https://zh.d2l.ai/chapter_multilayer-perceptrons/dropout.html
1 Like
请问在init_weights中,为什么只对weight初始化而没对bias进行初始化呢?
2 Likes
请问 dropout 公式那里,对于h,为什么要除以一个1-p.
对应的原文是“通过按保留(未丢弃)的节点的分数进行归一化来消除每一层的偏差”。
该如何理解?
1 Like
参考一下nn.Linear()的文档,这个函数自动会对w和b进行uniform的初始化。这里是想要把w改成高斯分布才特意强调的。
4 Likes
按照老师的视频的说法,是为了保持期望一致。所以除以1-p
2 Likes
那在实际的使用中, 如果没有特殊的要求, 其实都不需要对 wb 进行初始化?
不,实际使用中,你对weight初始化换成xavier可能都会有20%的精度提升,工程中使用合适的初始化很重要。
5 Likes
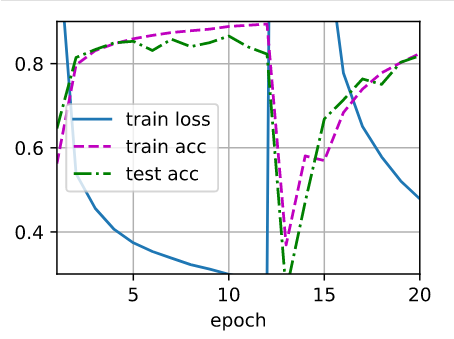
请问第六问,为什么把dropout放到relu前面后会这样啊
1 Like
这个是不是随机出现的?我试了几次没有发生这种情况哎 按理说放前后是一样的 你再试试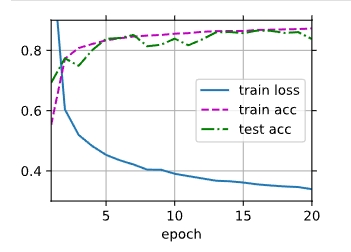
2 Likes
Q1,做出来的结果,在调换D1和D2层概率后,基本没有什么变化,但是改变第一层和第二层的概率总和后,结果会有明显的变化,猜想是在概率总和一样的情况下,不会对最后的准确率造成太大的影响?(对此我不太敢相信我的结论,希望大家指点)
Q2,没有dropout的训练效果会更好,但是泛化性不够好。
Q3,没画出来,求大佬帮助实现代码
Q4,因为测试的时候更关注整个模型的泛化度
Q5,同时使用效果反而会变差
Q6,train_loss会下降的比较慢,达不到原本的train_loss。
2 Likes
请问自己实现Net类里,def 的forward()函数是怎样被调用的?在训练的代码里没有找到调用,但是实际训练时却被运行了
3 Likes
自己实现的Net类继承了nn.Module类,这是PyTorch中所有网络的父类。在nn.Module中有一个__call__()方法,它相当于C++中的重载()运算符,当我们执行 类名() 这种样式的语句时就会调用__call__(),而在该方法中就有调用forward()。在自定义Net类中我们def的forward()相当于重载了父类nn.Module中的forward()方法,同时自定义Net类也继承了父类的__call__(),因此在执行Net(input)这样的语句时Net类的__call__()被调用,连带着其中的forward()也被调用了,表现出来的就是使用Net(input)时forward()被运行。
参考链接: https://blog.csdn.net/weixin_41912543/article/details/108147378
15 Likes
为什么不显示图片,而是<Figure size 350x250 with 1 Axes>
如果用VS,加一条:d2l.plt.show(),就会显示图片结果。
1 Like
Exercise1:
原始图
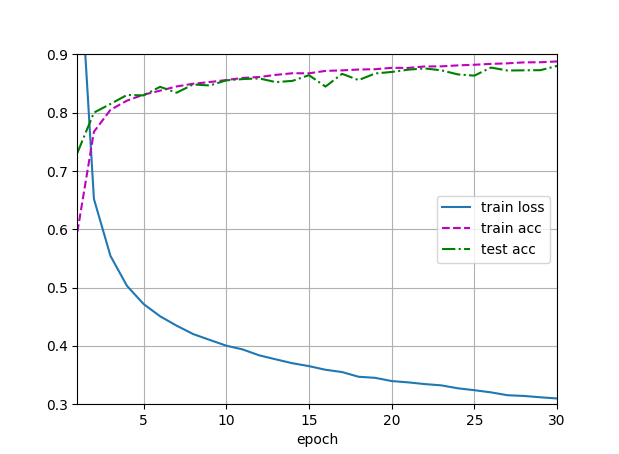
交换概率

dropout1, dropout2 = 0.5, 0.2 明显比dropout1, dropout2 = 0.2,0.5 好些, 后者Gap在后期训练时增加(过拟合)。
Exercise2: Adding Epoch to 30
没有Dropout
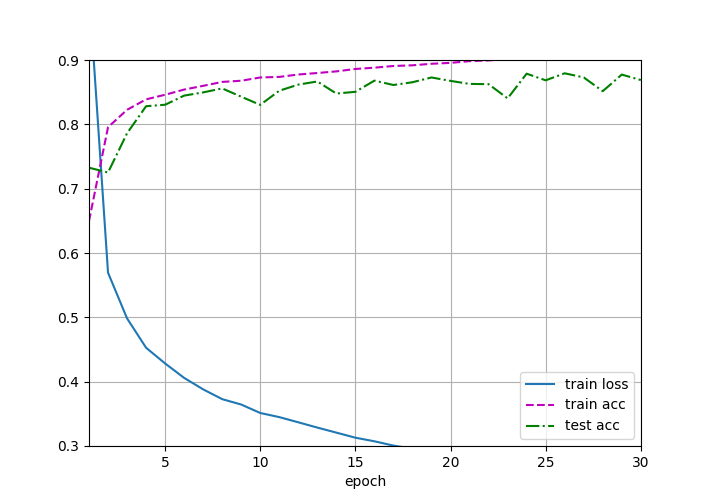
有Dropout

后者比前者好,前者有明显gap (过拟合)
1 Like
您好,有没有简单的方法,将现在这个程序改到GPU上面运行呢,我修改了模型.to.cuda,但是数据改不过去,经过调试发现模型在gpu上面,但是数据不知道如何修改,我确保CUDA是可用的,其他代码已经试验过
在交换概率的时候并没有发生明显的变化,你的是不是可接受误差范围内?
1 Like
对模型训练和测试,出现报错:
RuntimeError: DataLoader worker (pid(s) 12512, 9888, 10924, 12184) exited unexpectedly
请问如何处理
为啥我没有train loss 的曲线啊
我可不可以理解,暂退法是在复杂模型计算时,降低模型的复杂性,从而降低过拟合的可能性
2 Likes