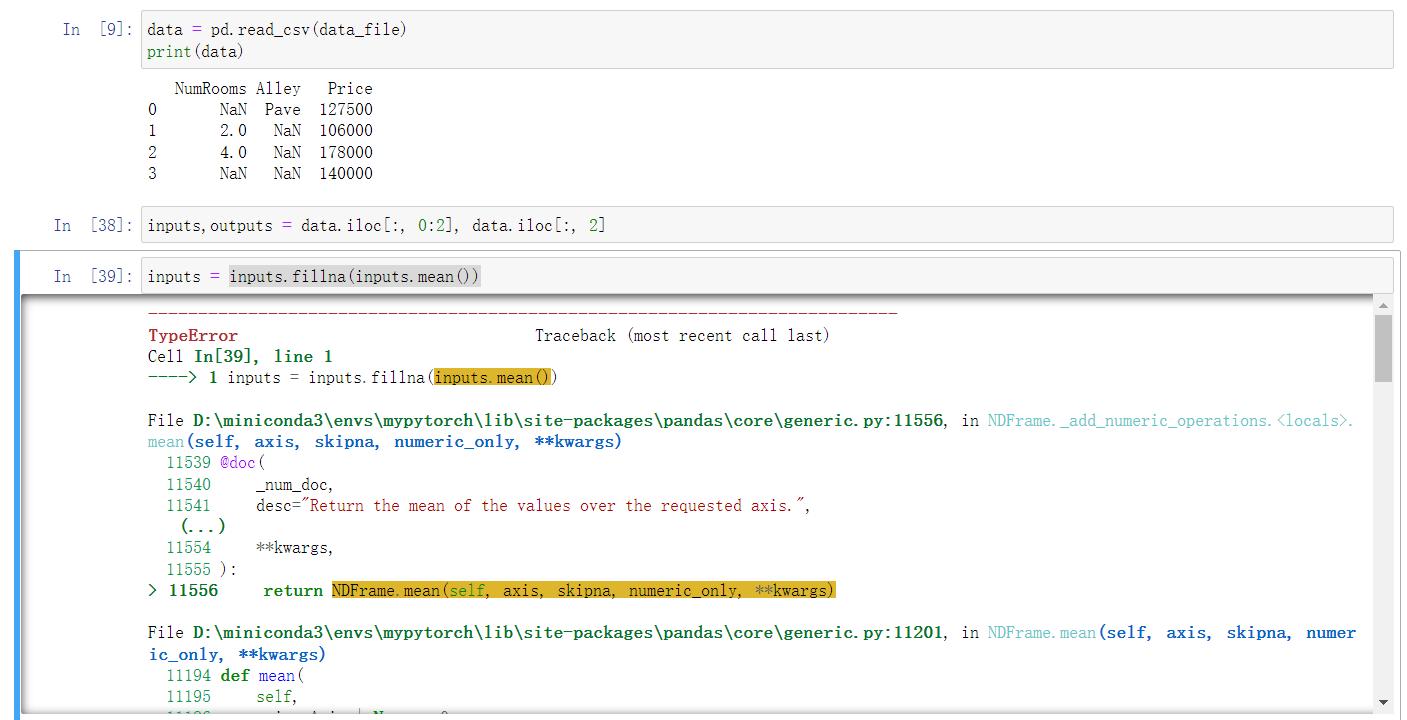
看报错原因,can only concatenate str (not “int”) to str
解决这个问题的方法很简单,在括号加入限制条件,仅在数据类型为数值的列进行平均值插值。
也就是改成:inputs = inputs.fillna(inputs.mean(numeric_only=True))
1 Like
topic 1
data.drop(data.isna().sum().idxmax(), axis=1)
topic 2
torch.tensor(inputs.to_numpy(dtype=float))
多谢大佬,我知道可能是pandas升级了所以mean方法不再默认忽略字符串,但是不知道怎么处理。
多谢大佬指点。
交个作业!:
import numpy as np
def drop_max_columns(col):
col_null = col.isnull().sum(axis=0)
Index_max = np.argmax(np.array(col_null))
Index = col.columns[Index_max]
inputs1 = col.drop(Index, axis=1)
return inputs1
New_inputs = drop_max_columns(inputs)
print(New_inputs)
import random
os.makedirs(os.path.join("..","house"),exist_ok=True)
data_file = os.path.join("..","house/sample_data.csv")
import random
# 打开数据文件,使用 'w' 模式以便写入数据
data_file = os.path.join("..",data_file)
with open(data_file, 'w') as f:
# 写入列名
f.write('NumRooms,Alley,Price\n')
# 生成随机样本数据
for _ in range(100): # 生成100个样本
num_rooms = random.randint(1, 10) # 随机生成1到10之间的房间数量
alley = random.choice(['Pave', 'Gravel', 'NA']) # 随机选择巷道类型
price = random.randint(50000, 300000) # 随机生成价格
# 添加逻辑以生成缺失值
if random.random() < 0.2: # 20% 的概率生成缺失值
num_rooms = 'NA'
if random.random() < 0.2:
alley = 'NA'
# 写入数据行
f.write(f'{num_rooms},{alley},{price}\n')
print(f'生成的随机样本数据已保存到 {data_file}')
sample_data = pd.read_csv(data_file)
sample_data
max_nan_count= -1
man_nan_column = ''
for index, row in sample_data_nan.iteritems():
if row>max_nan_count:
max_nan_count = row
max_nan_column = index
sample_data_drop_most_nan = sample_data.drop(max_nan_column,axis=1)
import numpy as np
my_array = np.array(sample_data_drop_most_nan)
my_tensor = torch.tensor(my_array)
my_tensor做数据预处理的时候,出现了这个错误,有人知道该怎么解决嘛
具体的错误信息如下::2: FutureWarning: The default value of numeric_only in DataFrame.mean is deprecated. In a future version, it will default to False. In addition, specifying ‘numeric_only=None’ is deprecated. Select only valid columns or specify the value of numeric_only to silence this warning.
inputs = inputs.fillna(inputs.mean())
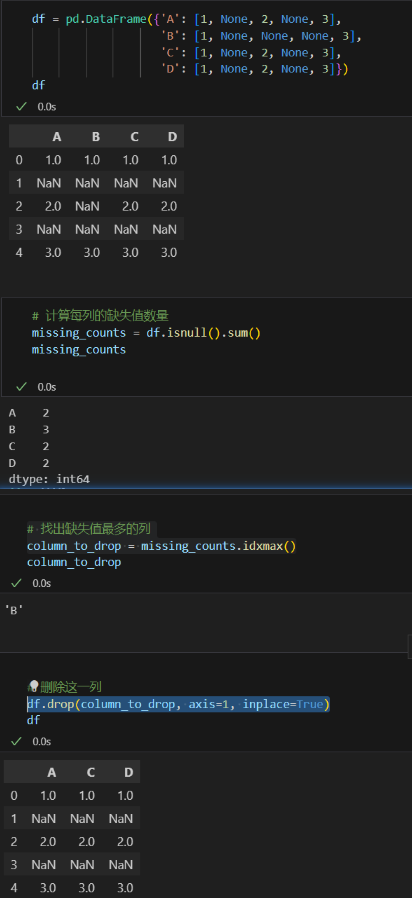
建了一个新表完成作业1,2
data_file = os.path.join(‘…’, ‘data’, ‘house_tiny2.csv’)
data = pd.read_csv(data_file)
inputs, outputs = data.iloc[:, 0:3], data.iloc[:, 3]
sum1 = inputs.isna().sum()
index = 0
for i in range(sum1.size):
if sum1[i] > sum1[index]:
index = i
inputs = inputs.drop(list(inputs)[index],axis=1 ,inplace=False)
inputs.fillna(0, inplace=True)
inputs_torch = torch.tensor(inputs.to_numpy(dtype=float))
inputs_torch
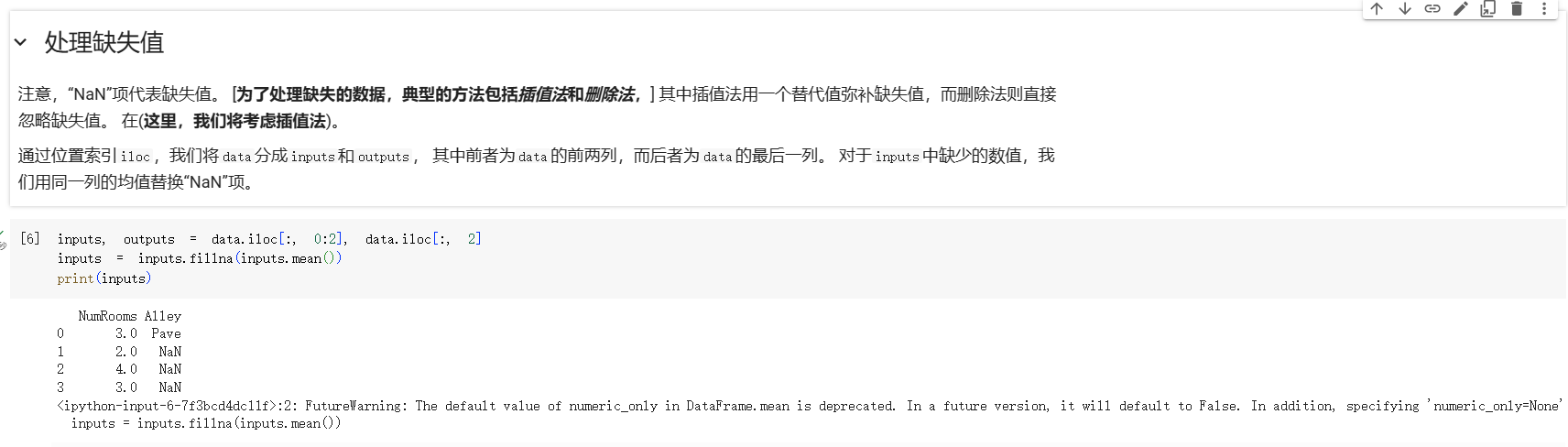
高版本pandas的numeric_only参数需要指定参数值,否则默认是False,例子:inputs = inputs.fillna(inputs.mean(numeric_only=True))
1 Like
Thanks so much!!!