同楼上lifanqie1所说,确实是有些值设定为None后会将其与NA都设定为缺失值,但是不是MasVnrType(没有这个特征),解决方法是加一行all_features.replace('None', 'None_fea', inplace=True)就可以了
1 Like
你可以打印一下all_features的dtype,可以看到大概率是前一步转独热编码的时候它给的是Boolean型而不是int形式的0和1,在转tensor之前自行转化一下就可以:all_features = all_features.astype({col: ‘int’ for col in all_features.select_dtypes(include=[‘bool’]).columns})
2 Likes
为什么我下载数据集报错
AccessDenied
Access Denied
07JRYK4SMH161F5T
wmG3gxeJIKt5qA/g8Vrtz2P030+6AIK8cNAhvDwlJ/bJYq1ukvfE9Sp/ApnCJyL+wIwfd/PFWAI=
print(train_data.shape)
print(test_data.shape)
(1, 1)
(1, 1)
非常感谢,我是新手,使用的pycharm,遇到这个问题,使用你的方法已经解决

为什么原本的bool不能用呢,支持的类型不是有bool吗
同意lifanqie1所说,但Naom1的解决方案似乎不太行。确实是MasVnr中有None,pandas在读取csv之后就会把None视作NA,因此用inplace替换无法找到’None’字符串;我的解决方案是:需要在csv源文件中替换None为None_fea,再用panda读取时候改为修改后的文件,就可以了
均值填充在apply之后,是等效的。你可以理解为,本来是均值填充,但是先归一化处理后均值为0,因此后边进行0填充即可。


是不是这个课程有专用的微信讨论群呢?记得之前看到,好像是在v1版本的评论区,现在却关闭了。看到的麻烦发一下
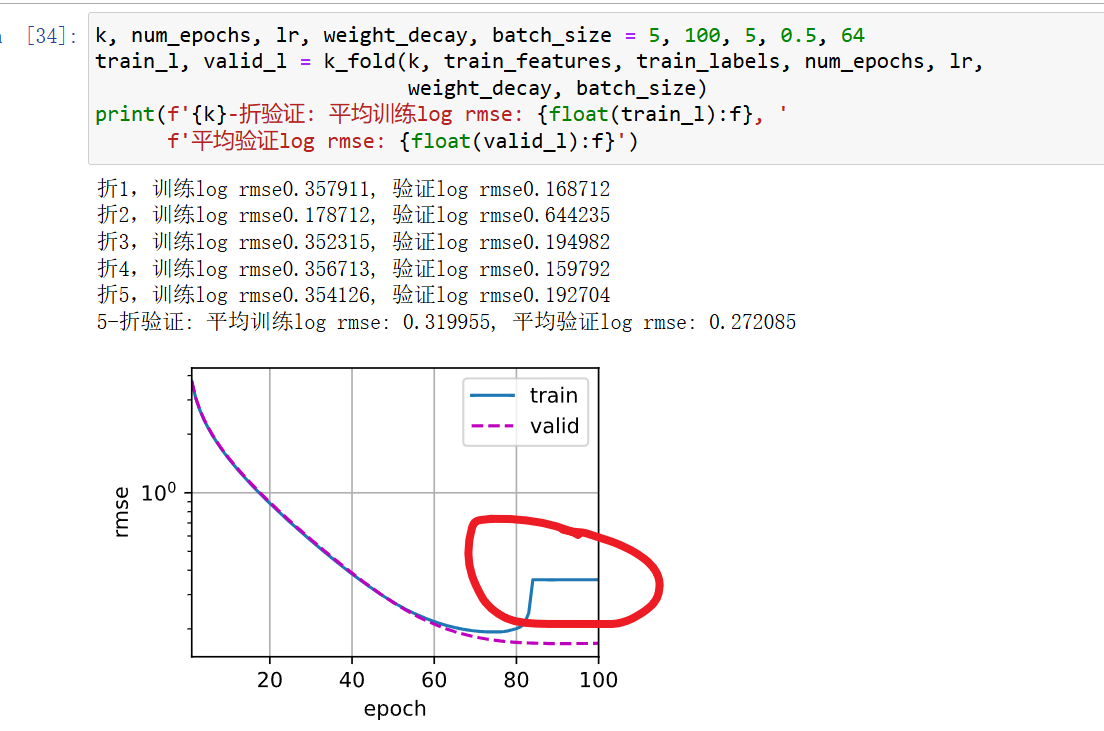
我觉得你说得很有道理,我用log_rmse调出来的参数上传到kaggle实际损失比测试的大,换成mse作损失函数就跟kaggle结果差不多了
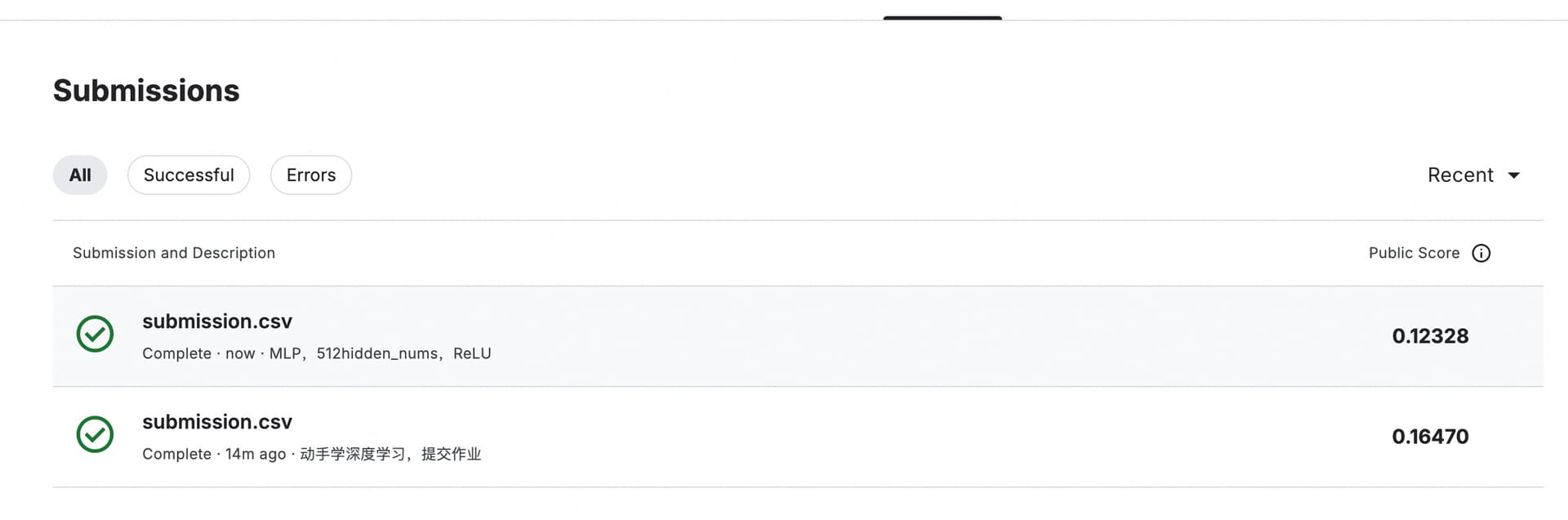
0.12328分的参数
num_folds = 5
num_epochs = 300
lr = 0.5
num_hiddens = 512
ReLU
batch_size = 512
weight_decay = 1000
1 Like
train_features = torch.tensor(all_features[:n_train].values,dtype=torch.float32)
TypeError: can’t convert np.ndarray of type numpy.object_. The only supported types are: float64, float32, float16, complex64, complex128, int64, int32, int16, int8, uint64, uint32, uint16, uint8, and bool.
object类没被剔除啊,没法转换类型
我在将损失函数改称相对误差之后,所有的预测值全部变成了 十量级…
只构建一次 net,意味着把验证集作为训练集了
训练用的还是MSELoss,但是验证那边用的是对数之后的MSELoss
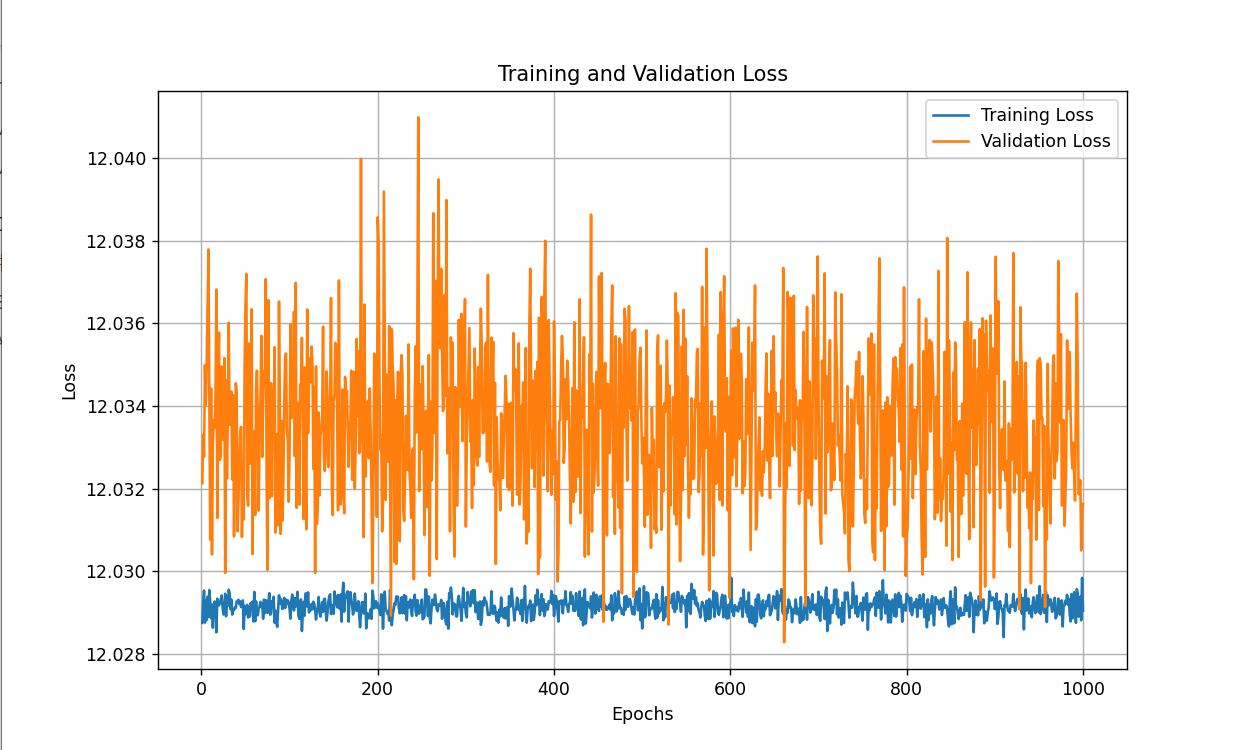
自己预测出来的怎么是这样的呀 应该怎么进一步改进呢?
代码如下:
-
定义 MLP 网络
class MLPRegression(nn.Module):
def init(self, input_dim, hidden_dim=128):
super(MLPRegression, self).init()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(64, 1) # 输出层
self.relu = nn.ReLU()def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = nn.Linear(128,64)(x)
x = self.relu(x)
x = self.fc2(x)return x
def log_rmse(output, labels):
# 为了在取对数时进一步稳定该值,将小于1的值设置为1
clipped_preds = torch.clamp(output, 1, float(‘inf’))
rmse = torch.sqrt(loss_fn(torch.log(clipped_preds),
torch.log(labels)))
return rmse.item()
l = nn.MSELoss()
2. 设置训练部分
def train_mlp(net, train_iter, val_iter, loss_fn, num_epochs, trainer):
train_losses = # 记录训练损失
val_losses = # 记录验证损失
for epoch in range(num_epochs):
net.train()
total_train_loss = 0.0
for X_batch, y_batch in train_iter:
trainer.zero_grad()
output = net(X_batch)
loss = log_rmse(output, y_batch)
l1 = l(output, y_batch)
total_train_loss += loss
l1.backward()
trainer.step()
# 记录训练损失
train_losses.append(total_train_loss / len(train_iter))
# 评估模型在验证集上的表现
net.eval()
total_val_loss = 0.0
with torch.no_grad():
for X_batch, y_batch in val_iter:
output = net(X_batch)
l2 = log_rmse(output, y_batch)
total_val_loss += l2
# 记录验证损失
val_losses.append(total_val_loss / len(val_iter))
# 每个 epoch 结束时打印损失
print(f"Epoch {epoch + 1}/{num_epochs}, Training Loss: {train_losses[-1]}, Validation Loss: {val_losses[-1]}")
# 返回训练和验证损失列表
return train_losses, val_losses
3. 准备数据
假设你已经准备好了 Xtrain, Ytrain, Xtest, Ytest 等训练和测试数据
4. 创建模型
input_dim = Xtrain.shape[1] # 输入特征的维度
net = MLPRegression(input_dim)
5. 选择损失函数和优化器
loss_fn = nn.MSELoss() # 用于回归任务的均方误差损失函数
lr = 1e-6 # 学习率
trainer = optim.Adam(net.parameters(), lr=lr) # 使用 Adam 优化器
6. 训练模型
num_epochs = 1000
train_iter = d2l.load_array((train_data, train_labels), batch_size=32)
val_iter = d2l.load_array((test_data, test_labels), batch_size=32)
train_losses, val_losses = train_mlp(net, train_iter, val_iter, loss_fn, num_epochs, trainer)
7. 绘制损失图像
plt.figure(figsize=(10, 6))
plt.plot(range(1, num_epochs + 1), train_losses, label=‘Training Loss’)
plt.plot(range(1, num_epochs + 1), val_losses, label=‘Validation Loss’)
plt.xlabel(‘Epochs’)
plt.ylabel(‘Loss’)
plt.title(‘Training and Validation Loss’)
plt.legend()
plt.grid(True)
plt.show()