是的,只有W和b定义的时候是requires_grad=True
3 Likes
我的理解是这里在更新前还是更新后计算指标并没有那么重要,因为每个batch对模型参数的更新都比较小,尤其是在大型数据集中。因此只要整体上展现出损失函数的趋势即可。
3 Likes
def predict_ch3(net, test_iter, n=6): #@save
“”“预测标签(定义见第3章)。”""
for X, y in test_iter:
break
hi,i don not understand why you ues break ?
这里我理解是[0,2]里面是编码里面1的index,[0,2]对应的就是[[1,0,0],[0,0,2]]。感觉可以类比稀疏矩阵的存储
-
在本节中,我们直接实现了基于数学定义softmax运算的
softmax函数。这可能会导致什么问题?提示:尝试计算 \exp(50) 的大小。
如果网络参数初始化不恰当,或者输入有数值较大的噪音,基于数学定义的softmax运算可能造成溢出(结果超过long类型的范围) -
本节中的函数
cross_entropy是根据交叉熵损失函数的定义实现的。这个实现可能有什么问题?提示:考虑对数的值域。
y_hat中若某行最大的值也接近0的话,loss的值会超过long类型范围。 -
你可以想到什么解决方案来解决上述两个问题?
设定一个阈值,使得loss处于long类型能表达得范围内。 -
返回概率最大的标签总是一个好主意吗?例如,医疗诊断场景下你会这样做吗?
返回最大概率标签不总是个好主意。 -
假设我们希望使用softmax回归来基于某些特征预测下一个单词。词汇量大可能会带来哪些问题?
词汇量大意味着class的类别很多,这容易带来两个问题。一是造成较大的计算压力(矩阵计算时间复杂度O(n^2)。 二是所有的单词所得概率容易很接近0,单词间概率差别不大,很难判断应该输出哪个结果。
27 Likes
evaluate_accuracy(net, test_iter)
这一句我运行后有报错…但我check了前面的函数都没有问题,请问有人有什么思路吗?另外请问这里的net和test_iter是什么啊?不是没有定义这两个变量吗
RuntimeError Traceback (most recent call last)
in
----> 1 evaluate_accuracy(net, test_iter)in evaluate_accuracy(net, data_iter)
4 metric = Accumulator(2)
5 for X, y in data_iter:
----> 6 metric.add(accuracy(net(X), y), y.numel())
7 return metric[0] / metric[1]in net(X)
1 def net(X):
----> 2 return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)RuntimeError: shape ‘[-1, 784]’ is invalid for input of size 131072
3 Likes
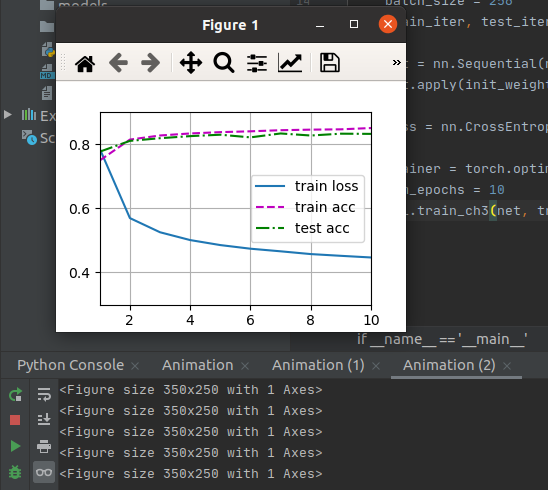
训练的时候使用d2l.Animator只出现类似 <Figure size 350x250 with 1 Axes>提示,并且只输出了最后结果图片,没有出现动画效果,应该怎么解决呢?
1 Like
我也出现了这样的问题,认真检查一下代码,重启jupyter再跑,我已经没这个问题了
同问,你解决了吗?我最后改成直接输出数值了。好像是Pycharm专业版的就能做到动态显示
请问
def accuracy(y_hat, y): #@save
“”“计算预测正确的数量。”“”
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
中的len(y_hat.shape) > 1可以写成y_hat.shape[0]>1吗?这两种写法有什么区别吗?
谢谢
刚才试了一下,如果是一维张量[0,1],那么shape[0]是张量的长度,这里是2,并不能代表张量的行数,而len(y_hat.shape)>1 则可以避免此情况。
1 Like
求问为什么同样的代码在jupyter上可以运行,而搬到py文件里就pid exit unexpectedly
添加一行代码
plt.pause(0.1)
2 Likes
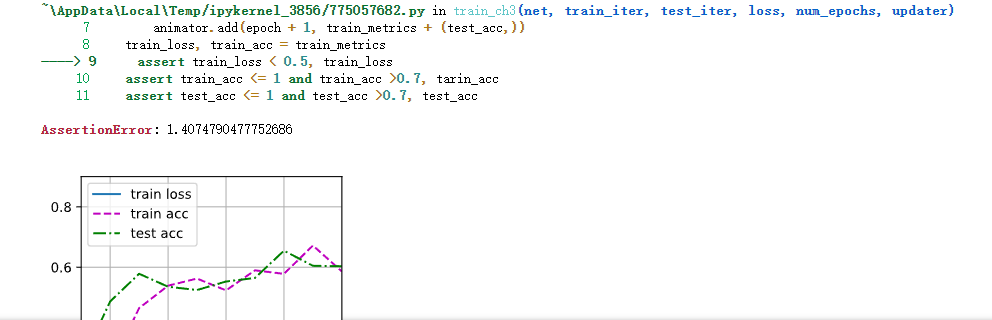
哦,我知道了,Loss太大,超出了显示范围,改一下图的yz轴范围 或者多跑几个epoch,让loss降下来就好了
1 Like
你好,请问本节中定义的net直接包含了softmax层,所以出来的y_hat应该是在(0,1)之间的,但是我们y是在0-9之间,如果直接使用这个损失函数进行训练不会产生影响吗?
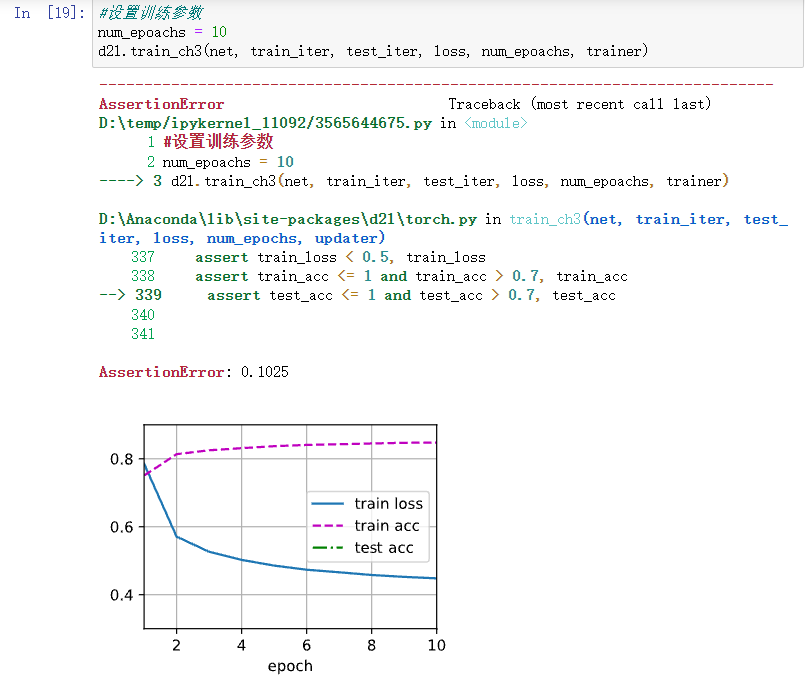
我知道问题出在哪了,以前导入过手写数据集mnist,当调用fashionmnist中的train和test时,train导对了,但test导入的是手写数据集的test