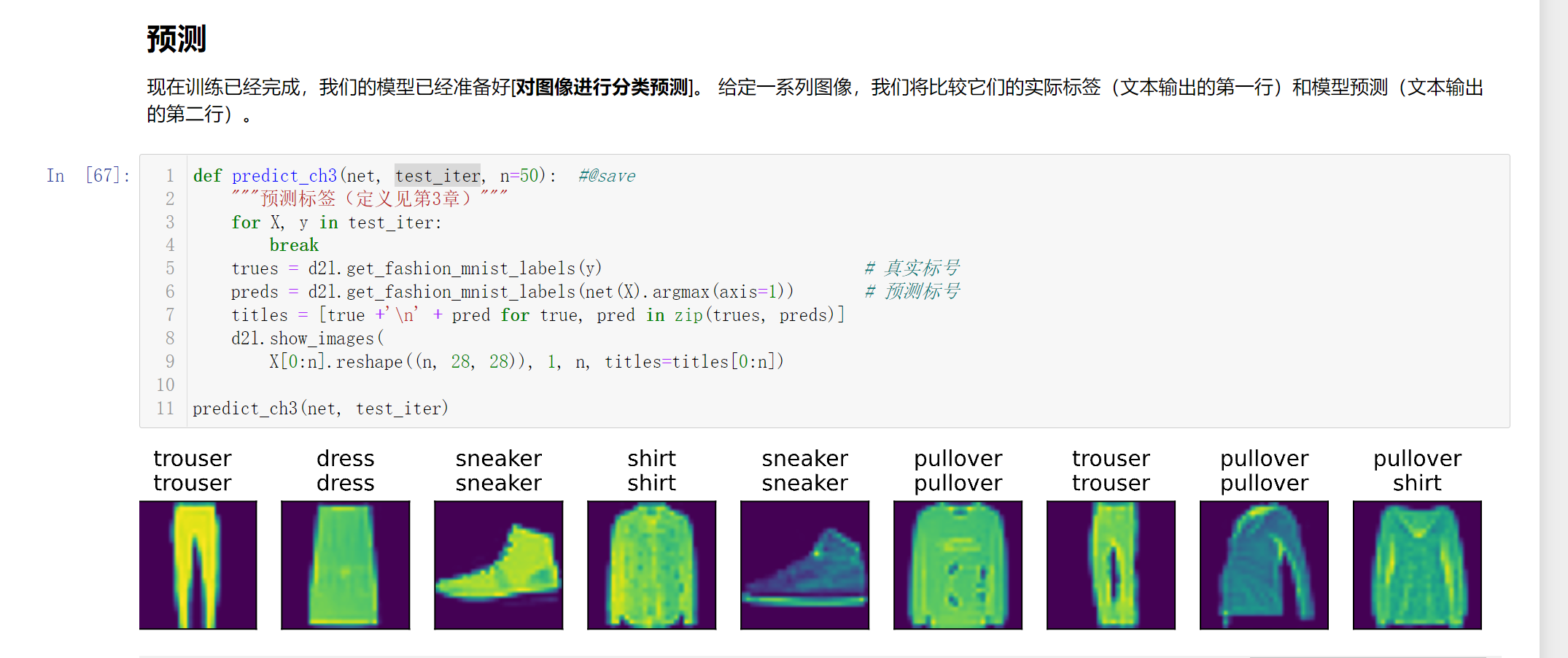
已解决!
在上一节图像分类数据集中,我们定义的函数load_data_fashion_mnist,并使用#@save保存到d2l中,其返回结果是data.DataLoader,其参数包括num_workers,设置为0后,再通过d2l调用发现并没有更新,所以干脆把定义函数用的代码重新写一下,就解决了!
找到这一行代码:
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
改为如下代码:
trans = [transforms.ToTensor()]
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root="…/data", train=True,
transform=trans, download=False)
mnist_test = torchvision.datasets.FashionMNIST(root="…/data", train=False,
transform=trans, download=False)
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=0)
test_iter = data.DataLoader(mnist_test, batch_size, shuffle=False, num_workers=0)
注意其中的root和download项根据自己情况来设置。
如果有更好的办法,希望大家来交流。
找到此文件…\Anaconda\Lib\site-packages\d2l\torch.py
编辑其中的def get_dataloader_workers():
改为return 0
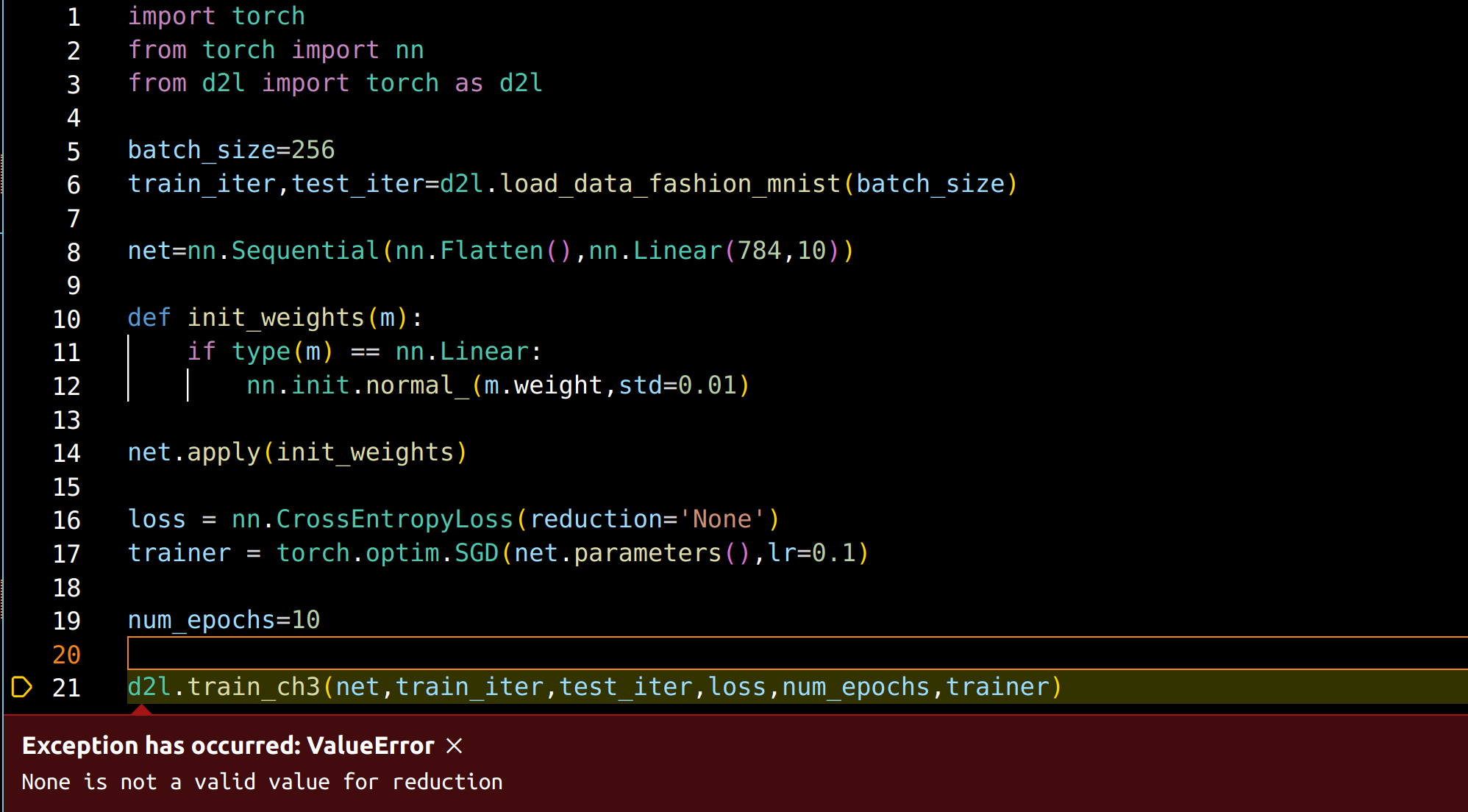
I come across the Exception:
Exception has occurred: ValueError
None is not a valid value for reduction
when I run the code in VScode, how to deal with it?

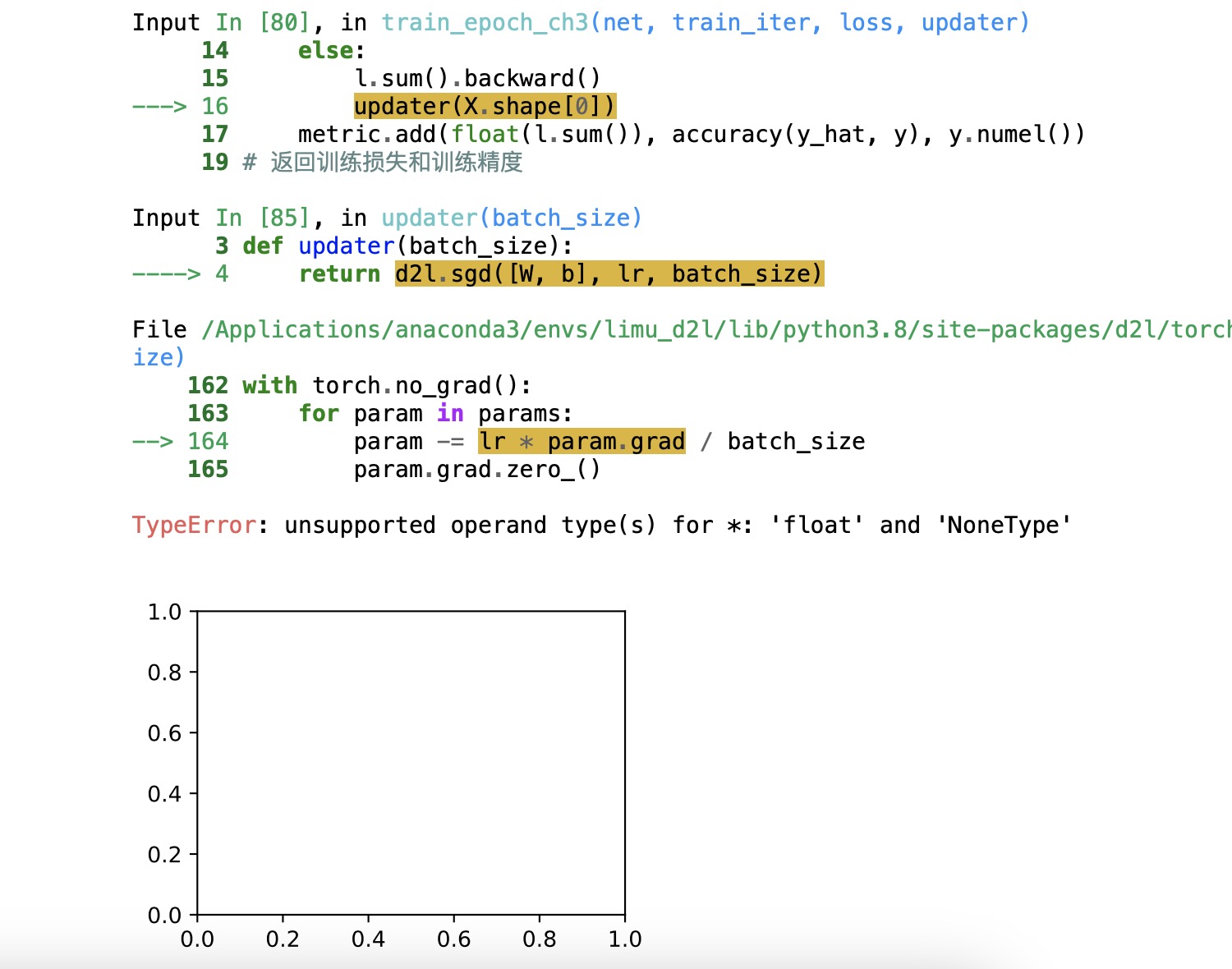
请问这里的loss计算的梯度是如何影响update函数进行参数更新的呢,从这里我没有办法看出这两行代码是如何参数传递的,换句话说 l.mean().backward() 所计算的梯度保存在哪里又是如何被调用的呢,谢谢!
调用net(X)的时候,里面的参数W和b都是训练后的。
import torch
from IPython import display
from d2l import torch as d2l
why do we have to import d2l tweice?
3.8 小结中第二条, 训练softmax 回归循环模型,这里的循环是笔误还是其他?softmax 和循环模型有关系吗?
updater 里面包含了 sgd, 可以去看这部分代码。sgd 里把参数 w, b 传进去, loss 反向之后,w,b 的梯度就计算出来了,根据公式更新的。
1 Like
请问在 # 使用定制的优化器和损失函数 这里l.sum()改为l.mean()结果为什么就很不一样了
代码 cmp= y_hat.type(y.dtype)== y 中cmp是什么类型?

调试笔记
简洁实现如果报错为:grad can be implicitly created only for scalar outputs,解决方法为转到d2l的torch.py,将图中位置修改即可。
1 Like
有人遇到用内置的crossentropy loss 和sgd/adam算,出现loss为nan的情况吗?
为什么会断言train_loss小于0.5呢
我也出现了这个问题,解决的方式有点莫名其妙,不过如下:
1.插入了这一行,之前运行的时候没有加

2.修改了这里的括号,一定要数清楚这里的括号,象征的意思太多了。

然后我就run出来了,希望有帮助!另外我把b换成了inputs的跑了一遍,额,然后就出来了
是不是数据集因为网络问题没有成功下载, ![]()
![]()
![]()
![]()
![]()
因为你的train_loss损失大于0.5,所以就停止运行了。根据报错来看,你的train_loss应该是0.786,你把边界值大概改小一点即可
1 Like
让训练过程在后台线程运行,图形显示在前台主线程中(GUI不能在后台线程),通过后台线程调用API(plt.draw())更新前台打开的绘图窗口。以下是修改代码示意:
import threading
class Animator: #@save
def add(self, x, y):
'''...内容省略...'''
if 'display' in globals(): # 非Notebook环境不调用display()
# display:ipython = globals()['display']
display.display(self.fig)
display.clear_output(wait=True)
def train(net, train_iter, test_iter, loss, num_epochs, updater): #@save
# animator = Animator(...)
def train_thread():
for epoch in range(num_epochs):
'''...原有的训练过程代码...'''
if 'display' not in globals():
print('epoch {0}: train loss {1}, train accuracy {2}, test accuracy {3}.'.format(
epoch, train_metrics[0], train_metrics[1], test_acc
)) # 控制台输出
d2l.plt.draw() # 更新绘图
train_loss, train_acc = train_metrics
'''...原有的训练过程代码...'''
if 'display' not in globals():
th = threading.Thread(target=train_thread, name='training')
th.start()
d2l.plt.show(block=True) # 显示绘图
th.join()
2 Likes