https://zh.d2l.ai/chapter_multilayer-perceptrons/kaggle-house-price.html
1 Like
竞赛数据很大,使用pd.get_dummies(all_features, dummy_na=True)处理时,内存(12G)会爆,请问有什么好的办法可以处理?目前我将"Address"和"Summary"列删除了。
2 Likes
pd.to_datetime()会把’NaN’变成’NaT’,然后.astype(‘str’) … .astype(‘float’)就会报错could not convert string to float: ‘NaT’,坑死我了 
2 Likes
文章,在对数据集进行0均值处理时,在未确定是否存在np.nan情况下 apply(lamba: x ; (x-x.mean())/x.std()), 在进行填补。缺少均值填补的步骤。
3 Likes
为什么这里训练模型的时候使用的损失函数还是nn.MSEloss()而不是上面定义的那个log_rmse?我们期望的不是这个损失最小吗?
5 Likes
为什么这里的lr要求高达5呢  ?一般来说不是小于1 吗?
?一般来说不是小于1 吗?
3 Likes

num_samples should be a positive integer value, but got num_samples=0,总是报这个错误是什么原因呢
弱弱问一句,还有12g内存吗。。。。。。
1 Like
本地train能达到99%以上,但是在网站测试只有90%以下了,调参真不容易
1 Like
我今天看到的时候,也有这个疑问~ 
我也想问这个问题,而是明明按特征量来说,其实图片的数据更大才对,不知道为什么这个dummies后的数据量 shape没多少 但是量是真的大
训练提交kaggle成功,为什么我本地pycharm 出不来这个图呢 ? debug代码也看到执行到这段逻辑了 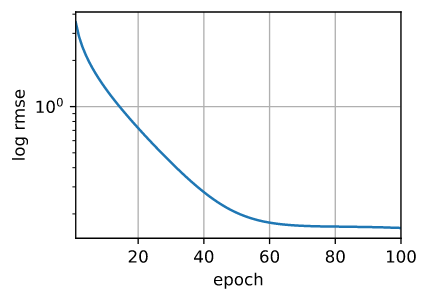
你好这个问题解决了吗 我也遇到了一样的问题。。。
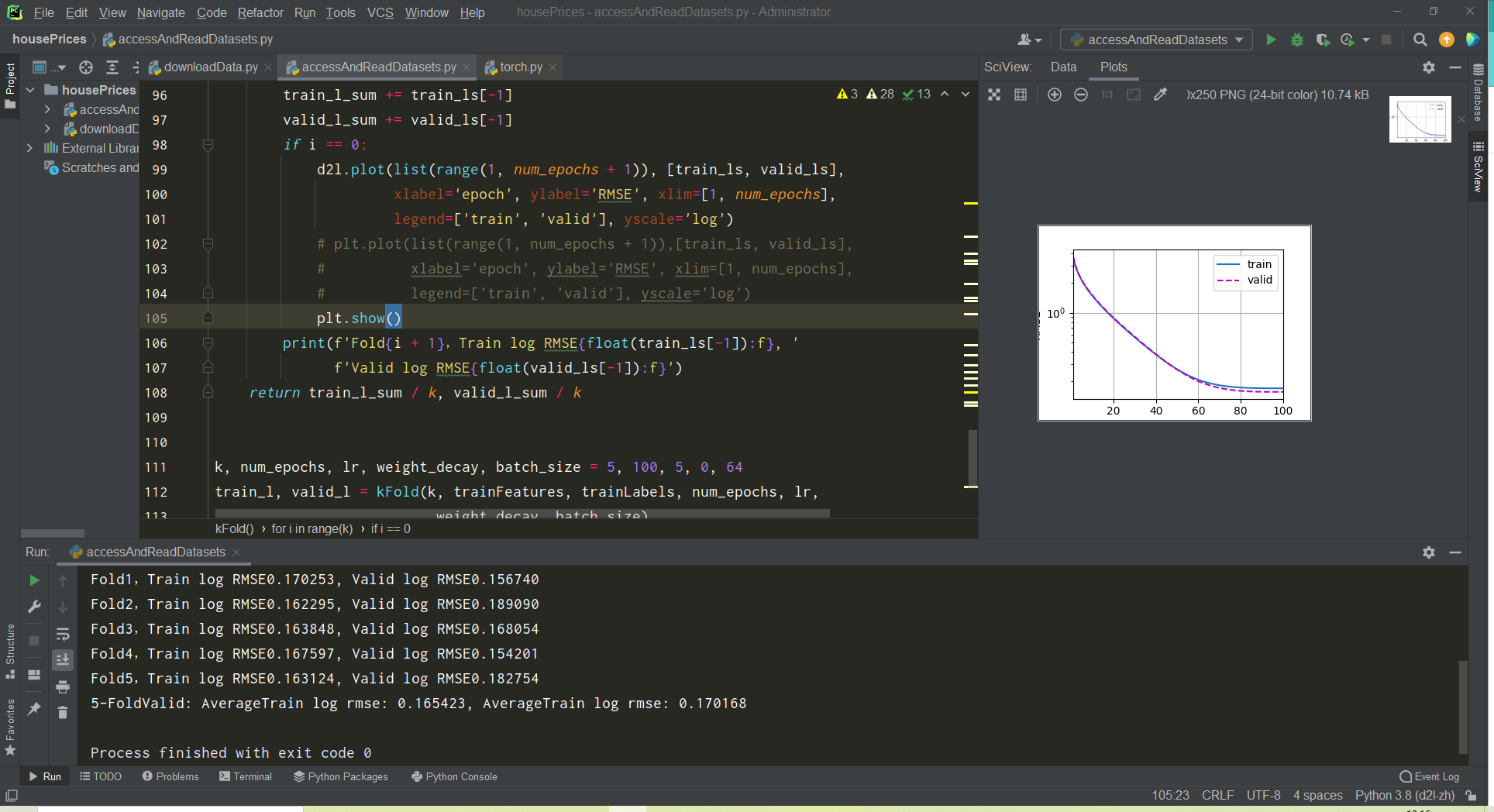
你这是过拟合了😂 .。。。。。。。。。。。。。。。
2 Likes
预测问题在训练时还是使用最小均方误差作为损失函数,定义的log_rmse只是用来比较不同模型的好坏
2 Likes