https://zh.d2l.ai/chapter_linear-networks/softmax-regression-scratch.html
1 Like
在本章节的 3.6.6. 训练 中的 第一段 PyTorch 代码 中,第 21 行的注释(# 使用PyTorch内置的优化器和损失函数)是不是翻译有误?在 英文版中对应的代码注释 为 # Using custom built optimizer & loss criterion,即 使用定制的优化器和损失函数。
2 Likes
国内电脑使用torchvison下载fashion mnist数据一直跑不动,有什么办法处理嘛?
已经尝试使用下面链接的方法将数据下载到本地并修改mnist.py中FashionMNIST类里的参数,但报错了
https://blog.csdn.net/wangxiaobei2017/article/details/104770519
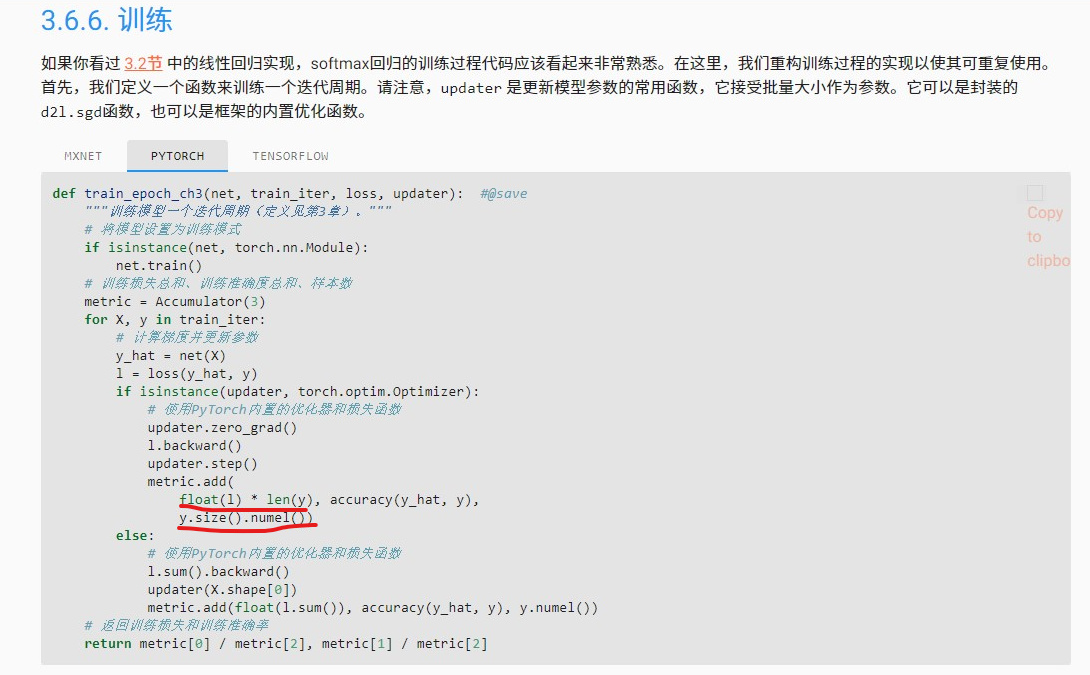
为什么使用pytorch内置优化器和损失函数时,
1.计算训练损失要乘上len(y),是因为pytorch会自动对loss取均值?
2.计算样本数的公式为y.size().numel(), 若y为向量,该式结果不恒为1吗?
3.6.6训练中,else后面的注释,应该是custom built 优化器和损失函数,不是pytorch内置的优化器和损失函数,建议修改
1 Like
Hey @loras_Zhang! Thanks! We have fixed in https://github.com/d2l-ai/d2l-zh/commit/dd8924ea46df23842d16e780d7cebb9ce0c6e2b6
use animator to show the image:
and plt.show() can just show one image
1 Like

def net(X):
return softmax(torch.matmul(X.reshape((-1,w.shape【0】)),W)+b)
这一段代码中,假如X的一个大于1的批量,是不是意味着后面+b这个操作也运用了广播机制
2 Likes
之前定义的 sgd() 中有 with torch.no_grad()
4 Likes
3.6.6节中, 关于累加计算损失和预测正确数的问题.
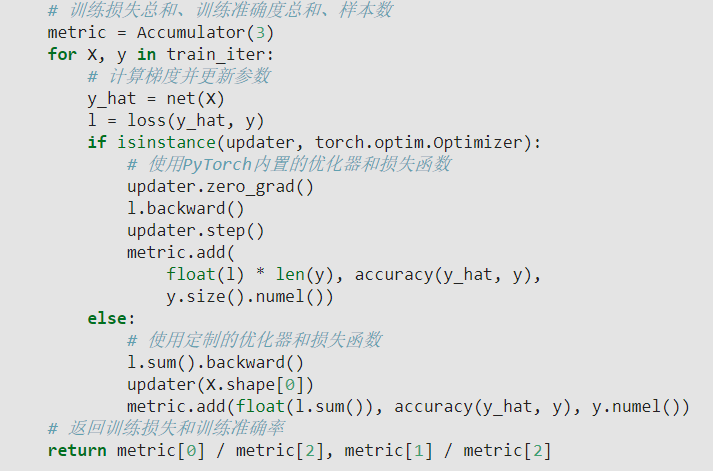
从代码 metric.add(float(l.sum()), accuracy(y_hat, y), y.numel()) 中看, 加的损失值和预测正确数是该mini_batch更新参数之前计算得到的损失, 我有点疑惑,不是应该计算更新参数之后的损失值吗?
另外, 这样在训练过程中对每个mini_batch进行计算, 然后累加的思路, 我也感觉有点迷惑, 因为每个mini_batch对应的 损失值/预测数 都是在不同 [W,b] 的情况下计算的. 我的想法是训练完一个epoch后, 再用得到的模型计算整个训练集的损失和预测正确数, 才能表示这个epoch训练完后模型的真实评估状况.
希望有人能帮助解答一下这两个疑惑, 谢谢 
y_hat[range(len(y_hat)), y]
This is indexing with the right label y.
say y = [0, 2] means there are 2 sample, and the right label for sample[0] is label 0, and sample 1 is label 2. (so len(y) is batch size).
and then y_hat means for every batch/sample, get the predict probability with the indexed label in y.
for tf, it’s tf.boolean_mask(y_hat, tf.one_hot(y, depth=y_hat.shape[-1])) (sparse sampling)
1 Like
想问下animator除了ipython实现还有别的方法吗,如果想直接本地使用cpython执行可以获得类似的动态图例效果吗?
torch.exp(torch.tensor([50]))
tensor([5.1847e+21])
torch.exp(torch.tensor([100]))
tensor([inf])
上面是我本地执行的效果,第一问应该是想要制造出inf溢出效果,那么仅仅设置为50是不够的
4 Likes
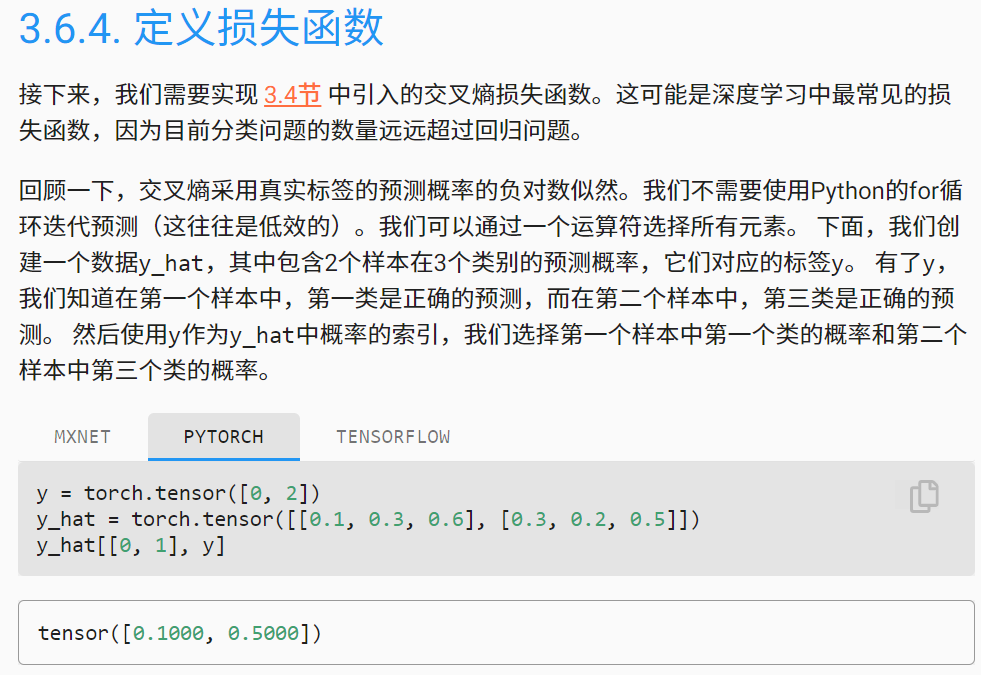
本章3.6.4这里
如果是采用one-hot编码的话,三种类别下y的形式不是应该[0,0,1]吗?为什么采用了[0,2]这种写法呢?
part 3.6.4
if the one-hot codeing is hired, y is supposed to be [0,0,1]. However, the form of [0,2] is used instead. What’s the consideration behind this?
1 Like
标签 y 不是 one hot 编码,你可以 for-loop 一个 iter 的 y 看看
2 Likes