我感觉的话,[0,2]对应的是[[1,0,0],[0,0,1]]吧。
2 Likes
使用plt.ion() 可以在IDE上实现动态显示(注: 当显示完一个数据后,在下一个数据运算完成前,界面会是无响应状态,直到计算完成。)
您好,我也遇到这个问题,请问一下怎么修改导入的代码 
-
在本节中,我们直接实现了基于数学定义softmax运算的
softmax函数。这可能会导致什么问题?提示:尝试计算exp(50)exp(50)的大小。
这里对于较大的值会溢出然后针对softmax函数得性质可以尝试对每个值减去一个最大值,最终结果不会发生改变。(不能用markdown嘛。。。为啥写不了公式) -
本节中的函数
cross_entropy是根据交叉熵损失函数的定义实现的。这个实现可能有什么问题?提示:考虑对数的定义域。
return -torch.log(y_hat[range(len(y_hat)), y])
当log(y)中y小于0就会无效,但注意原公式中y_hat是从softmax输出所以均大于0,那么就看y值,也就是类别。好像y为负数也没问题。。。然后尝试了一下如果y_hat中argmax值也接近于0会怎么样,当如下图所示时就炸了。处理的话设置当y_hat中argmax值小于这个阈值时输出-104或者其他值就ok。

- 你可以想到什么解决方案来解决上述两个问题?
在1.2中已经回答 - 返回概率最大的标签总是一个好主意吗?例如,医疗诊断场景下你会这样做吗?
不是标签算是分类问题,医疗诊断更加希望给出一个回归得结果(概率)。我觉得返回sotmax值就ok。 - 假设我们希望使用softmax回归来基于某些特征预测下一个单词。词汇量大可能会带来哪些问题?
词汇量大可能会导致softmax的最大值普遍较低,也就是loss可能会比较高,计算开销倒是不大为O(n)。(感觉,也没试过)
2 Likes
def train_epoch_ch3(net, train_iter, loss, updater): #@save
“”“训练模型一个迭代周期(定义见第3章)。”""
# 将模型设置为训练模式
if isinstance(net, torch.nn.Module):
net.train()
# 训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
for X, y in train_iter:
# 计算梯度并更新参数
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad()
l.backward()
updater.step()
metric.add(float(l) * len(y), accuracy(y_hat, y),
y.size().numel())
else:
# 使用定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回训练损失和训练精度
return metric[0] / metric[2], metric[1] / metric[2]
我想问下这段代码 使用pytorch内置优化器下面 l.backward()是不是错了,感觉应该是l.sum().backward()吧
[0,2]对应的是标签,意思是第一行里第一个是正确的标签,但是预测概率为0.1,第二行第三个是正确标签,预测概率最大因此正确率为0.5。
1 Like
大佬啊,你这思路很好啊。。。。。。。。。
请问这个问题您解决了吗,我也遇到这个问题了
我记得好像是我代码有问题,重新用书上的代码就好了
@Livid_Su @saint Hi, 这个问题是因为上边3.5.3演示了loaddata的方法可以同时resize图像为64*64,然后你就接这个数据往下走了。到这里就发生了数据不匹配。你可以尝试执行一下3.6.1前边的代码,重新生成一下原始图像size的test_iter
多谢指教
紫薯紫薯紫薯紫薯紫薯紫薯紫薯紫薯
1 Like
为什么同样的代码 在同一台机器上,jupyter notebook里跑和在IDE里跑 损失值、精度差别这么大呢?
1 Like
Awesome!
y_hat[0] return the first tensor[0.1,0.3,0.6], and the y_hat[1] returns the second. We want the possibility of the true label of each tensor 0.1 and 0.5 returned, which is 0, 2. So y_hat[[0,1], [0,2]] returns the first posibility of the first tensor and the third posibility of the second tensor
在我自己写代码的时候,如果加上对训练损失的断言,就会报图中的错误,提示train_loss > 0.5。注释掉断言之后可以正常执行
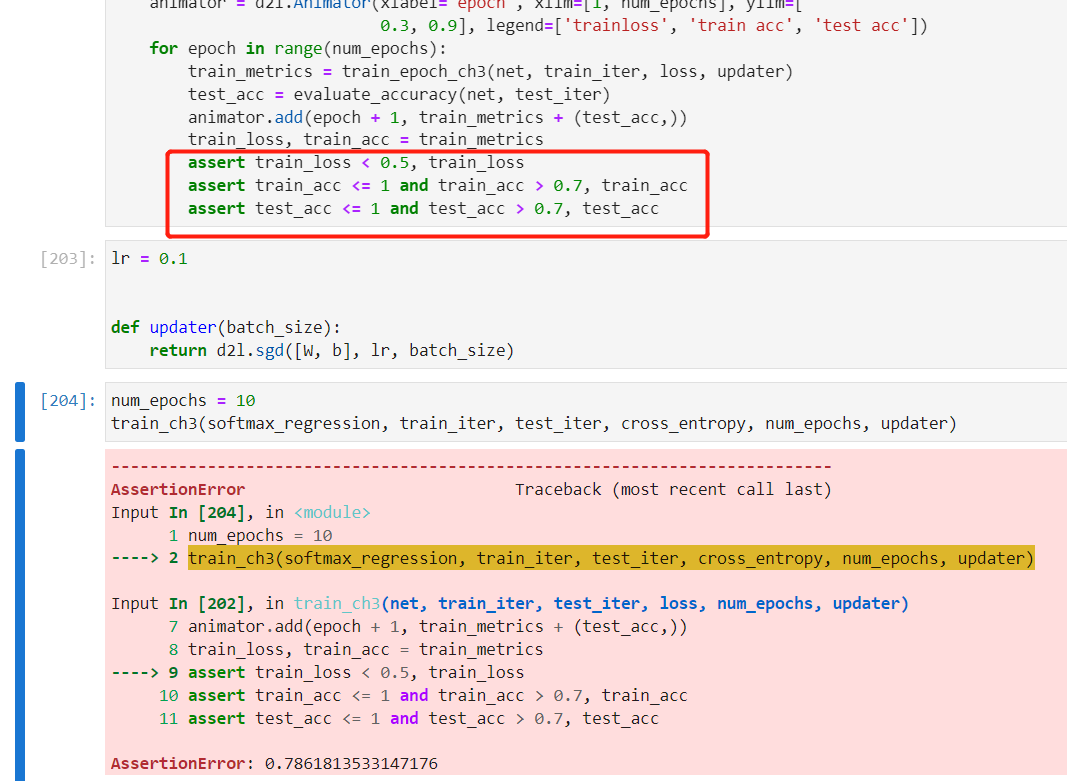
而且在b站的课程视频中并没有看到有断言
但是我在运行书中的jupyter notebook的时候,有断言也不会报错
请问大家有没有遇到同样的问题?感谢感谢 
请问这个问题解决了没?我也是这个问题唉,重新导了好几遍数据还是没有用
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad()
l.mean().backward()
updater.step()
else:
# 使用定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0])
内置的optimizer是不是应该为l.backward() , 因为如果是内置的optimizer一般返回的误差的均值。
对“我们只需⼀⾏代码就可以实现交叉熵损失函数。”的理解,一开始有点糊涂,搞明白了记录一下。
通过
def cross_entropy(y_hat, y):
return - torch.log(y_hat[range(len(y_hat)), y])
求交叉熵损失,关键在前文中提到的“使⽤y作为y_hat中概率的索引”:
y = torch.tensor([0, 2])
y_hat[[0, 1], y]
其实就是y_hat[[0, 1], [0, 2]],如果改一改数值会发现,这其实是有对应的,0-0,1-2,从dim=0到dim=1依次取出作为位置索引。
按公式,交叉熵损失=-∑ylog(y_hat),y是one-hot encoding,一堆0和1个1,1指向的就是位置,意思是只取这个log(y_hat)。
y_hat[range(len(y_hat)), y] 中的y是在dim=0中的每一个(一共有len(y_hat)个),取其对应one-hot encoding中为1的那个位置值,然后直接取-log就是交叉熵损失。
想明白了很简单,Mark down
3 Likes
使用内置optimizer也需要l.mean().backward()
不然会报错grad can be implicitly created only for scalar outputs
原因是教材在第二章说的非标量向量求解梯度,这里是矩阵需要转换成标量形式用sum()或者mean()都行
1 Like
直接用迅雷把
http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz
http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz
以及
t10k-images-idx3-ubyte.gz
t10k-labels-idx1-ubyte.gz
(前缀一样,只能发两个链接)
下载下来,放进本书对应的文件夹下的pytorch/data/文件夹下,再重新运行代码就可以了
1 Like
也有可能是你在定义train_epoch_ch3的时候最后一行的缩进出了问题,我之前也出现了同样的问题
1 Like