你好,你的两个层的初始化参数是不一样的,因此输出不同。
1 Like
我想问一下,训练代码中的
bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0],
device=device).reshape(-1, 1)
dec_input = torch.cat([bos, Y[:, :-1]], 1) # 强制教学
这一句是为了给目标序列的5’端头部加入一个起始符。为什么要将目标序列的尾部剪掉呢?这样做是否会损失目标序列最后一个时间步的信息?
还有关于词表tgt_vocab,如果我原始序列的词总数是4,由于加入,是不是意味着我需要更改词列表的长度,在decoder 的embedding步骤需要设置Seq2SeqDecoder模型为
decoder = Seq2SeqDecoder(vocab_size=5, other parameters)
再次感谢此课程,确实是这么听下来最难的一章,也帮我节省了不少时间。
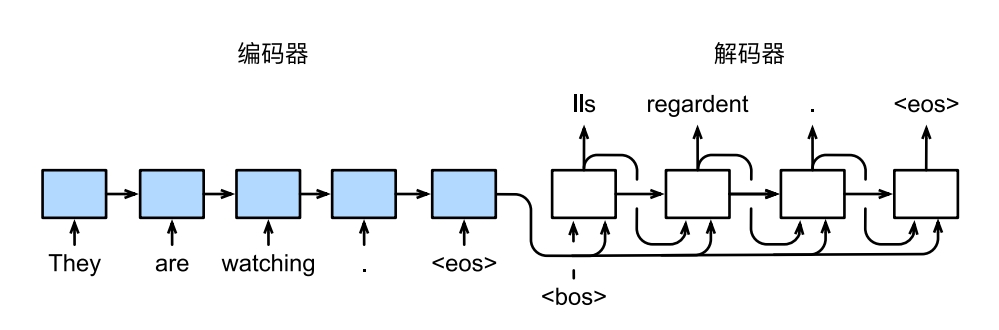
预测中每一个step输入的不是x+上一个state,x你是不知道的。他每一个时间步输入的是y+上一个state,这个y是y-1+上上个state输出的结果。所以自然context在变很正常啊

请问你是将已经预测出的token全部输进decoder用来预测下一个token吗
“则第一个序列的第一项和第二个序列的前两项之后的剩余项将被清除为零。”这句话不太通顺,“则仅保留第一个序列的第一项和第二个序列的前两项,其余的项将被清零”
#@save
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps,
device, save_attention_weights=False):
"""序列到序列模型的预测"""
# 在预测时将net设置为评估模式
net.eval()
src_tokens = src_vocab[src_sentence.lower().split(' ')] + [
src_vocab['<eos>']]
enc_valid_len = torch.tensor([len(src_tokens)], device=device) # 1
src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['<pad>']) # len = 10
# 添加批量轴
enc_X = torch.unsqueeze(torch.tensor(src_tokens, dtype=torch.long, device=device), dim=0) # 1*10
enc_outputs = net.encoder(enc_X, enc_valid_len) # enc_outputs = (output=10*1*32, state=2*1*32)
dec_state = net.decoder.init_state(enc_outputs, enc_valid_len) # 2*1*32 返回的就是编码器输出的state
# 添加批量轴
dec_X = torch.unsqueeze(torch.tensor([tgt_vocab['<bos>']], dtype=torch.long, device=device), dim=0) # 1*1
output_seq, attention_weight_seq = [], []
for _ in range(num_steps): # 预测每个词元的下一个
Y, _ = net.decoder(dec_X, dec_state) # 1*1*201 2*1*32
# 我们使用具有预测最高可能性的词元,作为解码器在下一时间步的输入
dec_X = Y.argmax(dim=2) # 1*1
pred = dec_X.squeeze(dim=0).type(torch.int32).item()
# 保存注意力权重(稍后讨论)
if save_attention_weights:
attention_weight_seq.append(net.decoder.attention_weights)
# 一旦序列结束词元被预测,输出序列的生成就完成了
if pred == tgt_vocab['<eos>']:
break
output_seq.append(pred)
return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
这样就能保证context不更新了吧,但bleu的结果变差了
一直有个疑惑,这里的decoder是一个gru的网络,每次输入一个单词,输出一个预测的单次然后作为下一次decoder中gru的输入,也就是说这两次在gru的内部是毫无关系的,而gru的记忆功能不是网络内部么? 这样的话seq2seq在解码的时候记忆功能不是就没有了么?
在打开的时候,使用编码格式,比如这里可以使用open(raw_file_path, ‘r’, encoding=‘UTF-8’)解码
我的理解是:你说的【输出一个预测的单次然后作为下一次decoder中gru的输入】中的【下一次decoder中gru的输入】不仅有上一次的预测输出的单词还有编码器输出的最后一层隐藏单元的状态。所以【编码器输出的最后一层隐藏单元的状态】就是记忆功能啊
好的,感谢,这个问题我解决了。我把d2l.load_data_nmt的所有源代码都运行一遍就行了。
好的,感谢,按这个理解输入一个单词的时候,也是整个gru的前向传播都会执行一遍么?讲课的时候讲的都是上一个时间步和下一个时间步,而不是整个GRU都前向传播一遍呢,这个该如何理解呢
这块我重新看了一下gru,自己之前理解的都偏了,sequence_len,在gru来说就从来不是固定的
个人感觉代码还存在一个问题,进行训练的句子末尾似乎并没有添加 eos,而进行训练的句子结尾却添加了 eos
我也是这个问题,改了encoding=‘UTF-8’也不行
great。
不太准确地说,prediction step代码实现可看作是“multi-steps 预测,而training step是单步预测,效果当然后者更好“
本质上二个问题都是避免与batch siz及steps即句子长度耦合。结合perplexity含义,loss或输出观察应该保持意思一致。
Q1: no doubt,使用mean是更合理(事实上与perplexity是同意思的)
Q2: 参考perplexity,loss与用户观察值应该是本质一样的。同Q1,二者本质上metric是一样的, 这里是一视同仁地对待翻译长度不同的句子。
另外,作者此次的每个样本loss是传统的全局平均值,不是有效平均值,导致validlen=4,2时也有偏差,反映了不同样本有效长的差异。
为啥这个为什么不能对中文翻译,我把数据换了一下,中文都是出现异常字符