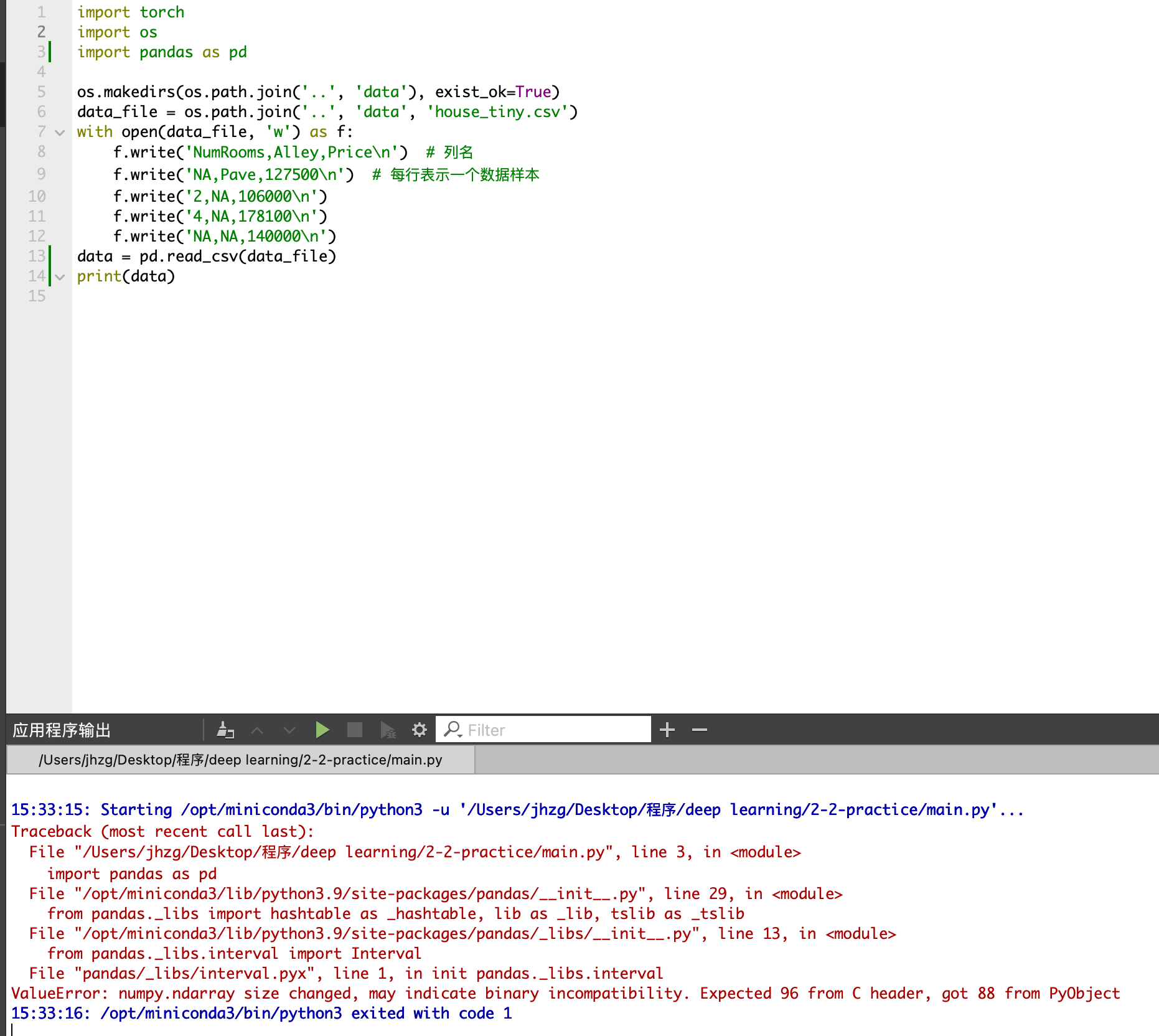
data.drop(columns=data.columns[data.isna().sum(axis=0).argmax()])

在dummy那一行需要
inputs = pd.get_dummies(inputs,dummy_na =True)
但是我看了下好像不能用replace=True
如果没有安装pandas,只需取消对以下行的注释来安装pandas
!pip install pandas
import pandas as pd
data = pd.read_csv(data_file)
print(data)
把文中的‘…’替换为你的路径,并且在前面加上‘r’,(拒绝字符转义)
os.makedirs(os.path.join(r’C:\Users\zhiyang_work\Downloads\d2l-zh\pytorch’, ‘data’), exist_ok=True)
data_file = os.path.join(r’C:\Users\zhiyang_work\Downloads\d2l-zh\pytorch’, ‘data’, ‘house_tiny.csv’)
1 Like
交作业
df=pd.read_csv(file)
indice=df.isnull().sum(axis=0)#获取最大缺省值的列名
df=df.drop(indice.idxmax(),axis=1)
print(df)
df=torch.tensor(df.values)
print(df)
1 Like
import numpy as np
num_na - data.isna().sum()
index = np.argmax(num_na)
data = data.drop(data.columns[index],axis=1)
# 创建数据
import numpy as np
X = torch.rand((10,10))
create_data = pd.DataFrame(X)
create_data
# 随机制造nan值
create_data[create_data>0.5] = torch.nan
# 取出列最多缺失值的
most_nan = np.argmax(np.sum(pd.isna(create_data), axis=0))
most_nan
# 列的删除
del create_data[most_nan]
# 转成张量
pd.get_dummies(create_data, dummy_na=True)
#删除null最多的列
data = data.drop(data.isna().sum().idxmax(),axis=1)
#用均值填补缺失值
data = data.fillna(data.mean())
#预处理之后转换成张量
x=torch.tensor(data.values)
2 Likes
自己边调试边写的
def Del_Col(indata:pd.DataFrame,if_return:bool=False):
col_name=['NumRooms','name','Alley','Price'] # I add a new column in it to test
count_max=0
tarcol=''
for col in col_name:
cnt=indata[col].isna().sum()
if cnt>count_max:
count_max = cnt
tarcol=col
pass
pass
if if_return:
indata.drop(columns=tarcol,inplace=True)
else:
return indata.drop(columns=tarcol)
count = data.isna().sum() #chinese-version 找到各列na的和
label = count.index[count.argmax()] #chinese-version 找到和最大的标签
data = data.drop(columns = label) #chinese-version 删除标签对应的列
data = data.fillna(data.mean()) #chinese-version 用均值代替NA
x = torch.tensor(data.values) #chinese-version 转化为张量
小白提问,axis=0的时候为啥会报错呢。
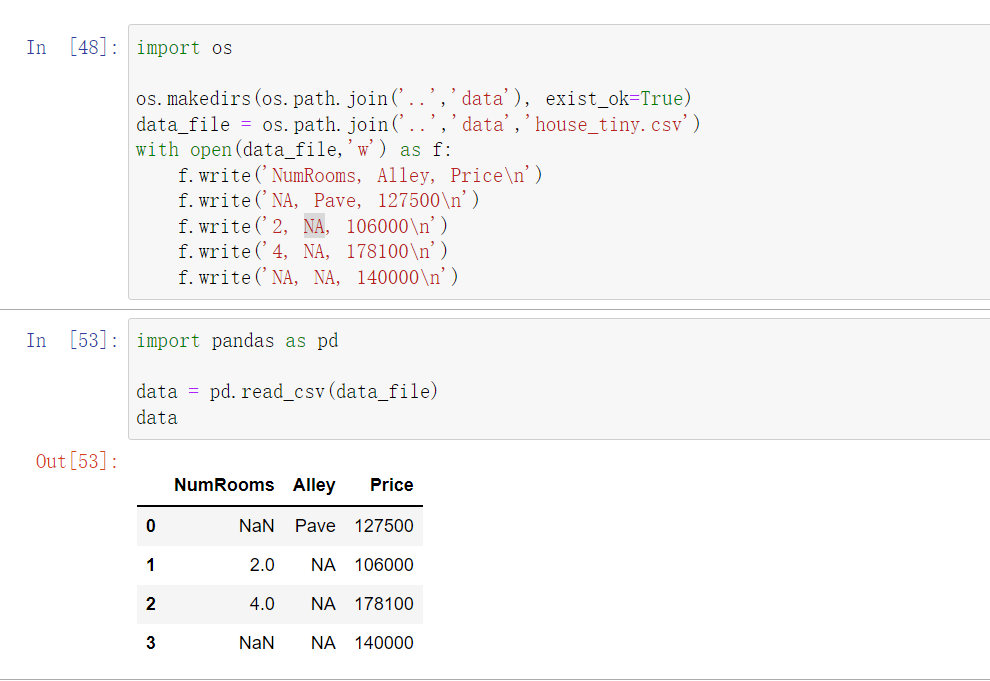
从报错来看,似乎你的excel文件里面没有内容,是空的
我在运行下面这句代码时用到了前一节交的节省内存的切片操作:
即将
inputs = pd.get_dummies(inputs, dummy_na = True)
改为
inputs[:] = pd.get_dummies(inputs, dummy_na = True)
然而输出时与示例输出不一致的情况,只有Alley,没有Alley_Pave 和 Alley_na了,如下图:
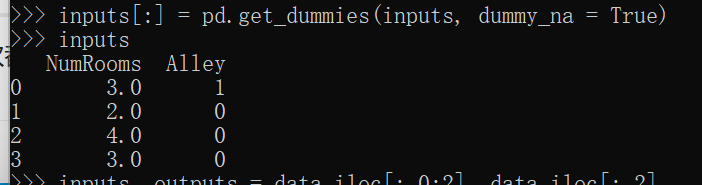
请问,有人知道这是为什么吗?
交作业。
import numpy as np
先统计每一列里面的na的数目
num_na = sum(inputs.isna().values)
找到na最多的一列的下标
max_index = np.argmax(num_na)
按照下标对应的列检索,丢掉此列
inputs = inputs.drop(inputs.columns[max_index], axis=1)
2 Likes
注意这样切片赋值不会更改原张量的维度,等号右边是 4 x 3, 而左边是 4 x 2,自然第三列无法赋值过去。列名也无法更改。
1 Like