老师好!大佬们好!请问除了Softmax回归从零开始实现外,凡是碰到d2l.train_ch3或d2l.train_epoch_ch3的都会报以下错误,应该怎么办?
RuntimeError: grad can be implicitly created only for scalar outputs
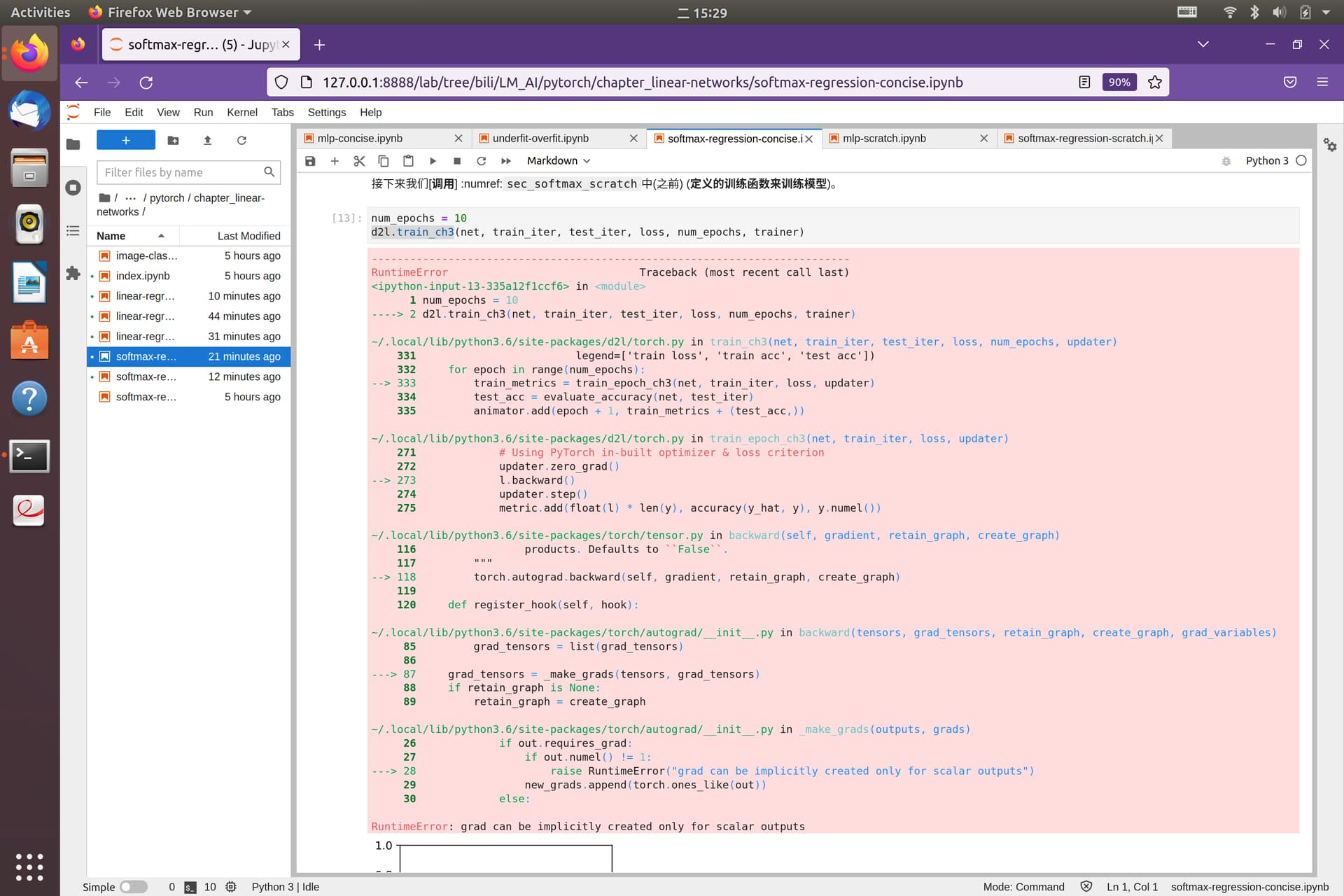
爬楼翻到了:loss = nn.CrossEntropyLoss()
已解决
3.5 和 3.6 的代码要一起运行,3.7的代码要单独运行,这样就不会报错了
我也遇到了这个问题。建议作者改一下代码。谢谢。
后续代码net. Apply(init_weights);应该会遍历网络的每一层并执行init_weights。
1 Like
我试了一下,确实是可以的,请问为什么要去掉呢?谢谢 ~
因为reduction=‘none’,它会将几个输出的loss组合为一个向量,而求梯度要求输出为标量
我也遇到同样的问题,但是将metric.add(float(l), accuracy(y_hat, y), y.numel())之后又出现新的问题。

3.7.2 说了 , softmax只是求概率的方法,实际中简化计算放到交叉熵损失中了。
在jupyter notebook中实现了 softmax回归的从零开始实现之后,在 Softmax回归的简洁实现中遇到如下问题,调用之前的train_ch3这个函数报错:AttributeError: module ‘d2l.torch’ has no attribute ‘train_ch3’ ,请问大家是什么原因,如何解决?
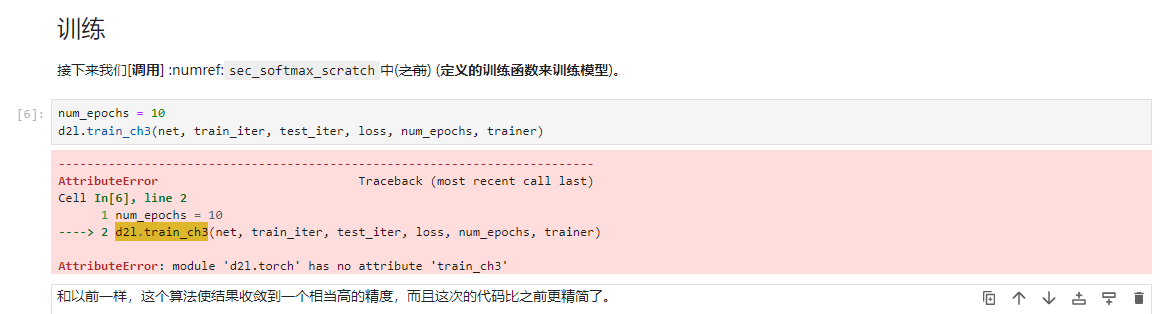
去colab试了一下,没有报错,能跑通。怀疑是否是d2l版本问题,colab中d2l版本2.0.0,本地d2l版本1.0.3,教材安装指导版本0.17.6,或者是其他的版本问题?欢迎大神指导回复。
1 Like
我去教材官网上安装的包,去里面看了现在并没有train_ch3这个封装好的函数了,所以跑不通,估计要换包
后续章节里又遇到这个ch3问题。降低python版本和d2l版本与教材一致后,已经可以了。
1 Like
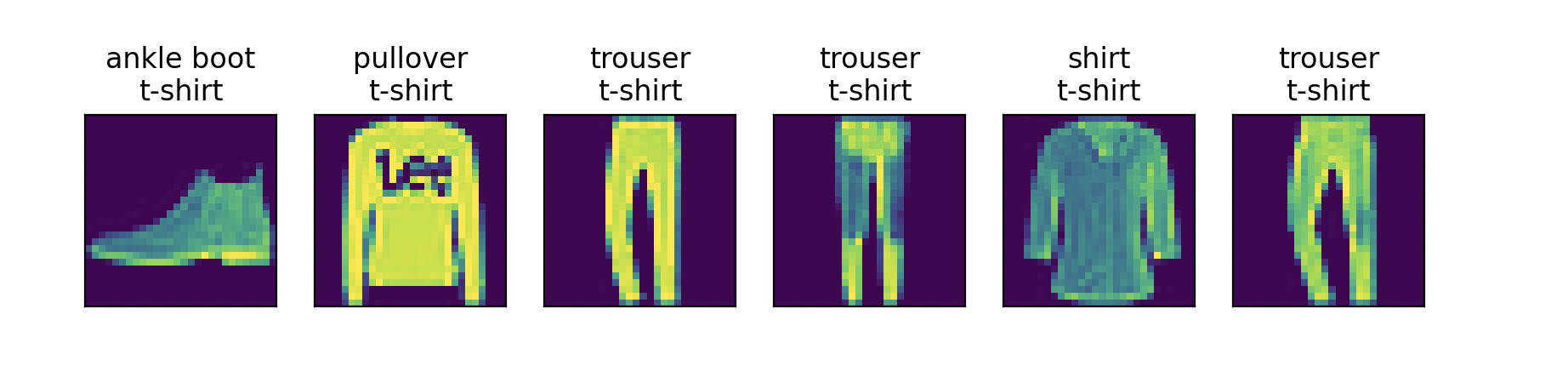
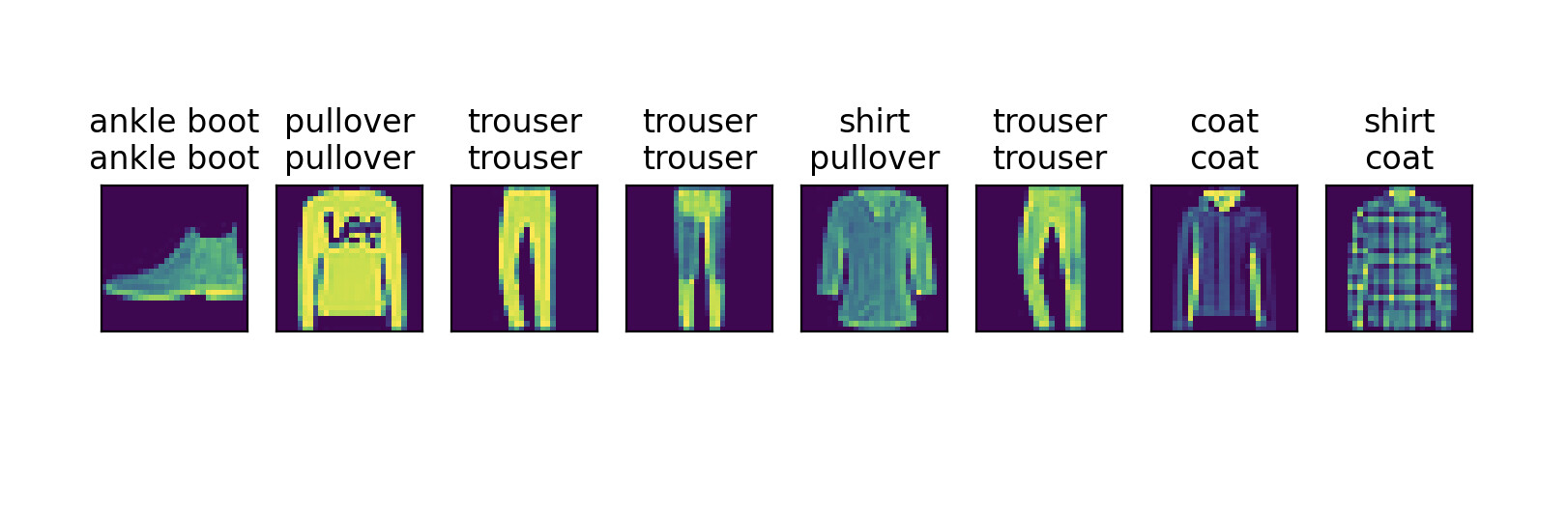
完全用torch重写之后的成果还不错
#!/usr/bin/env python3
import torch
import torchvision
import matplotlib.pyplot as plt
from torch.utils import data
from torchvision import transforms
from torch import nn
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
def get_dataloader_workers():
return 4
def load_data_fashion_mnist(batch_size, resize=None):
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(
root="/tmp", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="/tmp", train=False, transform=trans, download=True)
return (data.DataLoader(mnist_train, batch_size, shuffle=True, num_workers=4),
data.DataLoader(mnist_test, batch_size, shuffle=False, num_workers=4))
def get_fashion_mnist_labels(labels):
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)] for i in labels]
def test_images(imgs, labels, preds):
_, axes = plt.subplots(1, len(imgs))
for (img, label, pred, ax) in zip(imgs, labels, preds, axes):
if torch.is_tensor(img):
ax.imshow(img[0].numpy())
else:
ax.imshow(img[0])
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax.set_title(label + '\n' + pred)
plt.show()
if __name__ == "__main__":
batch_size, lr, num_epochs = 256, 0.1, 10
net = nn.Sequential(nn.Flatten(), nn.Linear(28 * 28, 10), nn.Softmax(1))
net.apply(init_weights)
loss = nn.CrossEntropyLoss()
trainer = torch.optim.SGD(net.parameters(), lr=lr)
net.train()
for i in range(50):
train_iter, _ = load_data_fashion_mnist(batch_size=batch_size)
for X, y in train_iter:
l = loss(net(X), y)
trainer.zero_grad()
l.backward()
trainer.step()
print(f'epoch {i + 1}, loss {l:f}')
net.eval()
_, test_iter = load_data_fashion_mnist(batch_size=batch_size)
batch = next(iter(test_iter))
imgs, labels = batch[0], batch[1]
preds = net(imgs).argmax(axis=1)
test_images(imgs[:8], get_fashion_mnist_labels(labels[:8]), get_fashion_mnist_labels(preds[:8]))
2 Likes
这里取对数要用ln,而你是用lg算的。要证明log(y_hat)==O-max-log(sum of exp),取e为底和取10为底显然不同。但是O-max==0时,恰好等价而已。
我也遇到了同样的问题,在这一行中报错显示除数为零,请问您解决了吗
不用写,直接是个空括号。plt.show()
取多少为底都是差不多的哦,一切的对数都可以看成是以e为底的对数,用换底公式就知道了:
![]()
所以换个底数其实只是损失提取了一个常系数 a,原来以 e 为底的损失是 m 的话,现在以 10 为底的损失就可以看成是 m’ = a · m,其中 a = 1 / ln(10),那么就损失的梯度而言,原来的梯度 ∂ m’ = a · ∂ m,那么梯度下降的时候也是一样缺了一个常系数,所以你要是改变底数,实际上也就和调节学习率是一样的道理。
类似的,一切的指数都可以看成是以 e 为底的指数,参考:
[此图省略,新用户只能发一张图,参见下面回复]
再补充纠正一点,torch或者numpy中的log都是以e为底的哦