经过资料找后,找到问题原因:nn.CrossEntropyLoss(reduction=‘none’)原loss函数缺少了reduction=‘none’,导致没有train_loss曲线,添加后可以正常输出。
1 Like
pycharm不会内置matplotlib,可以在最前面加一行,import matplotlib.pyplot as plt,在最后加一行plt.show()
1 Like
对于nn.CrossEntropyLoss()之类的loss,括号内不可以使用reduction=‘none’, 否则会报错RuntimeError: grad can be implicitly created only for scalar outputs, 我也不懂原因,找了好久资料
1 Like
请问简洁实现的代码,为什么在测试中就不利用dropout层了呢?也没有相关代码说明了在测试中忽略了这两层
1 Like
请问你说的老师的视频在哪里可以看,可以的话能给个观看地址吗
应该是指李沐的,b站一搜就有,李牧学AI
1 Like
这个涉及到数据在统计上面的一些性质,我们在dropout的时候,是随机丢掉了一些数据,那么这样的话就会造成一些问题:丢掉之后,数据和之前已经不是一个东西了,但是我们可以使得数据在期望意义下保持相同,数据量毕竟非常的大,我们在均值意义上保持相同,那么dropout和没有使用dropout至少在均值意义下是相同的,这是我的一些拙见
主要原因是最早做机器学习的那帮人就是这么翻译的,所以大家只好跟着一起叫了,如果你是某个领域最牛逼的那么你就有定义权
1 Like
您好关于这个模型复杂度的问题可以去看看VC维相关的文章,如何基于统计学来衡量一个模型的复杂度,但是由于深度学习模型越来越复杂,目前来看并没有合适的单一指标能来衡量一个深度模型的复杂度,但是可以从模型的深度和结点的数量的量级来判断模型的复杂性
1 Like
就是李沐的视频,在b站,搜李沐就可以找到,视频合集是动手学深度学习pytorch版
1 Like
1 Like
T5
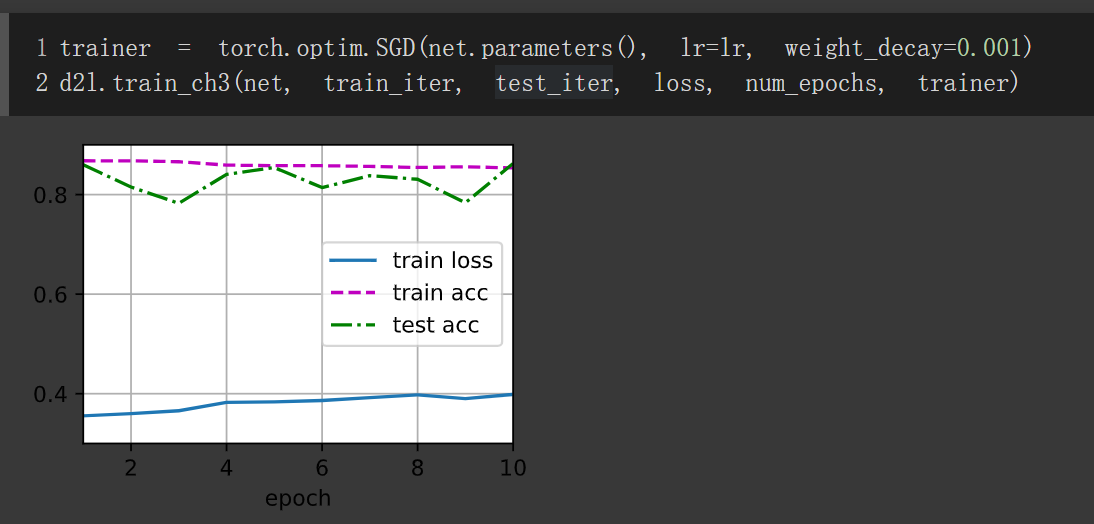
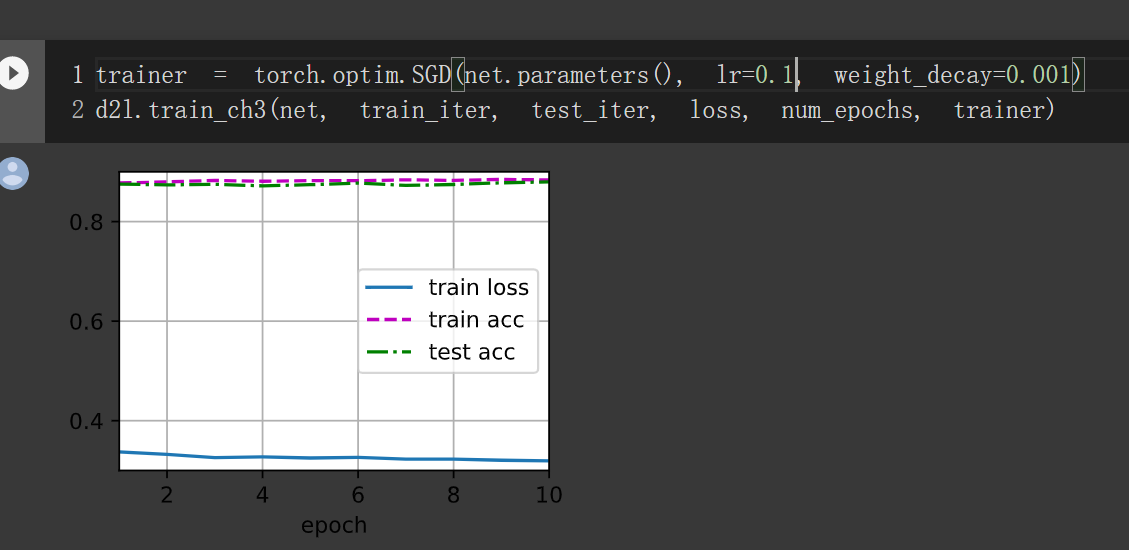
增加衰减只需要设置torch.optim.SGD的weight_decay参数即可。
设置参数,实验结果如下
单独使用暂退法
lr = 0.5
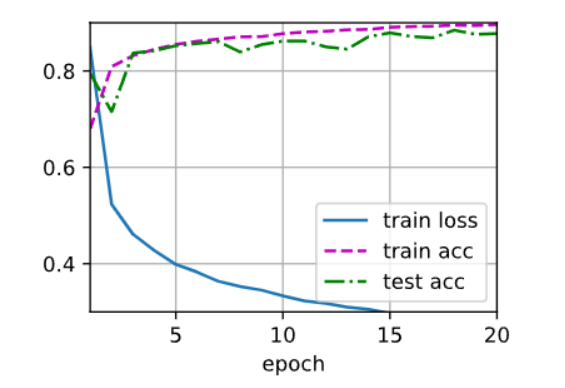
单独使用权重衰退
lr = 0.5, weight_decay = 0.01
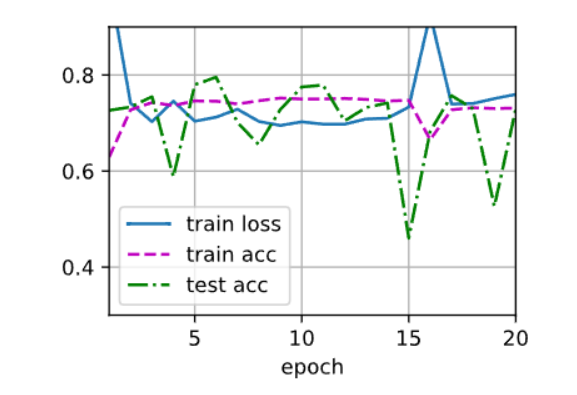
调整学习率到0.1单独使用权重衰退,lr = 0.1, weight_decay = 0.01
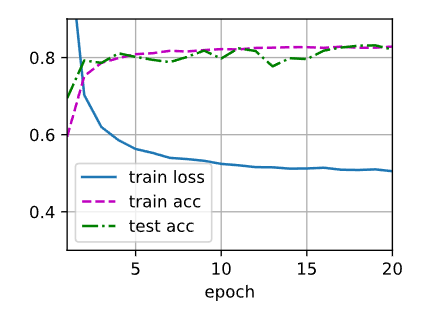
同时使用暂退法和权重衰减:
lr = 0.5, weight_decay = 0.01
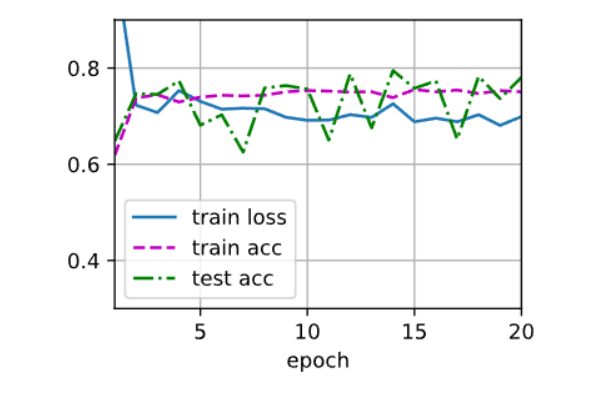
调低学习率后好了一点点,lr = 0.1, weight_decay = 0.01
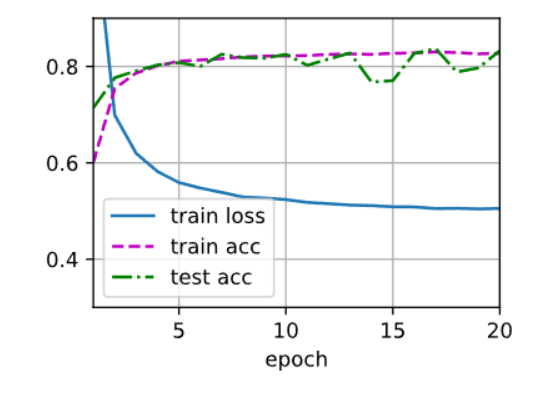
有大佬说lr与weight_decay差两到三个数量级是最好的,lr = 0.1, weight_decay = 0.001,发现又好了一些
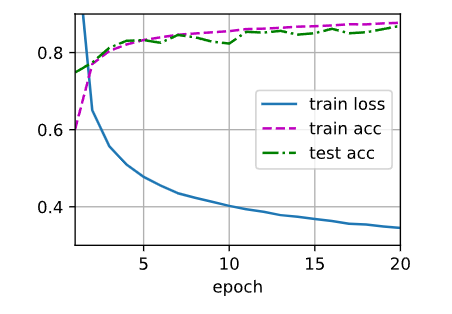
lr = 0.1, weight_decay = 0.0001
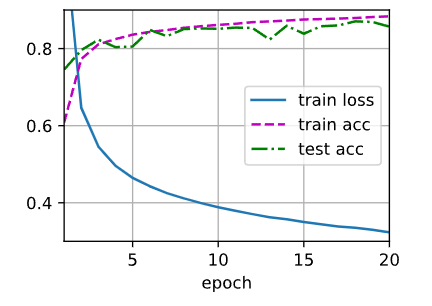
通过做实验发现:
- 同时使用暂退法和权重衰减的收益确实是累加的,会比单独使用好一些。
- 对于暂退法和权重衰减的比较来说,还需要调整学习率等参数才能实现更好的效果。
借用上面大佬的话说,暂退法是引入一定的噪声,增加模型对输入数据的扰动鲁棒,从而增强泛化;权重衰减在于约束模型参数防止过拟合。
实验做得不妥的地方,请大佬指正!
4 Likes
我也遇到了这个问题,你只需要把y轴设置到[0,3]就可以了
“ 当应用或不应用暂退法时,每个隐藏层中激活值的方差是多少?绘制一个曲线图,以显示这两个模型的每个隐藏层中激活值的方差是如何随时间变化的。”每个batch有256个样本,每个样本在隐藏层1和隐藏层2都有256个激活值。那这道题的意思是比较应用或不应用dropout时,“所有样本在隐藏层1和隐藏层2的方差”的均值 随着epoch的变化吗?
我理解丢掉的一部分节点,需要通过保留的那部分找补回来
以后面的代码为准,此处有些许bug,哎嘿 ![]()
本人代码
# QA3
epochs, lr, batch_size = 10, 0.5, 256
train_iter,_ = d2l.load_data_fashion_mnist(batch_size)
dropouts = [[0, 0], [0.2, 0.4]]
variances = []
for dropout in dropouts:
var_s = []
dropout1 = dropout[0]
dropout2 = dropout[1]
nets = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Dropout(dropout1),
nn.Linear(256,256),
nn.ReLU(),
nn.Dropout(dropout2),
nn.Linear(256,10))
nets.apply(init_weight)
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(nets.parameters(),lr)
for epoch in range(epochs):
for x, y in train_iter:
var = []
for net in nets:
if type(net) == torch.nn.modules.flatten.Flatten:
out = net(x)
else:
out = net(out)
if type(net) == torch.nn.modules.activation.ReLU:
var.append(float(torch.var(net(out)).detach().numpy()))
var_s.append(var)
l = loss(out, y)
trainer.zero_grad()
l.mean().backward()
trainer.step()
variances.append(var_s)
import numpy as np
each_iter = np.arange(len(var_s))
variances = np.array(variances)
d2l.plot(each_iter, [variances[0][:,0], variances[0][:,1], variances[1][:,0], variances[1][:,1]],
'each_iter','variance',
legend=['No dropout-relu1', 'No dropout-relu2', 'dropout-relu1','dropout-relu2'],
figsize=(6,3))
# 可以看出加了dropout,方差减小,缓和过拟合现象
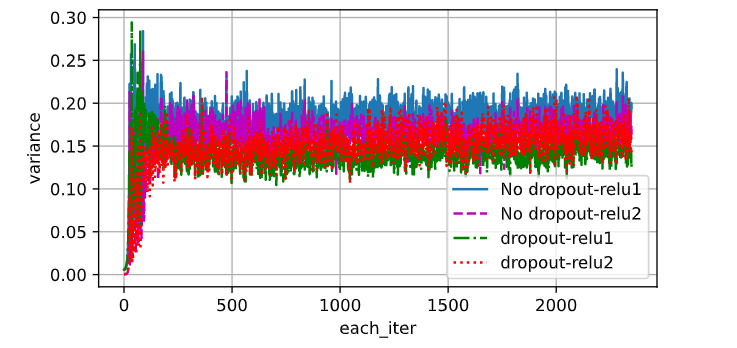
3 Likes
dropout把会把部分输出设置为0,relu在0点不可导。个人觉得是这个原因。
1 Like