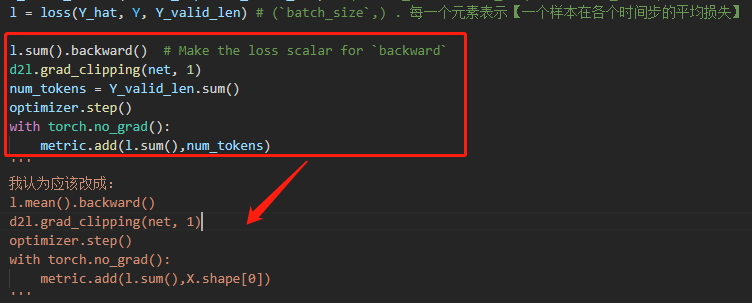
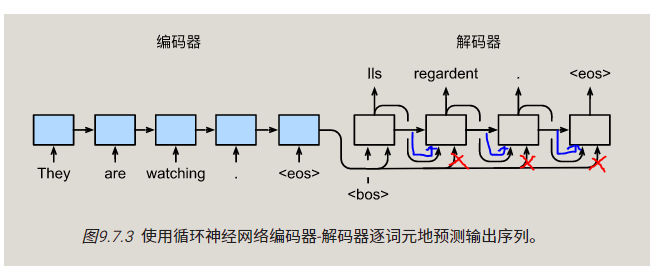
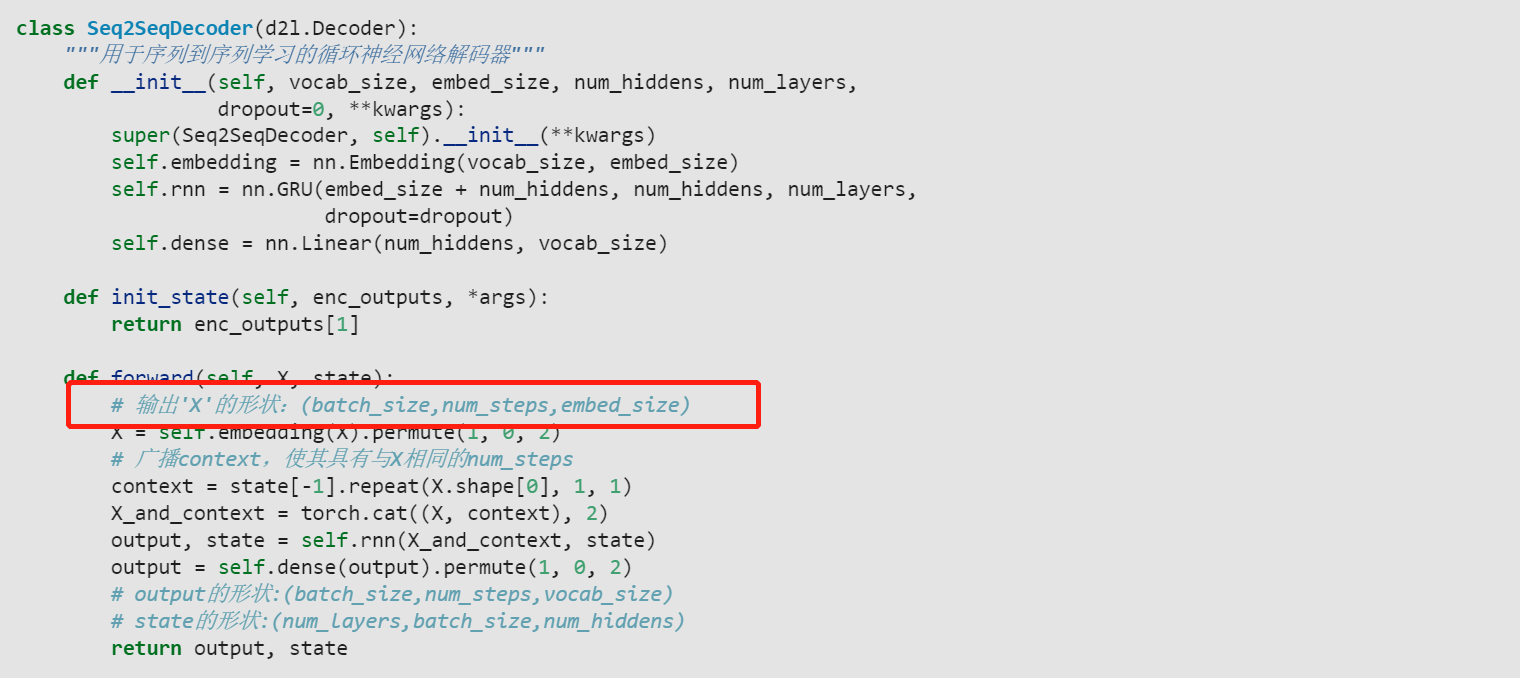
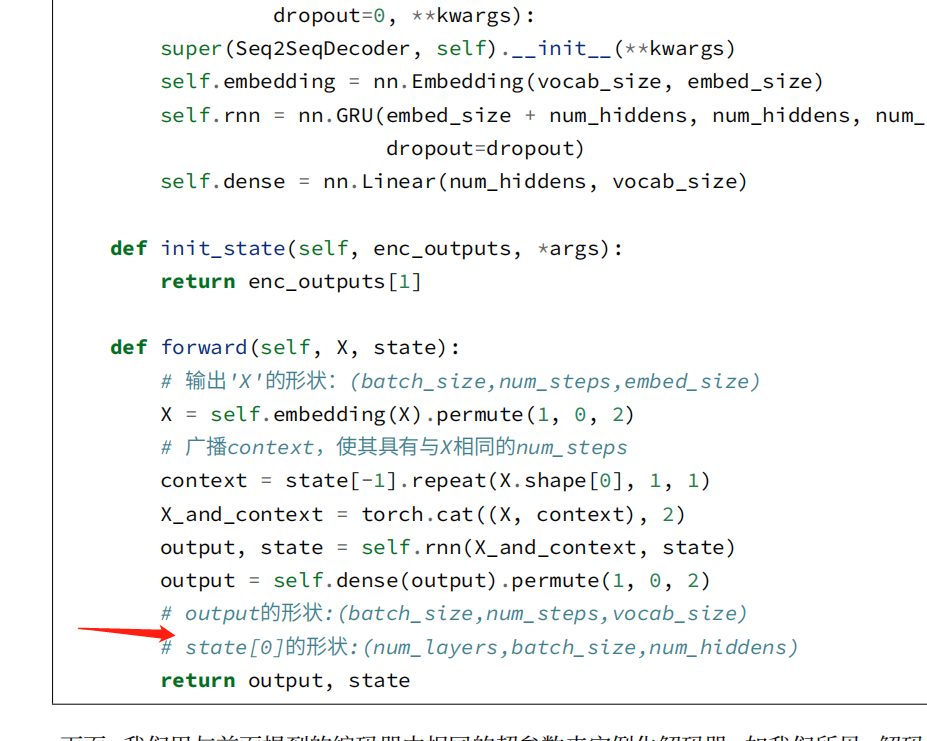
我觉得也是逻辑有错误,需要被cat的encode输出状态在后面预测的时候就成了每个时间步都变化的decoder最新隐状态了,所以我修改了下Seq2SeqDecoder类的实现,修改了init_state函数的输出和forward函数的一部分,使得运行逻辑和文字部分描述相符。
我看到后面“Bahadanau注意力”章节时注意到预测函数的本意是想让state携带着decoder的最新时间步隐状态和encoder输出状态的,所以这里也把Seq2SeqDecoder修改为这个逻辑。
class Seq2SeqDecoder(d2l.Decoder):
"""用于序列到序列学习的循环神经网络解码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, *args):
#return enc_outputs[1]
return (enc_outputs[1], enc_outputs[1][-1])
def forward(self, X, state):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X).permute(1, 0, 2)
# 广播context,使其具有与X相同的num_steps
context = state[-1].repeat(X.shape[0], 1, 1)
# new
encode = state[1]
state = state[0]
# new end
X_and_context = torch.cat((X, context), 2)
output, state = self.rnn(X_and_context, state)
output = self.dense(output).permute(1, 0, 2)
# output的形状:(batch_size,num_steps,vocab_size)
# state[0]的形状:(num_layers,batch_size,num_hiddens)
#return output, state
return output, (state, encode)
这样修改并训练之后,最后的预测部分bleu会获得提升,我的输出为:
go . => va !, bleu 1.000
i lost . => j'ai perdu ., bleu 1.000
he's calm . => il est paresseux ., bleu 0.658
i'm home . => je suis chez moi ., bleu 1.000