这里的Y意思是有两个样本,第一个样本的正确Y值是0,也就是说第一个样本是‘t-shirt’。 第二个样本的正确Y值是2,也就是‘‘pullover’。
请教一下大家,如何保存教程里的动态图到电脑上!
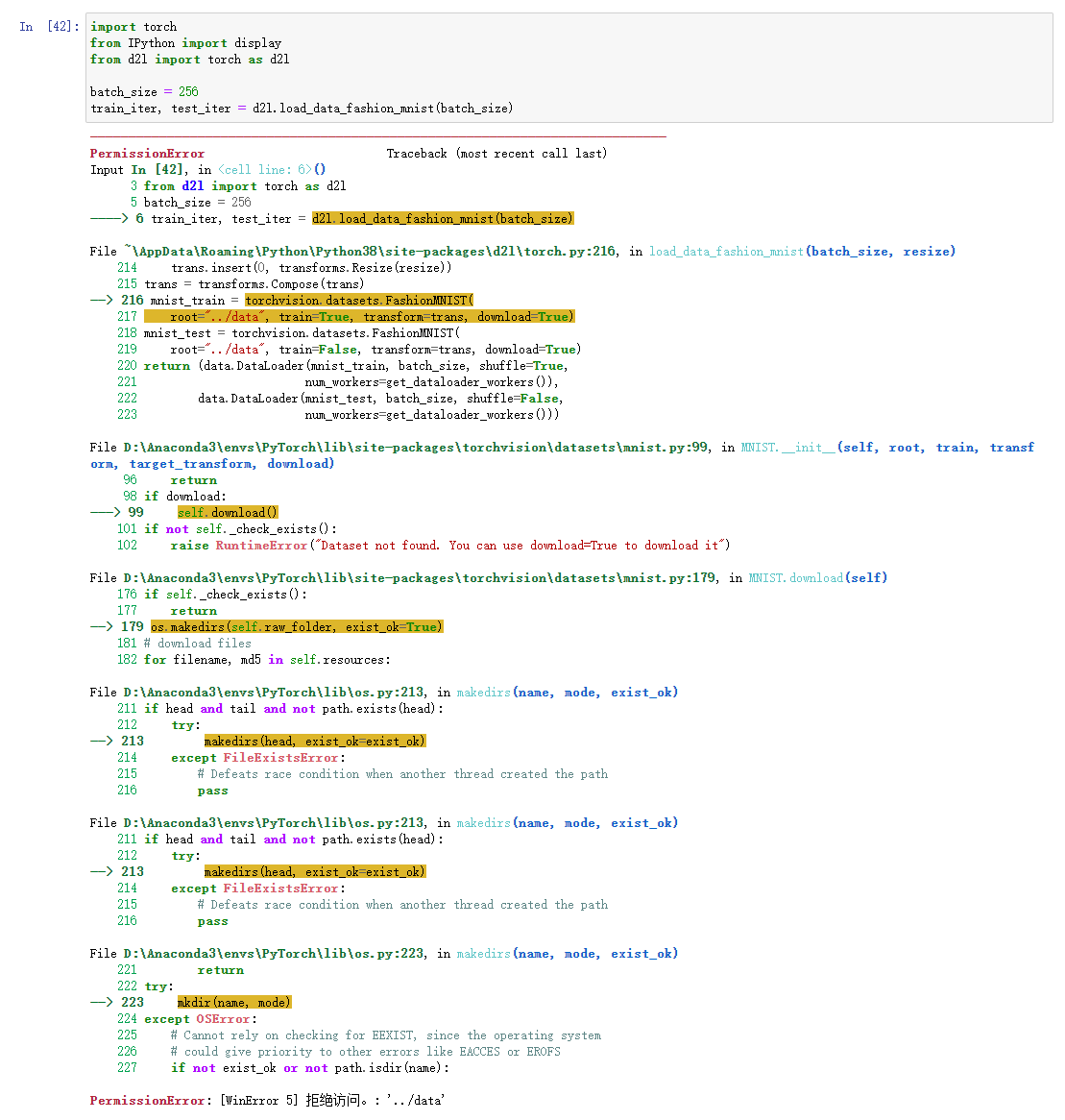
你好,在实现Accumulator时的add方法时显示报错
TypeError: float() argument must be a string or a number, not ‘builtin_function_or_method’
这种情况该如何处理呢?
我也觉得,是得把调用pytorch的crossentropy里的reduction参数一直设为none才行,不设置的话loss确实是一个标量,就不用sum或者mean了
@Ye_Zhang 可是我看到的官方的交叉熵函数默认是会进行除以batch size的呀。
https://pytorch.org/docs/stable/generated/torch.nn.functional.cross_entropy.html#torch.nn.functional.cross_entropy

这里用sum和mean是不是效果相同,都可以用?
文档用的mean, 但是代码中用的sum, 代码该更新了。
1 Like
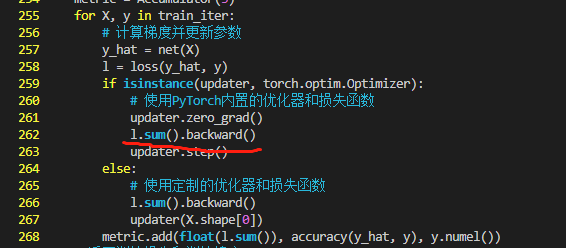
下一章的多层感知机如果使用l.sum().backward() 会让loss全变成一个值 不知道为什么
是l.mean()文档的代码已经进行更新了。
@CHENHUI_XU 这节里的loss不是torch里的loss,是自己定义的函数,求出来的就是张量,如果用的torch里的loss默认才是均值。所以这里使用torch的sgd。需要l.mean()
@Ye_Zhang 转换成什么形式(sum or mean)要看sgd是如何定义的吧,如果用torch的sgd就是mean,d2l里的sgd就是sum?
@Yuchen971 你更新一下d2l的代码,“0.17.1的d2l包封装的pytorch的训练模型迭代的代码有一个小问题,train_epoch_ch3函数的第9行代码应该是“l.mean().backward(),d2l包里是l.sum()”
额 好吧,你楼上已经贴出来了,才看到……新版代码是没问题的,你以文档的定义为准,loss = nn.CrossEntropyLoss(reduction=‘none’) ,这样的loss要用sum.
2 Likes
你好,请问你解决这个问题了吗,我遇到了和你一样的问题
不好意思啊,我后面就没有把精力放在这个上面了,毕竟这个只是一个可视化,与模型本身无关,后面我直接使用d2l的模块就可以了
谢谢你的回复,这个bug我已经解决了,我当时错的是y.numel后面忘记加括号了,调用Accunulator类中的add函数时,出现了bug,我是初学者,确实用了d2l中模块十几行代码就搞定了
![]()
一个比较数值稳定的实现
import torch
def crossEntropyNaive(x):
expX = torch.exp(x)
return expX / expX.sum(axis = 1, keepdim=True)
def crossEntropySlightlySmart(x):
row_max,_ = torch.max(X, dim = 1, keepdim=True)
x = x - row_max
expX = torch.exp(x)
return expX / expX.sum(axis = 1, keepdim=True)
X = torch.tensor([[1.0,1.0],[1.0,10.0],[1.0,100.0]])
print(crossEntropyNaive(X))
print(crossEntropySlightlySmart(X))
2 Likes
d2l包里的torch.py源代码的show_images()函数里,在最后一行前加plt.show()
如果训练完一个epoch后,再利用整个训练集评估模型,那么还需要第二次遍历训练集。
原本只需要遍历一次训练集就可同时完成训练和评估,训练完再评估的方法却需要遍历两次训练集,时间效率上有所下降。
2 Likes
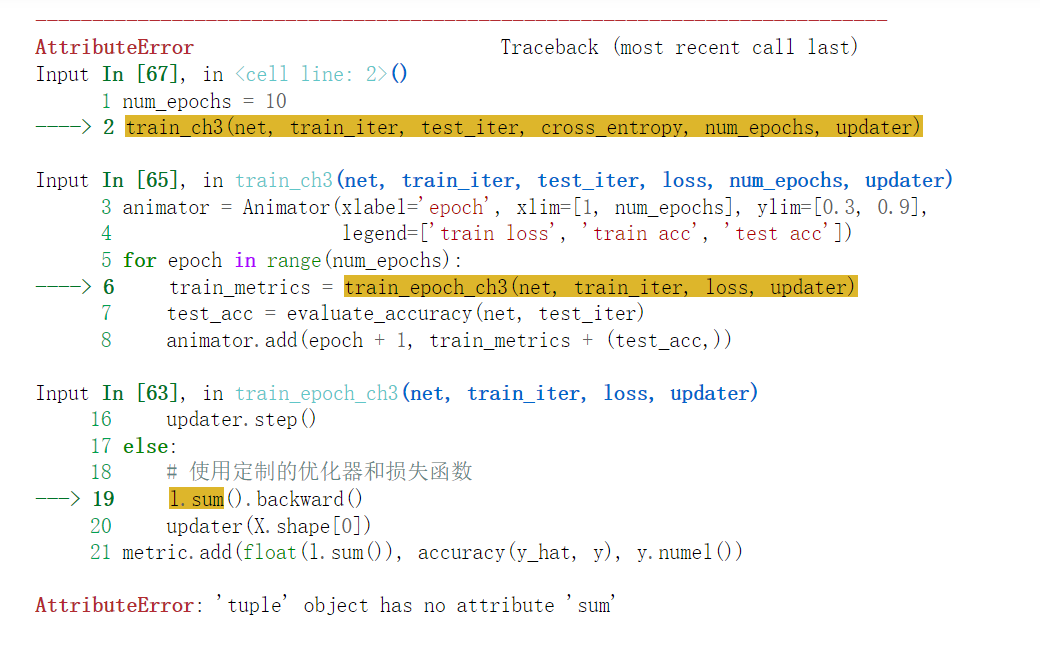
运行结果一直报错,提示为:RuntimeError: DataLoader worker (pid(s) 1612, 16568) exited unexpectedly
尝试了许多方法,都没有成功,是否需要找到相关的num_workers设置,在哪里呢?