不好意思啊,我后面就没有把精力放在这个上面了,毕竟这个只是一个可视化,与模型本身无关,后面我直接使用d2l的模块就可以了
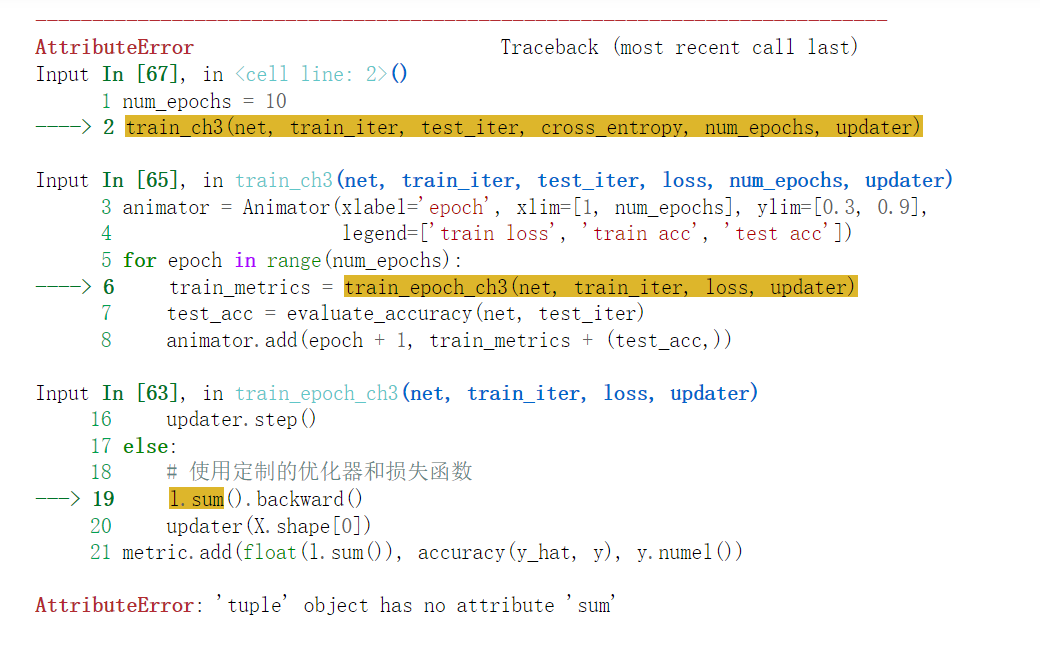
谢谢你的回复,这个bug我已经解决了,我当时错的是y.numel后面忘记加括号了,调用Accunulator类中的add函数时,出现了bug,我是初学者,确实用了d2l中模块十几行代码就搞定了
![]()
一个比较数值稳定的实现
import torch
def crossEntropyNaive(x):
expX = torch.exp(x)
return expX / expX.sum(axis = 1, keepdim=True)
def crossEntropySlightlySmart(x):
row_max,_ = torch.max(X, dim = 1, keepdim=True)
x = x - row_max
expX = torch.exp(x)
return expX / expX.sum(axis = 1, keepdim=True)
X = torch.tensor([[1.0,1.0],[1.0,10.0],[1.0,100.0]])
print(crossEntropyNaive(X))
print(crossEntropySlightlySmart(X))
2 Likes
d2l包里的torch.py源代码的show_images()函数里,在最后一行前加plt.show()
如果训练完一个epoch后,再利用整个训练集评估模型,那么还需要第二次遍历训练集。
原本只需要遍历一次训练集就可同时完成训练和评估,训练完再评估的方法却需要遍历两次训练集,时间效率上有所下降。
2 Likes
运行结果一直报错,提示为:RuntimeError: DataLoader worker (pid(s) 1612, 16568) exited unexpectedly
尝试了许多方法,都没有成功,是否需要找到相关的num_workers设置,在哪里呢?
已解决!
在上一节图像分类数据集中,我们定义的函数load_data_fashion_mnist,并使用#@save保存到d2l中,其返回结果是data.DataLoader,其参数包括num_workers,设置为0后,再通过d2l调用发现并没有更新,所以干脆把定义函数用的代码重新写一下,就解决了!
找到这一行代码:
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
改为如下代码:
trans = [transforms.ToTensor()]
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root="…/data", train=True,
transform=trans, download=False)
mnist_test = torchvision.datasets.FashionMNIST(root="…/data", train=False,
transform=trans, download=False)
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=0)
test_iter = data.DataLoader(mnist_test, batch_size, shuffle=False, num_workers=0)
注意其中的root和download项根据自己情况来设置。
如果有更好的办法,希望大家来交流。
找到此文件…\Anaconda\Lib\site-packages\d2l\torch.py
编辑其中的def get_dataloader_workers():
改为return 0
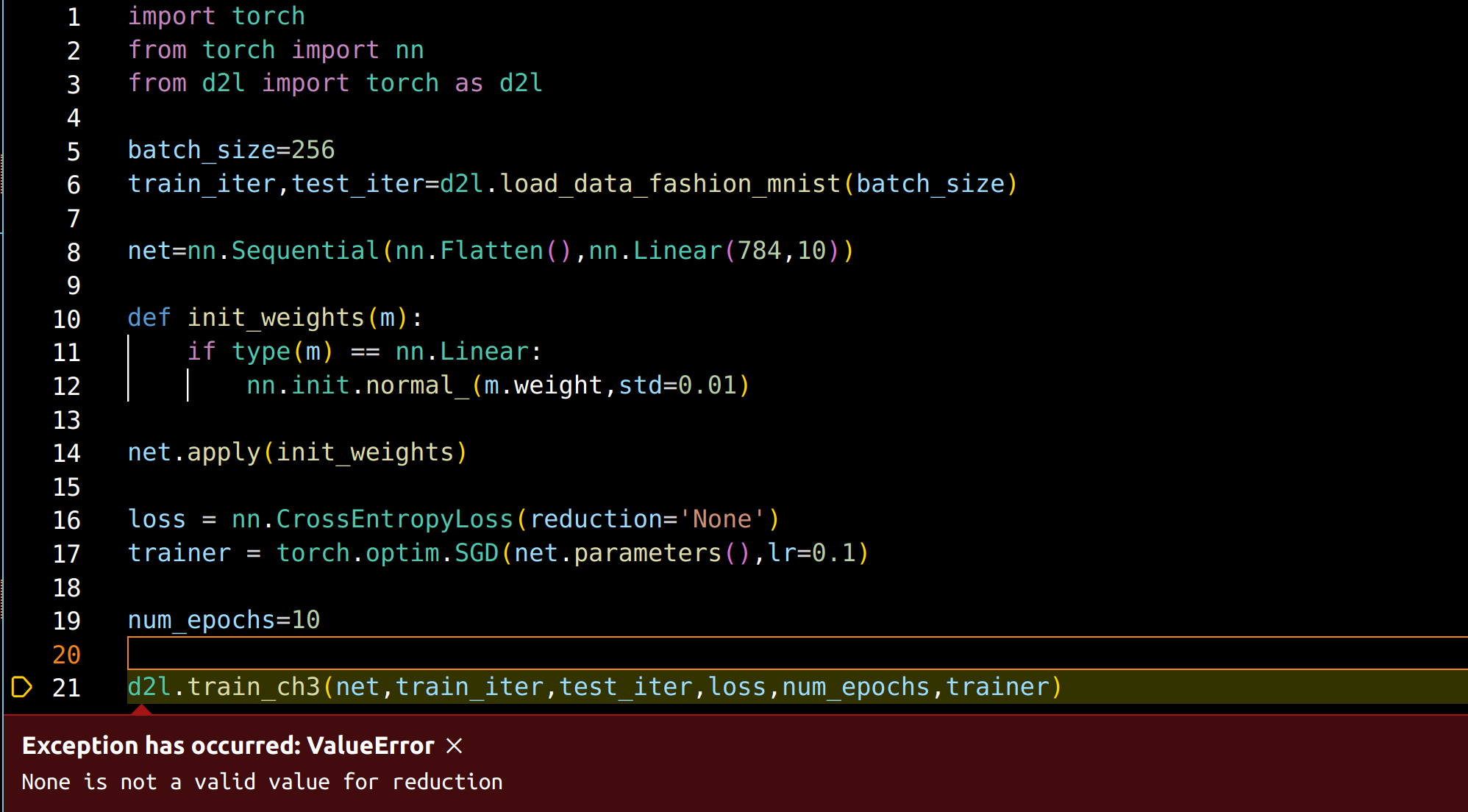
I come across the Exception:
Exception has occurred: ValueError
None is not a valid value for reduction
when I run the code in VScode, how to deal with it?

请问这里的loss计算的梯度是如何影响update函数进行参数更新的呢,从这里我没有办法看出这两行代码是如何参数传递的,换句话说 l.mean().backward() 所计算的梯度保存在哪里又是如何被调用的呢,谢谢!
调用net(X)的时候,里面的参数W和b都是训练后的。
import torch
from IPython import display
from d2l import torch as d2l
why do we have to import d2l tweice?
3.8 小结中第二条, 训练softmax 回归循环模型,这里的循环是笔误还是其他?softmax 和循环模型有关系吗?
updater 里面包含了 sgd, 可以去看这部分代码。sgd 里把参数 w, b 传进去, loss 反向之后,w,b 的梯度就计算出来了,根据公式更新的。
1 Like
请问在 # 使用定制的优化器和损失函数 这里l.sum()改为l.mean()结果为什么就很不一样了
代码 cmp= y_hat.type(y.dtype)== y 中cmp是什么类型?