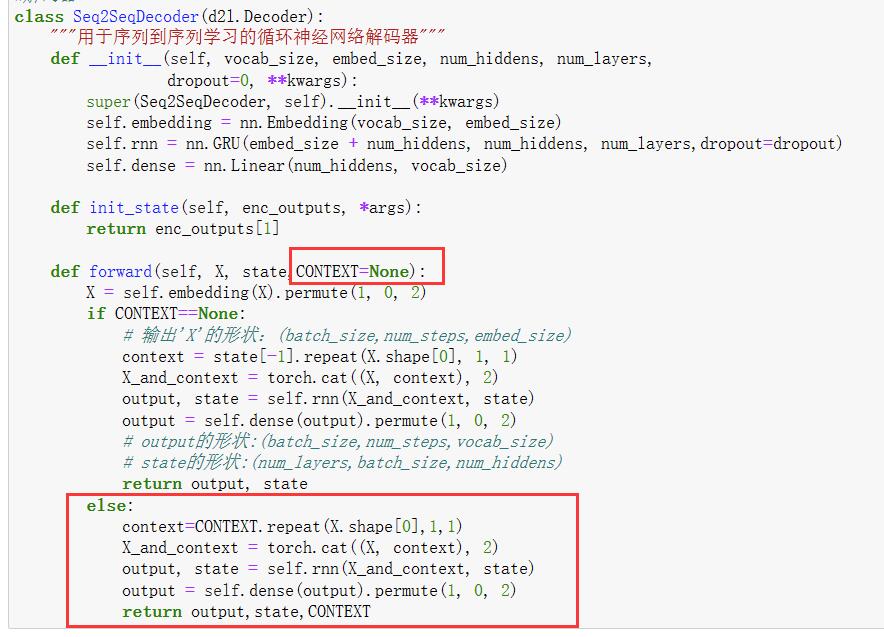
你好!我也发现了,原因是d2l的EncoderDecoder(参考上一章框架的代码)改了(英文版里只return1个),我的解决方案是把上一个框架代码的EncoderDecoder导入到这一章节代码里,以下代码可用于导入别的ipynb(在CSDN上找的):
在这一章节开头导入
import ipynb_importer
import 编码器解码器框架代码名
新建一个ipynb_importer.py
import io, os,sys,types
from IPython import get_ipython
from nbformat import read
from IPython.core.interactiveshell import InteractiveShell
class NotebookFinder(object):
“”“Module finder that locates Jupyter Notebooks”“”
def init(self):
self.loaders = {}
def find_module(self, fullname, path=None):
nb_path = find_notebook(fullname, path)
if not nb_path:
return
key = path
if path:
# lists aren't hashable
key = os.path.sep.join(path)
if key not in self.loaders:
self.loaders[key] = NotebookLoader(path)
return self.loaders[key]
def find_notebook(fullname, path=None):
“”"find a notebook, given its fully qualified name and an optional path
This turns "foo.bar" into "foo/bar.ipynb"
and tries turning "Foo_Bar" into "Foo Bar" if Foo_Bar
does not exist.
"""
name = fullname.rsplit('.', 1)[-1]
if not path:
path = ['']
for d in path:
nb_path = os.path.join(d, name + ".ipynb")
if os.path.isfile(nb_path):
return nb_path
# let import Notebook_Name find "Notebook Name.ipynb"
nb_path = nb_path.replace("_", " ")
if os.path.isfile(nb_path):
return nb_path
class NotebookLoader(object):
“”“Module Loader for Jupyter Notebooks”“”
def init(self, path=None):
self.shell = InteractiveShell.instance()
self.path = path
def load_module(self, fullname):
"""import a notebook as a module"""
path = find_notebook(fullname, self.path)
print ("importing Jupyter notebook from %s" % path)
# load the notebook object
with io.open(path, 'r', encoding='utf-8') as f:
nb = read(f, 4)
# create the module and add it to sys.modules
# if name in sys.modules:
# return sys.modules[name]
mod = types.ModuleType(fullname)
mod.__file__ = path
mod.__loader__ = self
mod.__dict__['get_ipython'] = get_ipython
sys.modules[fullname] = mod
# extra work to ensure that magics that would affect the user_ns
# actually affect the notebook module's ns
save_user_ns = self.shell.user_ns
self.shell.user_ns = mod.__dict__
try:
for cell in nb.cells:
if cell.cell_type == 'code':
# transform the input to executable Python
code = self.shell.input_transformer_manager.transform_cell(cell.source)
# run the code in themodule
exec(code, mod.__dict__)
finally:
self.shell.user_ns = save_user_ns
return mod
sys.meta_path.append(NotebookFinder())