你好,我独热编码后也是330个特征,请问你现在解决了吗?到底是什么原因导致少了一个特征啊
你好,请问330的问题怎么解决啊,我也少一个特征
我也是k ![]() ,听说是有些版本下none会被当做na缺失值,所以少了特征为none的独热编码,但不知道怎么解决呜呜呜
,听说是有些版本下none会被当做na缺失值,所以少了特征为none的独热编码,但不知道怎么解决呜呜呜
找到解决方案了,在train.csv和test.csv文件里去把None全部替换成None_或者None_pea就行了,反正别是None,用ide的查找加全部替换就可以了
要么就是把summary那一列去掉,要么对该列单独使用ordinalencoder(但会引入顺序关系,可能会干扰模型)、要么仔细观察这一列数据,检查是否有价值,如果没有额外的信息价值是可以去掉该列特征的(可以使用互信息查看)。
有没有较好的调参策略,这个感觉还是很难调的。
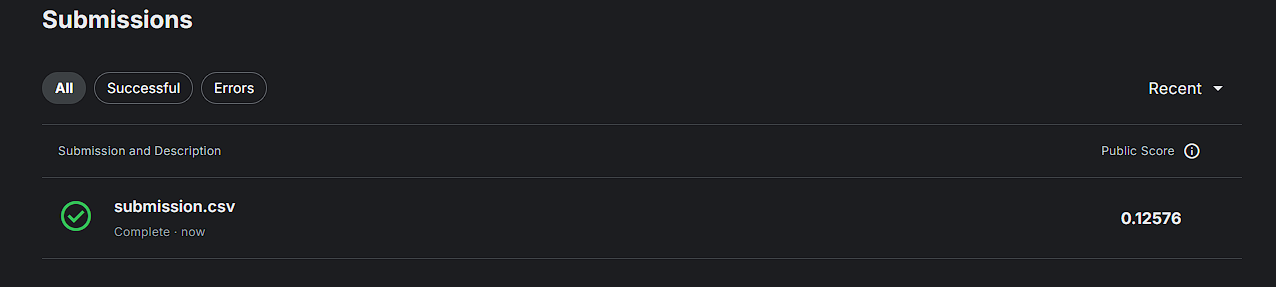
目前最好的成绩是这样的
loss = nn.MSELoss()
in_features = train_features.shape[1]
def get_net():
net = nn.Sequential(
nn.Linear(in_features,1024),
nn.ReLU(),
nn.Linear(1024,1)
)
return net
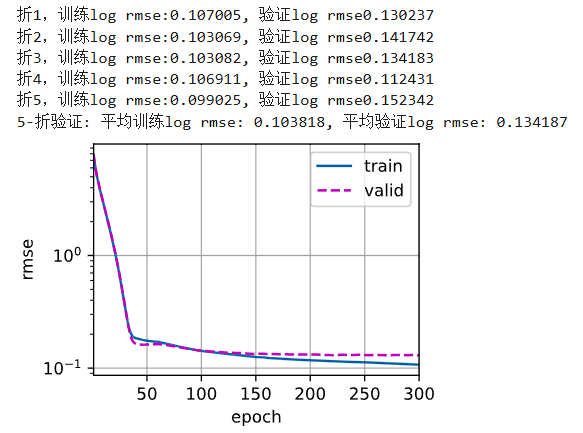
增大batch_size可以让loss下降得更平滑,如果batch_size比较大train_loss还是很抖的话,可以尝试降低学习率和惩罚系数
调了又调,终于调出来,线性模型最低到0.14,换成神经网络模型可以再低一些,到0.12697,其它基本没动,lr改为0.01,weight_decay到5,k值自己测过5或者8都差不多,不影响泛化误差的值
不可以,使用one-hot是为了保证类别之间的距离相等;如果使用1、2、3,那么红和蓝之间的距离就变了,而且这样的序号乘上权重的话,2和3还会有额外的放大。