请问为什么我的all_features是330列的,少了一列,我查看了代码是一模一样的。有遇到相同情况的吗?

1 Like
由于加州的数据集有summary,里面都是文字.使用all_features = pd.get_dummies(all_features, dummy_na=True, dtype=int)会导致内存爆炸,我用32g内存依然会爆炸.所以我没有用哑变量处理,转而只训练纯数字维度的数据:all_features = all_features[numeric_features[1:]].这样结果是0.55211.对比autogluon的0.1x的精度差了特别多. ![]()
我试了,因为你模型初始化的时候模型参数一般都是小于1的(初始化参数分布参考https://docs.pytorch.org/docs/stable/generated/torch.nn.Linear.html),所以你计算出来的pred都是小于1的,在log_mse里直接全部截断成1,导致梯度不能传播,模型无法训练
楼上应该是对的,试了下lr设的小训练特别慢。因为输入的数值相对于输出来说很小,所以模型的输出对输入的变化不太敏感,可以用大的lr而不会导致不收敛。常规的lr设置的小应该也是因为输出对输入的变化比较敏感。我一开始对标签也做了标准化,这样用常规的lr取值也能训练,而且收敛速度看起来比文章里的更快。
不是,我直接在kaggle下载的数据,解压后才944kb啊,怎么会12G都爆了呢:joy:![]()
![]()
确实,我还奇怪为什么独热编码后一堆True和False
这个调参,怎么调呀大佬。是一点一点的调参数吗?还是有直接的逻辑推导呢?
这种调参是怎么调的?有理论推导吗?大佬?还是单纯的一点一点的试错呢?
1 Like
这个哈希值是怎么得到的,自己算吗?
DATA_HUB[‘kaggle_house_train’] = ( #@save
DATA_URL + ‘kaggle_house_pred_train.csv’,
‘585e9cc93e70b39160e7921475f9bcd7d31219ce’)
可以自己计算,也可以直接使用,这里肯定是作者计算之后放到这里的。
我电脑64G内存,没问题。。。。。。。。。。。。。
我也是这样,330,貌似跟之前比少了summary特征
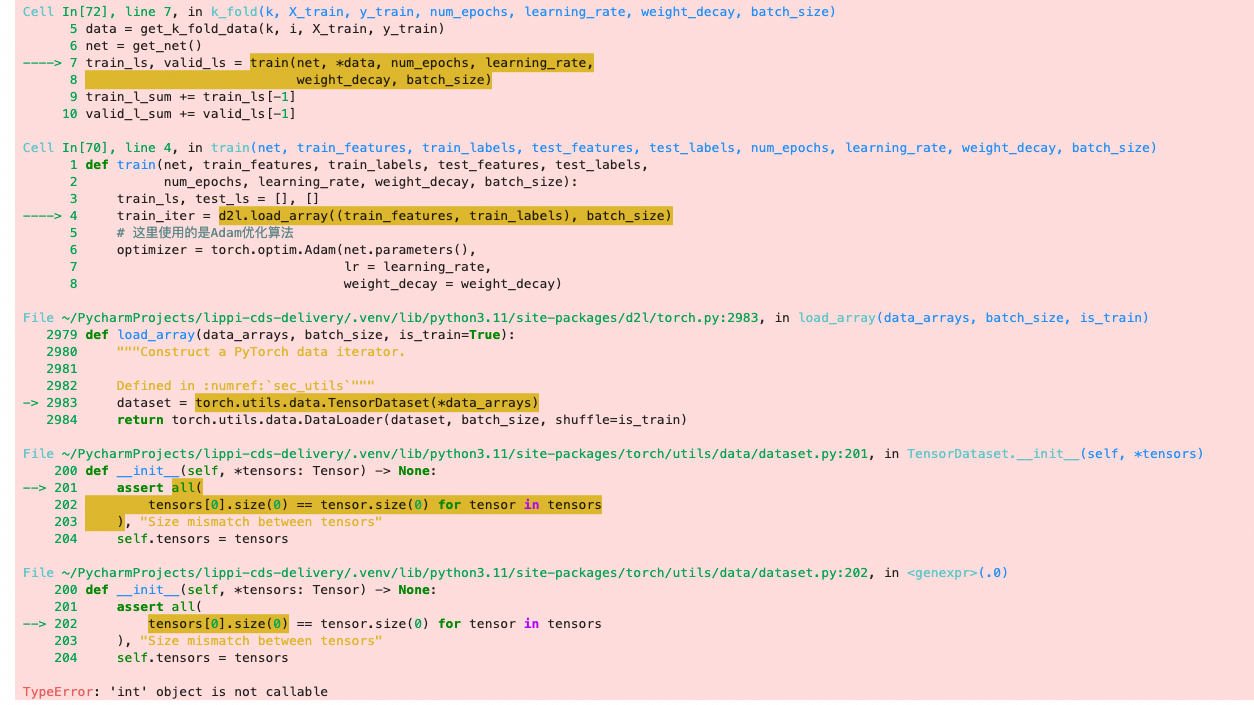
有人跟我一样,执行到最后的报错了:
File ~/PycharmProjects/lippi-cds-delivery/.venv/lib/python3.11/site-packages/torch/utils/data/dataset.py:202, in (.0) 200 def init(self, *tensors: Tensor) → None: 201 assert all( → 202 tensors[0].size(0) == tensor.size(0) for tensor in tensors 203 ), “Size mismatch between tensors” 204 self.tensors = tensors TypeError: ‘int’ object is not callable
好奇怪,不知道哪里出问题了
1 Like
这样可以最好的利用更多数据去求标准化。样本有限的情况下,验证集也是真实数据,也有利用的必要。当然你可以直接在测试集上训练然后在验证集上跑。但是大概率没有合并后再拆分的好。
能让我看看你的神经网络结构和参数吗(为什么要凑够20字)
这么多神经元,这算是大力出奇迹吗,这个数据挺简单的吧
现在还能上传吗???在那上传???哪位告诉我
你好,我也是独热编码后特征变成了330个,而非331个,我都快把整个表检查一遍了,也没找出少的那一个在哪,请问你解决了吗?