如果在创建train_features时报错,是因为在get_dummies句因为pandas的新版本特性。pandas1.6.0之前get_dummies是返回np.uint8,1.6.0之后返回np.bool,如果仍要返回np.uint8,则应该指定dtype=np.int8或np.uint8
2 Likes
看一下我最新的发言,在get_dummies那句加个参数
在get_dummies之后使用all_features = all_features * 1也可以解决问题,将bool转换为int
1 Like
我的理解是如果训练用log_mse可能会导致模型“偷懒”,模型发现对于价格越高的房子他即使预测的偏差大一点也没事,虽然说在评估模型的时候我们知道对于价格高的房子预测偏差一两万是可以接受的,但是训练的时候还是希望模型能一视同仁地尽可能减小所有预测偏差?
1 Like
因为作者对输入特征值做了标准化,使得特征值较小,同时输出值房价较大,所以nn的权重都较大,所以学习率要相应较大才能加快收敛速度。我是这么理解的
next w = w - lr * dw
w很大,但求出的dw很小所以需要一个很大的lr
不知道这样理解对不对
2 Likes
def get_net2():
net = nn.Sequential(
nn.Linear(in_feature,256),
nn.ReLU(),
nn.Linear(256,1))
return net
起初出现训练误差和测试误差震荡,后来发现是学习率过大,导致步子迈的太大
怎么能把训练集和测试集一起做标准化呢?不是应该在训练集上fit,然后transform到测试集上?
Traceback (most recent call last):
File “/Users/yxiong/Documents/Personal/py/kaggle.py”, line 74, in
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: can’t convert np.ndarray of type numpy.object_. The only supported types are: float64, float32, float16, complex64, complex128, int64, int32, int16, int8, uint8, and bool.
这是啥情况,直接复制的代码
1 Like
大佬牛, ![]() 。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
独热编码的时候加个参数
all_features = pd.get_dummies(all_features, dummy_na=True,dtype=int)
1 Like
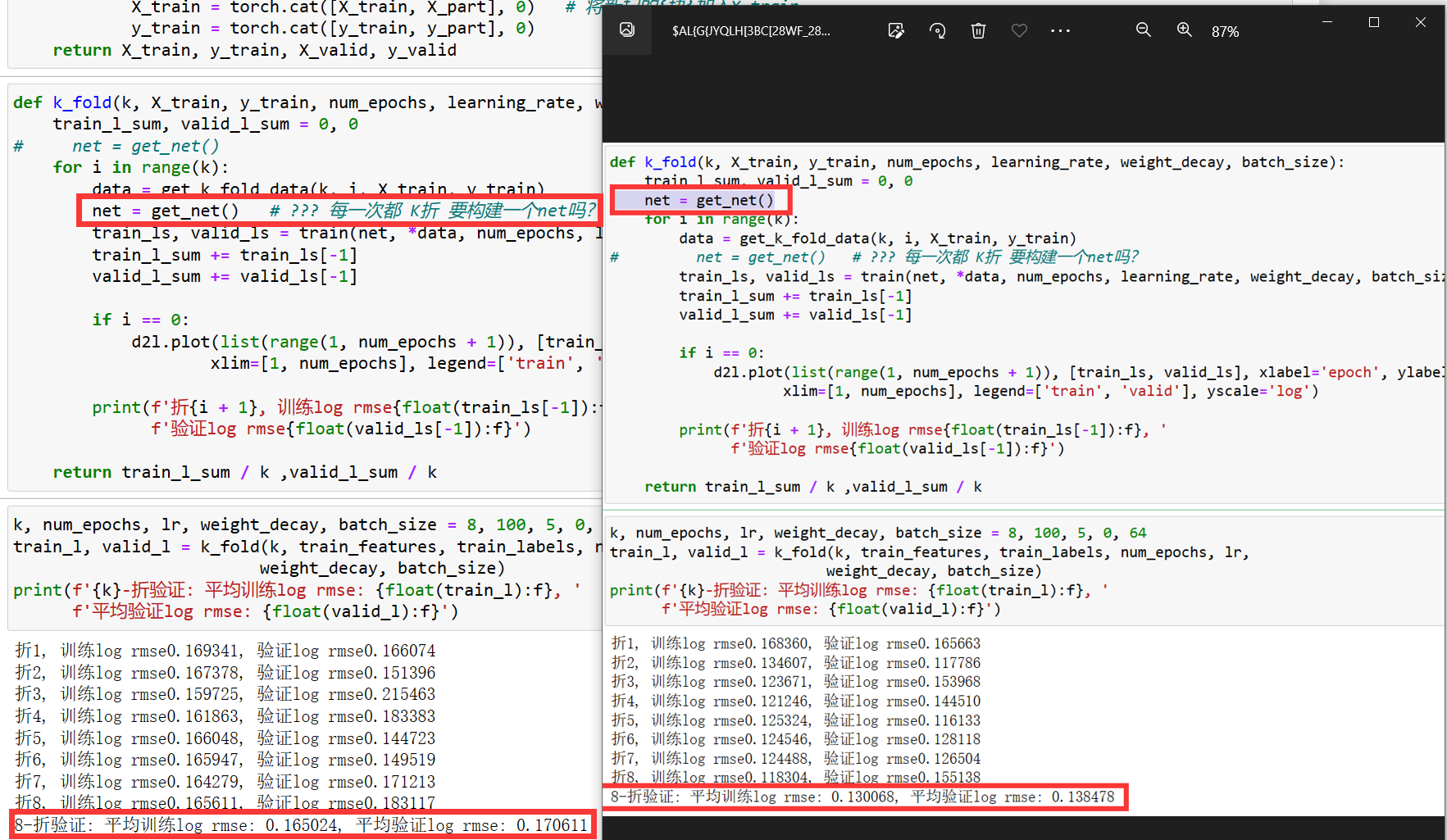
每一次k折都当成一次独立验证;如果使用同一个net,因为每一折都调用了train()-都有net的更新,那第i折的验证会受到j<i折验证的影响,使得验证相比实际理想化,
请问下这个问题怎么解决的呢 实在是不懂 -----------------------
可能是:
all_features里面有一个特征叫“MasVnrType(通常指的是:房屋的外部砌体类型,可以取BrkCmn: 表示砖石/水泥混凝土块砌体;BrkFace: 表示砖石/水泥混凝土表面层;CBlock: 表示水泥块;None: 表示没有外部砌体。
Stone: 表示石头。)”
在all_features里面,MasVnrType特征有5种取值:BrkCmn; BrkFace; NA; None; Stone,这里面NA表示的是缺失值,None表示的是没有外部砌体,但有些python版本会把NA和None都视为缺失值,这导致None类型被错误理解为缺失值。
解决:考虑将MasVnrType特征中取值为None的元素标记成一个不同的值,比如 “None_fea”,以明确表示这是一个有意义的取值而不是缺失值。
1 Like

pandas混淆了NA和None,没有把他们区分开来,而是归属于MasVnrType_nan
解决方法:
将None值转换为字符串"None"
all_features.fillna({‘MasVnrType’: ‘None’}, inplace=True)
1 Like
应该是这样的all_features.replace('None', 'None_fea', inplace=True)