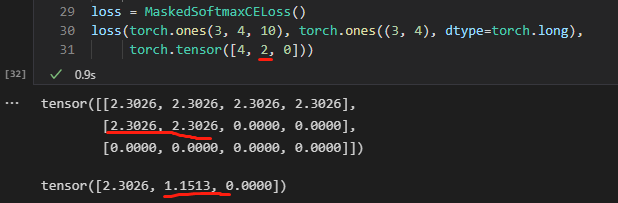
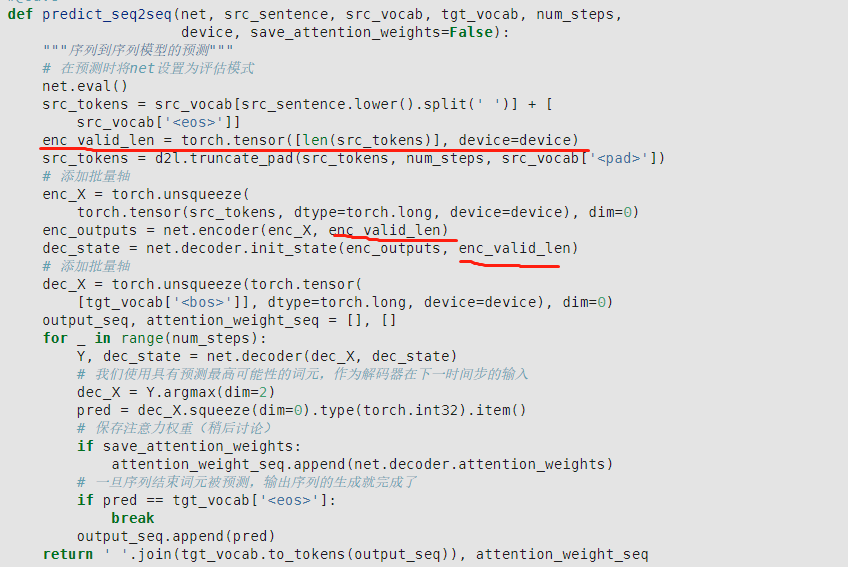
9.7.5 的预测代码中
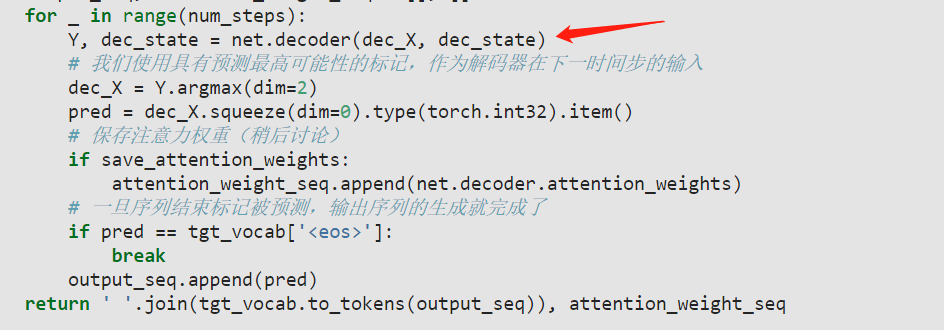
每个时间步调用一次decoder, 其中的dec_state参数随时间步变化而更新,那么decoder中的context变量会根据dec_state的变化而变化,不再是encoder中的上下文信息。这里是不是一个bug,求解惑~
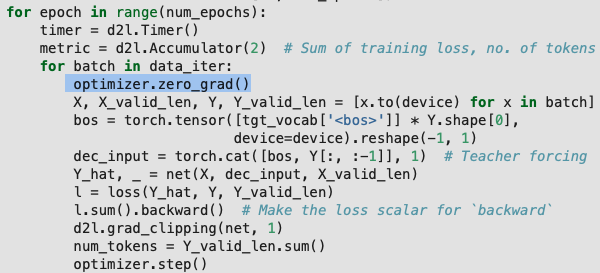
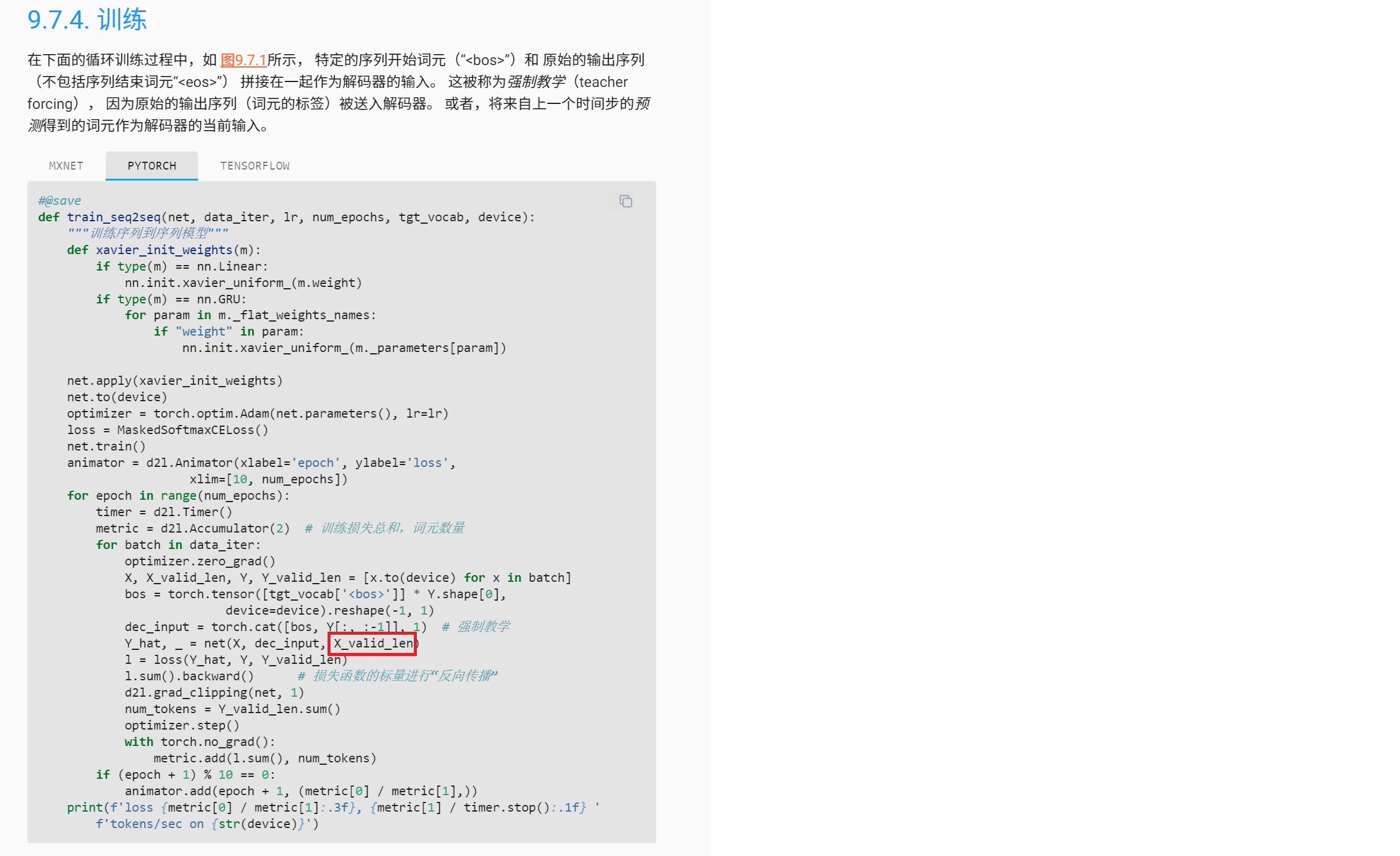
train_seq2seq 函数的训练 step 中是不是需要 optimizer.zero_grad() ?
我觉得也是, Decoder 设计上导致的,英文版里有讨论,包括 train 函数里 zero_grad 的问题
这里就涉及到RNN的具体实现了,在train的过程中,hidden state也是在逐step进行更新的,你可以回看下RNN的scratch实现。只不过train的过程中,output的输入是直接从Y读入的,即无论decoder上一步输出了什么都会被丢弃掉,decoder下一步的输入都是一个正确的预测,用于加速decoder拟合。
而在predict中,就没有这么好的事情了,因为Y不可知,只能从decoder上一步的输出作为下一步的输入,因此这里显式循环,逐step更新hidden state。
所以,train的过程中,可以直接把num_steps作为一个维度加入input和output的参数,直接在net.forward中循环;而predict时,输入的num_steps维度是1,即每次只输入一个word vector,在输出一个output vector。其实两种方式都在更新hidden state,只不过train的过程中,更新隐式地交给rnn了。
感觉是中文版漏了,英文版里很明确需要梯度清零的。
Moon 指的是 context 在变化,这是个问题。
只能说,这是一种设计方式,但是这个方式和文字讲解以及图片是不符合的, 与训练的模式也不统一,可以认为是 bug 了。
图里显示,encoder 的最右端隐藏层始终如一地与 decoder 的输入 X 的每个 step 进行拼接, decoder 的 forward 函数的设计里, X_and_context 使用的是输入参数 state 的最后一层,训练的时候,这个 state 就是 encoder 的最后时间步隐藏层,它的最后一层(被称为 context)一次性与 X 每个 step 都进行拼接,这保证了在训练的时候,decoder 输入的每一时间步都是一个固定的 context 和 X[:,t,:] (或者换轴后的 X[t,:,:])拼接。预测的时候,按照文字说明以及图片,这个 context 仍然应该是不变的,但由于 forward 函数里 context 与 rnn 的初始 hidden layer 耦合了(使用的都是输入参数 state ),hiddern layer 显然应该是随时间不断变化的,但 context 也变化就和图片不符合了。
理论上是需要,但这里经过测试由于梯度裁剪的存在,使得梯度一直处于一个比较小的值,貌似没有太大的影响
def bleu(pred_seq, label_seq, k): #@save
"""计算 BLEU"""
pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')
len_pred, len_label = len(pred_tokens), len(label_tokens)
score = math.exp(min(0, 1 - len_label / len_pred))
for n in range(1, k + 1):
num_matches, label_subs = 0, collections.defaultdict(int)
for i in range(len_label - n + 1):
label_subs[''.join(label_tokens[i: i + n])] += 1
for i in range(len_pred - n + 1):
if label_subs[''.join(pred_tokens[i: i + n])] > 0:
num_matches += 1
label_subs[''.join(pred_tokens[i: i + n])] -= 1
score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))
return score
I think the code above should be corrected to:
def bleu(pred_seq, label_seq, k): #@save
"""计算 BLEU"""
pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')
len_pred, len_label = len(pred_tokens), len(label_tokens)
score = math.exp(min(0, 1 - len_label / len_pred))
for n in range(1, k + 1):
num_matches, label_subs = 0, collections.defaultdict(int)
for i in range(len_label - n + 1):
label_subs[' '.join(label_tokens[i: i + n])] += 1
for i in range(len_pred - n + 1):
if label_subs[' '.join(pred_tokens[i: i + n])] > 0:
num_matches += 1
label_subs[' '.join(pred_tokens[i: i + n])] -= 1
score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))
return score
the space is needed here.
for example “ad og” is different from “a dog” in bigram.
我在看的时候也发现了相同的问题,又看了几遍以为是自己理解错误,看了评论发现原来大家也发现了,那我就安心了。
我改成和训练代码一致后,发现bleu提升巨大,应该就是bug
这里的问题是,train中每一步骤的输入是x+enc_state, 而且是把所有num_steps输入进去,rnn循环中是传递了一个hidden_state随着步骤变化。
但是在预测中,每一step输入的是x+上一个state,而hidden_state不指定, pytorch默认是全0,也就是说训练出来的W_hh:从hidden_state到新的hidden_state的参数全部不用。
最后,我把predict改成和train方式一致,也就是增加了一个state用于保存中间的hidden_state,而enc_state为encoder输出,每次拼接x+enc_state,指定hidden_state为上一个输出state.bleu效果提升巨大。
##运行结果不一样,有没有大神能给解释一下
import torch
from torch import nn
torch.manual_seed(1)
X = torch.rand(2, 3, 4)
flatten=nn.Flatten()
X = flatten(X)
Y = X
print(‘X.shap’, X.shape)
layer=nn.Linear(12,2)
x = layer(X)
print(‘x:’, x)
net1 = nn.Sequential(nn.Linear(12, 2)
)
y = net1(Y)
print(‘y:’, y)
这里没用,后面transformer要用,视频里面有讲

这里两种设计方式应该指的是:是否将编码器的输出拼接到解码器每一个step的输入上,而上面的问题是预测阶段解码器每一个step的输入拼接的不再是encoder的输出,而是上一个step的隐状态了,已经默认选择第二种设计方式了
hidden_state有指定吧, hidden_state不就是输入参数里面的state吗,这里的state应该不只是加到输入上,而且应该包含了将state作为隐变量进行向前传播。