HikariS
August 10, 2023, 11:09am
56
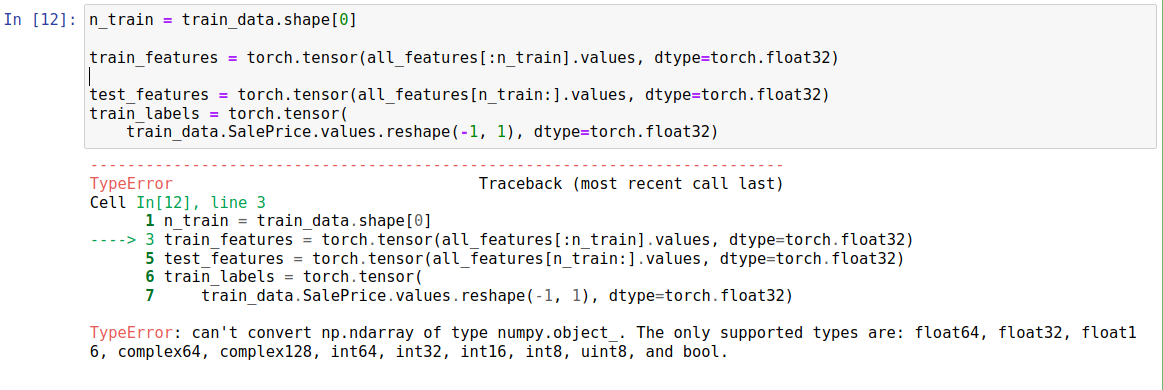
TypeError Traceback (most recent call last)
TypeError: can’t convert np.ndarray of type numpy.object_. The only supported types are: float64, float32, float16, complex64, complex128, int64, int32, int16, int8, uint8, and bool.
1 Like
weiking
August 18, 2023, 11:15am
58
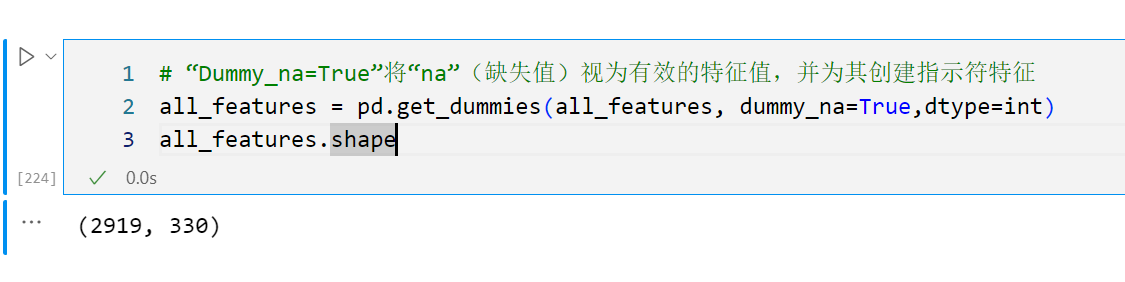
某些ide独热编码时会将数据处理成boolean类型,需要指定处理类型为数值型,如int。尝试这么处理,pd.get_dummies(all_features, dummy_na=True, dtype=int)
3 Likes
wo我也是这个问题,但是独热编码之后我是330个,不是331个。是哪里出问题了呢
某些ide独热编码时会将数据处理成boolean类型,需要指定处理类型为数值型,如int。尝试这么处理,pd.get_dummies(all_features, dummy_na=True, dtype=int) 摘自weiking大佬的回答,亲测有效。
跟着大佬改的参数
1 Like
我也有一样的疑问,这样修改了之后,记得修改一下rmse函数的返回值,去掉.item(),不然返回的是不包含梯度等信息的float类,需要返回tensor类型的才能调用backward计算梯度
def log_rmse(net,features,labels):
pred = net(features)
clamped_pred = torch.clamp(pred,min=1)
rmse = torch.sqrt(loss(torch.log(clamped_pred),torch.log(labels)))
return rmse
在下面的代码中,请问这个哈希值是怎么得到的,自己算吗?@save
不对,
没太理解,你说的是房价预测的数据集吗?可是我看get_dummies后的数据集大小只有1.6MB,内存8G的电脑也可以跑起来呀
如果在创建train_features时报错,是因为在get_dummies句因为pandas的新版本特性。pandas1.6.0之前get_dummies是返回np.uint8,1.6.0之后返回np.bool,如果仍要返回np.uint8,则应该指定dtype=np.int8或np.uint8
看一下我最新的发言,在get_dummies那句加个参数
在get_dummies之后使用all_features = all_features * 1也可以解决问题,将bool转换为int
1 Like
我的理解是如果训练用log_mse可能会导致模型“偷懒”,模型发现对于价格越高的房子他即使预测的偏差大一点也没事,虽然说在评估模型的时候我们知道对于价格高的房子预测偏差一两万是可以接受的,但是训练的时候还是希望模型能一视同仁地尽可能减小所有预测偏差?
1 Like
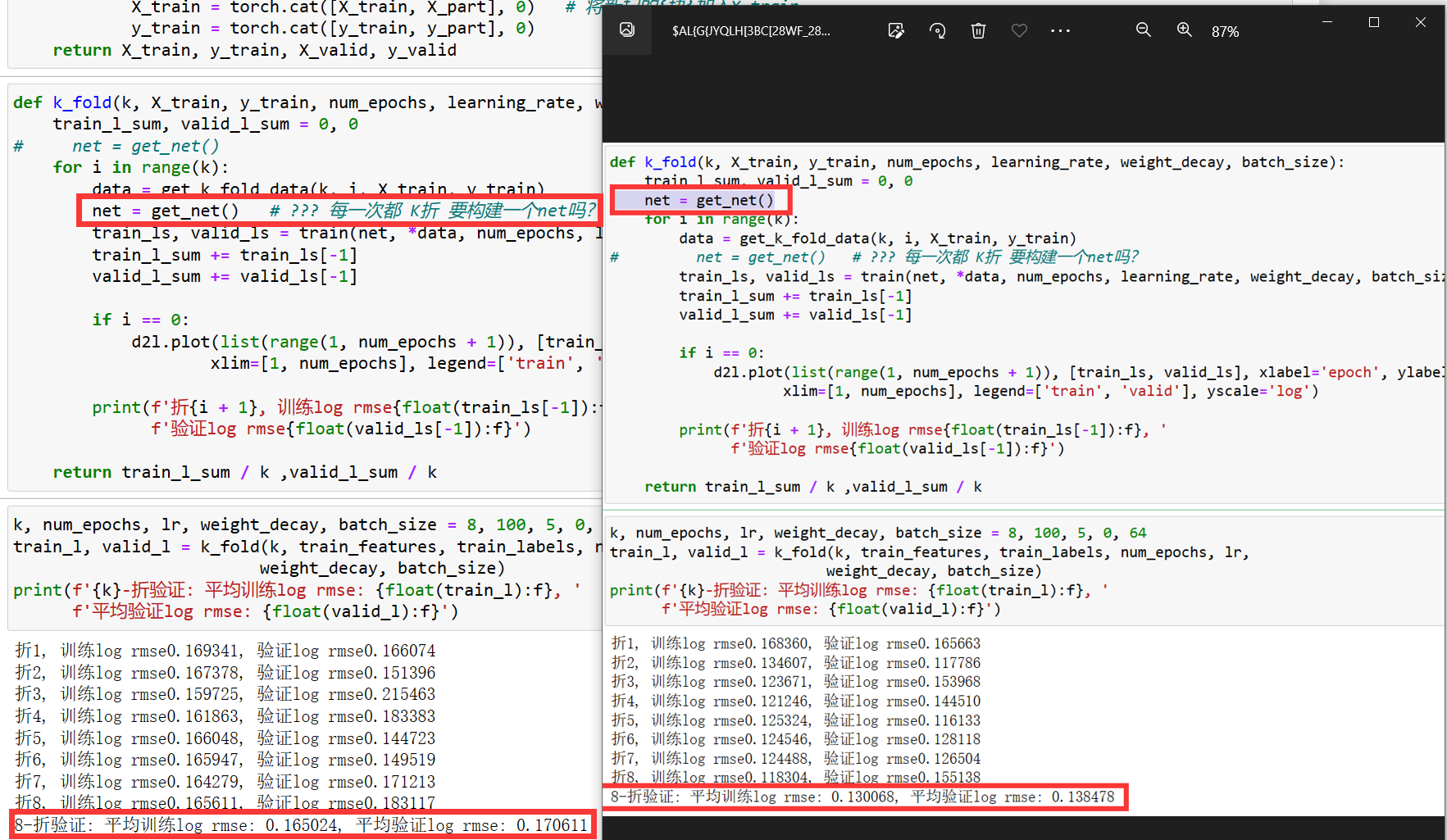
我不太明白为什么这里每一次K折都要构建一个net来训练?
因为作者对输入特征值做了标准化,使得特征值较小,同时输出值房价较大,所以nn的权重都较大,所以学习率要相应较大才能加快收敛速度。我是这么理解的
next w = w - lr * dw
Wen_Kai
December 5, 2023, 2:43am
75
def get_net2():
net = nn.Sequential(
nn.Linear(in_feature,256),
nn.ReLU(),
nn.Linear(256,1))
return net
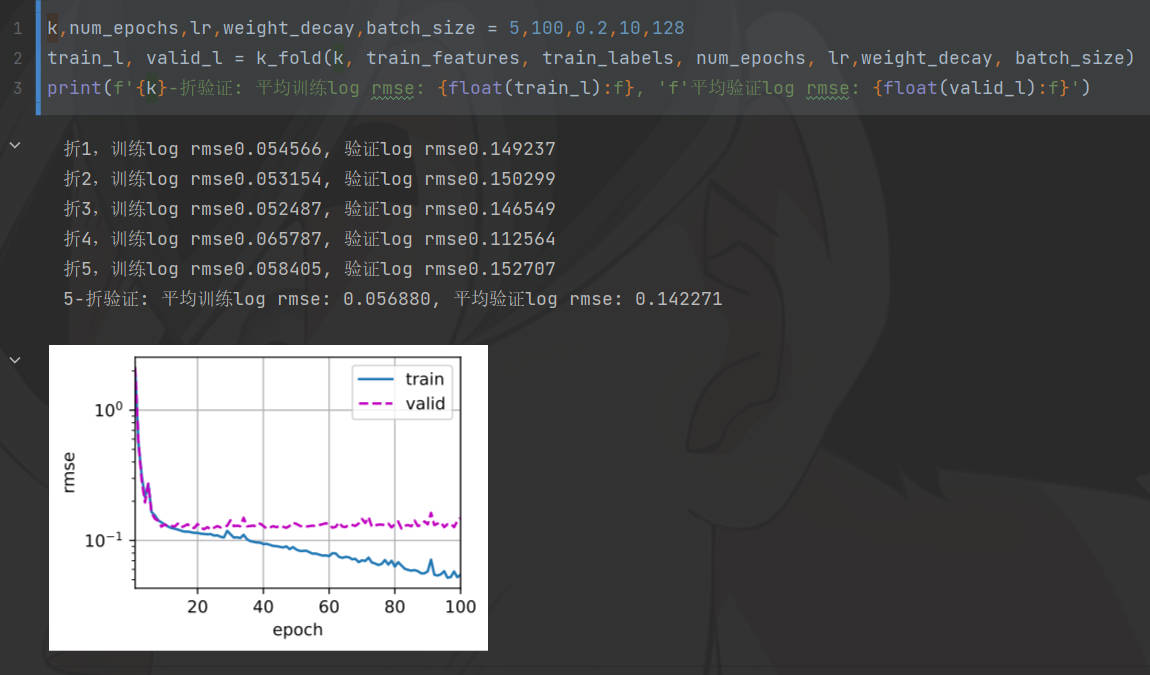
起初出现训练误差和测试误差震荡,后来发现是学习率过大,导致步子迈的太大
怎么能把训练集和测试集一起做标准化呢?不是应该在训练集上fit,然后transform到测试集上?