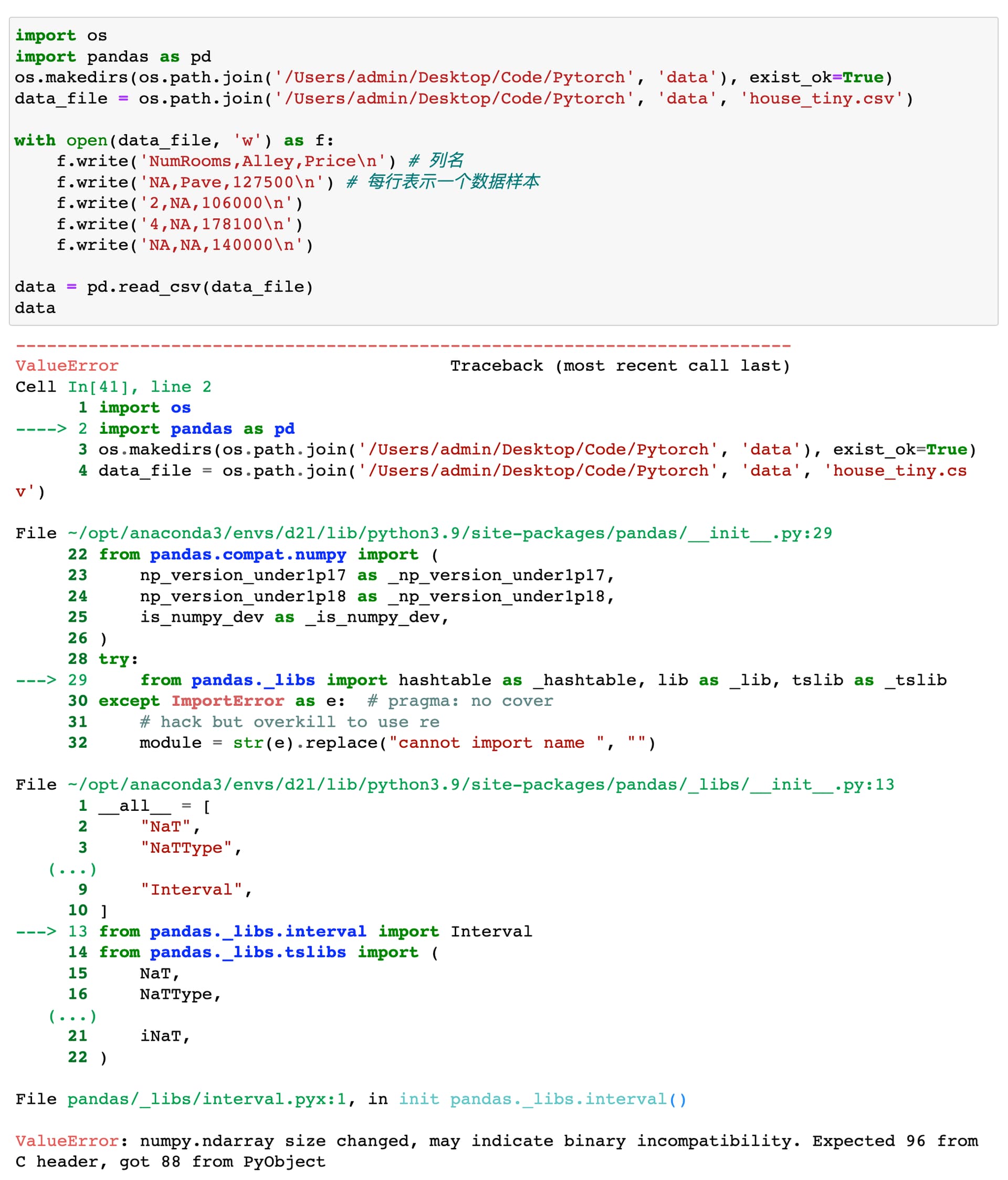
我按照书上的代码运行结果报错,numpy版本是1.21.5,pandas版本是1.2.4,有大佬给我解答下吗?
inputs = data.iloc[:,:-1]
col_name = inputs.isna().sum().idxmax()
inputs = inputs.drop(columns=col_name)
torch.tensor(inputs.values)
def drop_col(data):
lst = ['NumRooms', 'Alley', 'Price']
count = 0
max_count = 0
max_col_name = ''
for col_name in lst:
count = data[col_name].isnull().sum() # 对应每一列中 nan 的数量
if count > max_count:
max_count = count
max_col_name = col_name
print(max_col_name)
data.drop(max_col_name, axis=1, inplace=True)
print(data)
if __name__ == "__main__":
data = pd.read_csv(data_file)
drop_col(data)
参考了佬的代码,发现应修正为
inputs = inputs.dropna(axis=1, thresh=max(inputs.isna().sum()) )
我只是个新手,尝试看了别的文档写了出来
import numpy as np
import pandas as pd
import torch
data = [[3,'NAN','NAN','NAN'],[11,22,33,'NAN'],[44,55,'NAN','NAN']]
mult = pd.DataFrame(data)
#DataFrame是一个表格类型的数据结构
#把不同的列表(或者是pandas库里头的Seise并成一个表格
print(mult)
boolmult = mult.isnull()
#这里为了直观可以构建一个布尔类型的DataFrame
print(boolmult)
missing_value = ['NAN']
mult.to_csv('2.2work.csv')
df = pd.read_csv('2.2word.csv' , na_values = missing_value)
#缺省值标记我们的特有的标签
new_df = df.dropna(axis = 1 , thresh = df.isnull().sum().max() )
#thresh标签的意思是,达到多少个缺省值我们才删除这个列(行)
#axis = 0 是删除行 反之则是删除列
i = new_df.iloc[:,0:2]
o = new_df.iloc[:,2]
#用iloc方法取单独的列 i 取前两列,o取第三列
x = torch.tensor(i.values) , y = torch.tensor(o.values)
#最后转化为张量
我也是这个报错,试了很多方法都不行,请问一下你解决了吗
一行代码搞定:
data.drop(data.isna().sum().idxmax(),axis=1)
用到的参数名及意义:
drop(labels,axis),labels表示行列名,axis,0表示行,1表示列
data.isna().sum(),列值和,这里返回series对象,其中series中的值为每列的和
idxmax()返回series中值最大的标签名,也就是列名。
1 Like
是python版本的问题,我从3.10改3.9重新配置下环境解决了,可以试试
导包
import os
import pandas as pd
import torch
创建一个csv文件
os.makedirs(os.path.join("…",“data”),exist_ok= True)
data_file = os.path.join("…",“data”,“pandas_file.csv”)
with open(data_file,‘w’) as f:
f.write(‘A,B,C,D,Result\n’)
f.write(‘1,2,NA,NA,1\n’)
f.write(‘7,2,NA,P,1\n’)
f.write(‘3,9,3,P,1\n’)
f.write(‘2,9,NA,NA,1\n’)
读取文件
data = pd.read_csv(data_file)
定义一个删除最多空值的列函数
def deleteColumnMostNA(data):
max_index = max_count = -1
column = []
for i in range(data.shape[1]):
column.append(data.columns[i])
获取columns的信息
打印出data的column信息
for i in range(len(column)):
print(column[i])
计算出列的空信息的数量
for i in range(len(column)):
if data.isna().sum()[column[i]] > max_count:
max_index = i
max_count = data.isna().sum()[column[i]]
if max_index == -1:
return None
return data.drop(column[max_index],axis=1)
处理空值
data1 = deleteColumnMostNA(data)
inputs,outputs = data1.iloc[:,0:data1.shape[1]-1],data1.iloc[:,data1.shape[1]-1]
inputs = pd.get_dummies(inputs,dummy_na=True)
转化为tensor
X,y = torch.tensor(inputs.values),torch.tensor(outputs.values)
X,y
参考了佬们的代码
inputs = inputs.dropna(axis=1,thresh=max(inputs.isna().sum()) )
其中:
axis参数指定了要删除哪个维度上包含缺失值的行或列。当axis=0时表示按照行进行操作,即删除包含缺失值的整行;而当axis=1时表示按照列进行操作,即删除包含缺失值的整列。thresh参数是一个阈值,它用来控制最多允许有多少个缺失值。如果某一行或列中的缺失值数量超过了这个阈值,则该行或列会被删除。注意,这里的缺失值数量是指在该行或列中有多少个缺失值,而不是在整个数据框中有多少个缺失值。
inputs.isna()是 Pandas 数据框的一个方法,用来检查数据框中的每个元素是否为缺失值(NaN)。
inputs.isna().sum() 将返回一个新的数据框,其中包含了 inputs 数据框中每一列中缺失值的数量。具体而言,它的作用是:
- 对
inputs调用isna()方法,得到一个布尔型的数据框,其中每个元素表示该位置上是否为缺失值。 - 对该数据框调用
sum()方法,对每一列求和,得到一个新的数据框,其中每一列的值表示原数据框中该列中缺失值的数量。
1 Like
删除缺失值最多的列
import pandas as pd
data = pd.read_csv(data_file)
nan_count = data.isna().sum()
#利用pandas的dataFrame的bool索引,提取对应的行名称,即Alley,并删除该列,即anxis=1
print(data)
data.drop(nan_count[nan_count == max(nan_count)].index, axis=1, inplace=True)
print(data)
def read_my_data_mode(rand_line_count):
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('index,number,asc,value') # 列名
for i in range(rand_line_count):
f.write("\n"
+ str('NaN' if 0 == random.randint(1, 1000) % 2 else torch.randn(1, 1).item())
+ str(",NaN" if 0 == random.randint(1, 1000) % 2 else ",wr" + random.randint(48, 97).__str__())
+ str(",NaN" if 0 == random.randint(1, 1000) % 2 else ",bn" + random.randint(48, 97).__str__())
+ f",{torch.randn(1, 1).item() * 1000}"
)
print(os.path.abspath(data_file))
def work(filename):
"""
:param filename 文件地址
"""
# todo 删除缺失值最多的列。
data = pd.read_csv(filename)
print(data)
print()
# 查找每列中的 NaN 值数量
nan_counts = pd.isna(data).sum()
# 找出 NaN 值最多的列
max_nan_col = nan_counts.idxmax()
# 删除方法
data.drop(max_nan_col, axis=1, inplace=True)
print(data)
# todo 将预处理后的数据集转换为张量格式。
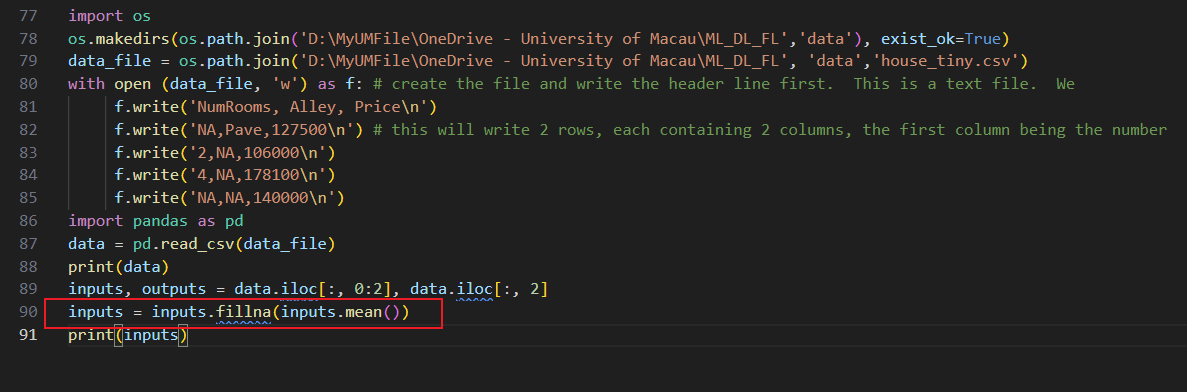
inputs, outputs = data.iloc[:, :2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean())
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)
x, y = torch.tensor(inputs.values), torch.tensor(outputs.values)
print(x)
print()
print(y)
if __name__ == '__main__':
# print(random.randint(1, 1000))
# read_my_data_mode(rand_line_count=8)
# read_csv(filename='/root/deep-learning/ai/pytorch/data/house_tiny.csv')
work(filename='/root/deep-learning/ai/pytorch/data/house_tiny.csv')
输出结果
# 原来的数据
index number asc value
0 NaN NaN bn93 1539.116383
1 -0.156952 wr55 NaN 74.826859
2 NaN NaN bn88 -1456.990361
3 NaN NaN bn97 -1305.474758
4 0.208486 wr77 NaN 420.621276
5 -0.885964 NaN NaN 513.052404
6 -0.018206 wr85 NaN -660.427392
7 NaN NaN NaN 571.750224
# 删除后的数据
index asc value
0 NaN bn93 1539.116383
1 -0.156952 NaN 74.826859
2 NaN bn88 -1456.990361
3 NaN bn97 -1305.474758
4 0.208486 NaN 420.621276
5 -0.885964 NaN 513.052404
6 -0.018206 NaN -660.427392
7 NaN NaN 571.750224
# 处理缺失值
index asc_bn88 asc_bn93 asc_bn97 asc_nan
0 -0.213159 0 1 0 0
1 -0.156952 0 0 0 1
2 -0.213159 1 0 0 0
3 -0.213159 0 0 1 0
4 0.208486 0 0 0 1
5 -0.885964 0 0 0 1
6 -0.018206 0 0 0 1
7 -0.213159 0 0 0 1
# 转换为张量格式
# 输出x
tensor([[-0.2132, 0.0000, 1.0000, 0.0000, 0.0000],
[-0.1570, 0.0000, 0.0000, 0.0000, 1.0000],
[-0.2132, 1.0000, 0.0000, 0.0000, 0.0000],
[-0.2132, 0.0000, 0.0000, 1.0000, 0.0000],
[ 0.2085, 0.0000, 0.0000, 0.0000, 1.0000],
[-0.8860, 0.0000, 0.0000, 0.0000, 1.0000],
[-0.0182, 0.0000, 0.0000, 0.0000, 1.0000],
[-0.2132, 0.0000, 0.0000, 0.0000, 1.0000]], dtype=torch.float64)
# 输出y
tensor([ 1539.1164, 74.8269, -1456.9904, -1305.4748, 420.6213, 513.0524,
-660.4274, 571.7502], dtype=torch.float64)
你的 pandas 可能是今年四月份刚发布的 2.0 版本,API 有一些细微的变化。调用 inputs.mean() 的时候会出现字符串和数字不能拼接的错误是因为 NaN 是数字,‘Pave’ 是字符串。解决方案:添加额外参数 inputs.mean(numeric_only=True),从而忽略对于字符串的处理。
15 Likes
谢谢,翻到这里解决了我的一个问题。 ![]()
![]()
![]()
![]()
1 Like
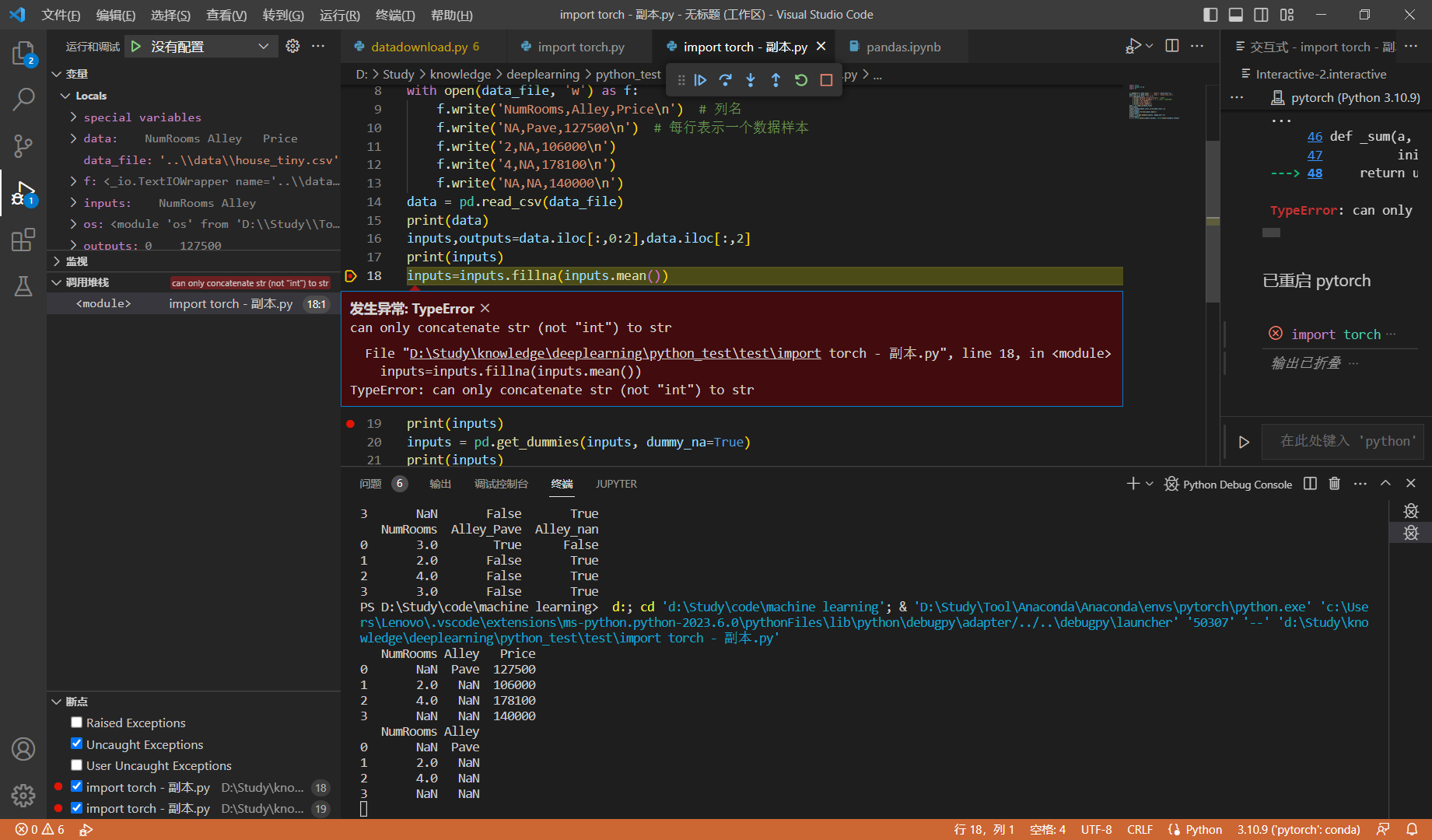
inputs = inputs.fillna(inputs.mean())
亲爱的作者,我用python运行上面这一行代码之后,出现了 can only concatenate str (not “int“) to str的错误,我上网搜了一下,发现列表有一个字符串Pave导致无法求平均值,所以我认为这个得改成以下代码:
inputs = inputs.fillna(inputs.select_dtypes(include=‘number’).mean())
这样我认为可能会更不错。 @goldpiggy
6 Likes
inputs, outputs = data.iloc[:, 0:3], data.iloc[:, 3]
missing_values_count = data.isnull().sum()
max_missing_col = missing_values_count.idxmax()
print(missing_values_count)
print(max_missing_col)
df = data.drop(max_missing_col, axis=1)
print(df)
import torch
X, y = torch.tensor(df.iloc[:, 0:3].values),torch.tensor(outputs.values)
X, y
交作业啦!
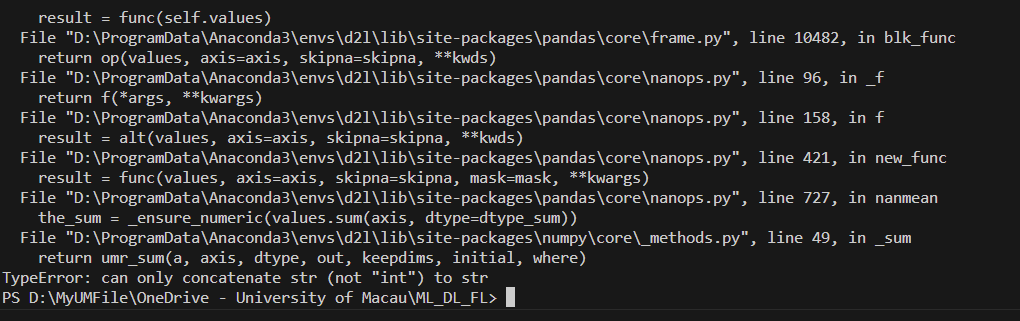
You helps me a lot! Thanks!