一个语句即可解决👇
inputs = inputs.dropna(axis=1, thresh=(inputs.count().min()+1) )
14 Likes
count_nan = practices_data.isna().sum()
max_nan_col = count_nan.idxmax()
changed_data = practices_data.drop(max_nan_col,axis=1)
print(change_data)
print(practices_data)‘’’
cnt = 0
max_cnt = 0
for col_name in data.columns.values:
cnt = data[col_name].isna().sum()
if cnt > max_cnt:
max_cnt = cnt
maxNA_col_name = col_name
data_new = data.drop(maxNA_col_name,axis=1)
Blockquote
‘’’
data.isna()
cln = data.isna().sum().idxmax()
data.drop(columns = cln)
inputs, outputs = data.iloc[:,:-1],data.iloc[:,-1]
inputs = inputs.fillna(inputs.mean())
inputs = pd.get_dummies(inputs, dummy_na=True)
x, y = torch.tensor(inputs.values), torch.tensor(outputs.values)
x, y
若只有一个最大值时:
x.argmax() 或 x.idxmax()
可找到该最大值的索引,从而采取:
x=df.isna().sum()
df.drop(columns=x.index[x.argmax()]) 删除包含空值最多的列
但若包含多个相等的最大值时,x.argmax() 或 x.idxmax() 只能给出其中一个的索引,若想同时删除这些含空值相等的列,如何找出这些最大值的所有索引?
inputs.isnull().sum()返回每一列缺失值得个数。
inputs.isnull().sum().idxmax()得到缺失值最多的那一列的索引值。
Max_Nan_Num=inputs.isnull().sum().idxmax()
把缺失值最多的那一列删除
inputs=inputs.drop(Max_Nan_Num,axis=1)
4 Likes
def drop_col(df):
na_col_sum = df.isna().sum() #return a dataframe series of nan sum drop_col =
na_col_sum[na_col_sum.values==na_col_sum.max()].index #return the column's name with most NaNs
df = df.drop(columns=drop_col)
return df删除最多nan的列
def deleteMaxNa(data):
NaNums = data.isna().sum()
NaNums_dict = NaNums.to_dict()
max_key = max(zip(NaNums_dict.values(), NaNums_dict.keys()))[1]
data = data.drop([max_key],axis=1)
return data
print(data)
data1 = deleteMaxNa(data)
print(data1)
print(data)
- 删除缺失值最多的列。
- 将预处理后的数据集转换为张量格式。
data1 = os.path.join(‘…’,‘data’,‘prelimary.pandas.csv’)
with open(data1,‘w’) as f:
f.write(‘code,close,ceiling price,floor price,nothing\n’)
f.write(‘“600640”,10.85,11,10.8,5\n’)
f.write(‘“600241”,11.85,12,8,NA\n’)
f.write(‘“600984”,NA,11,8,89\n’)
f.write(‘“000365”,NA,11,10.8,NA\n’)
f.write(‘“000126”,10.85,8,10.8,NA\n’)
f.write(‘“000540”,10.85,11,0\n’)
mydata=pd.read_csv(data1)
def drop_mostNA(data):
min_ar=np.array()
for i in range(data.shape[1]):
dummy=pd.get_dummies(data.iloc[:,i],dummy_na=True)
min_ar=np.append(min_ar,sum(dummy.iloc[:,-1]))
index=np.argmax(min_ar)
return data.drop(data.columns[index],axis=1)
data_dropped=drop_mostNA(mydata)
data_dropped
inputs=data_dropped.iloc[:,:-1]
outputs=data_dropped.iloc[:,-1]
X,y=torch.tensor(inputs.values),torch.tensor(outputs.values)
X,y
sorry,I acn’t understand thedrop_i
inputs.drop(inputs.count().idxmax(), axis=1, inplace=True)
tensor = torch.tensor(inputs.values)
4 Likes
作业:
去掉最多na列:
na= stars.isna()
na_count= na.sum()
print(na)
print(na_count)
labelmax=na_count.argmax()
stars=stars.drop(stars.columns[labelmax],axis=1)
print(stars)
还瞎做了一个可视化寻找最多na的过程,没有啥卵用就是玩:
import numpy as np
stars = pd.read_csv(star_data_file)
list1=[]
for i in range(stars.shape[1]):
col=stars.iloc[:,i]
print(col)
k=0
for j in col:
if pd.isna(j):
k+=1
print("num of nan is ",k)
list1.append(k)
print(list1)交作业~
-
删除缺失值最多的列。
# data 是通过 pandas.read_csv() 读入的数据 data = data.drop(columns=data.isna().sum(axis=0).idxmax()) # axis=0表示缺失值最多的“列” -
将预处理后的数据集转换为张量格式。
inputs = torch.tensor(pd.get_dummies(data.iloc[:, 0:-1], dummy_na=True)) target = torch.tensor(data.iloc[:, -1])
5 Likes
小白来交作业了
问题一:
创建一个csv

找到缺失值最多的列:
df.isnull().sum().sort_values(ascending=False)
drop方法删除第2列:
data = df.drop(2,axis=1) # 默认drop的是行,需要指定axis才能删除列
del方法删除第2列:
del df[2]
问题二:
data = data.fillna(data.mean()) # 对缺失值用同一列的均值替换
tensor = torch.tensor(data.values)
1 Like
文档中提到:
可以使用 arange 创建一个行向量 x 。 这个行向量包含从0开始的前12个整数,它们被默认创建为浮点数
想跟大家讨论下,这句话是否有误?或者是由于我的知识不足,理解的不对,请大家指正
arange的默认应该为int64,
还有一个与之类似的函数为range,默认为浮点类型,如下图所示
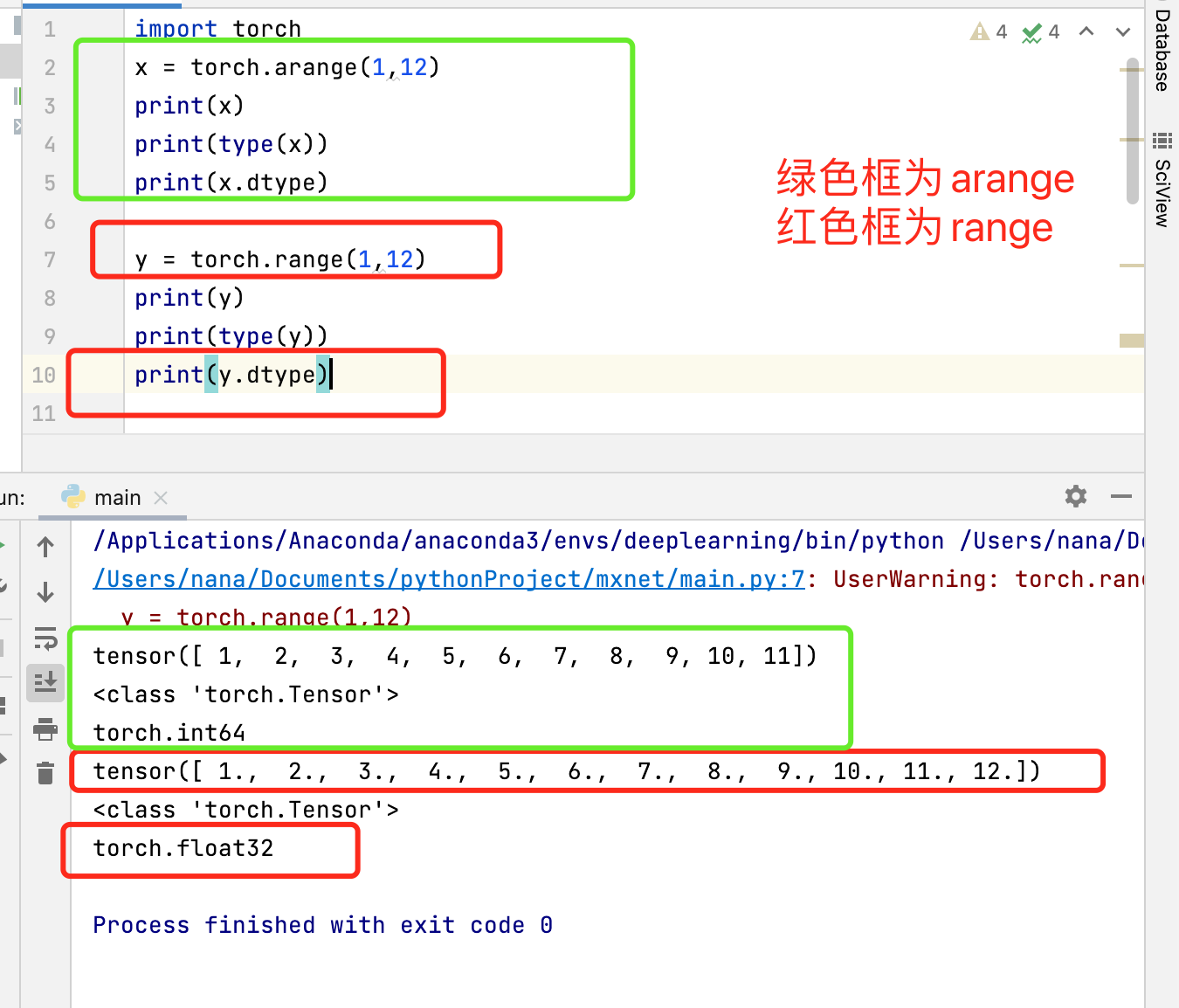
故:
arange和range的区别有以下两点:
arange不包括end,range包括;
arange的类型是int,range是float32
交作业
data.drop(data.isna().sum().idxmax(),1)
4 Likes
大佬语句简短优美,学习了 
该语句
data = pd.read_csv(data_file)
出现以下错误
pandas.errors.EmptyDataError: No columns to parse from file
找了很多方法无法解决,请问应该如何避免
1:
label = lose.isna().sum().idxmax() #获取目标列标签
new = lose.drop(label,axis=1) #删除列时取1
new
2:
重点是只留数值类型的值
第一步是用fillna()替换NA值
第二步是截取数值类型的值,用iloc[:, 1:3]
第三不 torch.tensor()
交作业啦~
创建包含更多行和列的原始数据集。
data_test_file = os.path.join(’…’, ‘data’, ‘house_tiny_test.csv’)
with open(data_test_file, ‘w’) as f:
f.write(‘NumRooms,Alley,Salary,Price\n’) # 列名
f.write(‘NA,Pave,4500,127500\n’) # 每行表示一个数据样本
f.write(‘2,NA,NA,106000\n’)
f.write(‘4,NA,8000,178100\n’)
f.write(‘NA,NA,6000,140000\n’)
f.write(‘5,NA,NA,110000\n’)
f.write(‘8,NA,7500,163000\n’)
f.write(‘NA,Pave,5000,125000\n’)
data_test = pd.read_csv(data_test_file)
print(data_test)
问题1:
from collections import defaultdict
cols_dict = defaultdict(int)
index_list = [‘NumRooms’,‘Alley’,‘Salary’,‘Price’]
for item in data_test.iterrows():
row = item[1]
for index in index_list:
temp = str(row[index])
if temp == ‘nan’: # 存在缺失值
cols_dict[index] += 1
对统计了缺失值的字典降序排序,获得缺失值最多的列
cols_dict = dict(sorted(cols_dict.items(), key=lambda x : x[1], reverse=True))
print(cols_dict.items())
删除缺失值最多的列
data_test = data_test.drop(‘Alley’,axis=1)
data_test
问题2:
处理缺失值
input_data, output_data = data_test.iloc[:, 0:2], data_test.iloc[:, 2]
input_data = input_data.fillna(input_data.mean())
print(input_data)
转换为张量格式
X, y = torch.tensor(input_data.values), torch.tensor(output_data.values)
X, y