panghu8
22
在自定义的 dropout_layer 中
mask = (torch.rand(X.shape) > dropout).float()
使用如下:
mask = torch.where(torch.rand(X.shape) > dropout, 1.0, 0.0)
或更直观?
在 class Net(nn.Module) 中
if self.training == True:
pass
直接写成:
if self.training:
pass
或可?
1 Like
peng123
23
net = nn.Sequential(nn.Flatten(),
nn.Linear(784,256),
nn.ReLU(),
# 在第一个全连接层之后添加一个dropout层
nn.Dropout(dropout1),
nn.Linear(256,256),
nn.ReLU(),
# 在第二个全连接层之后添加一个dropout层
nn.Dropout(dropout2),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128,10),
)
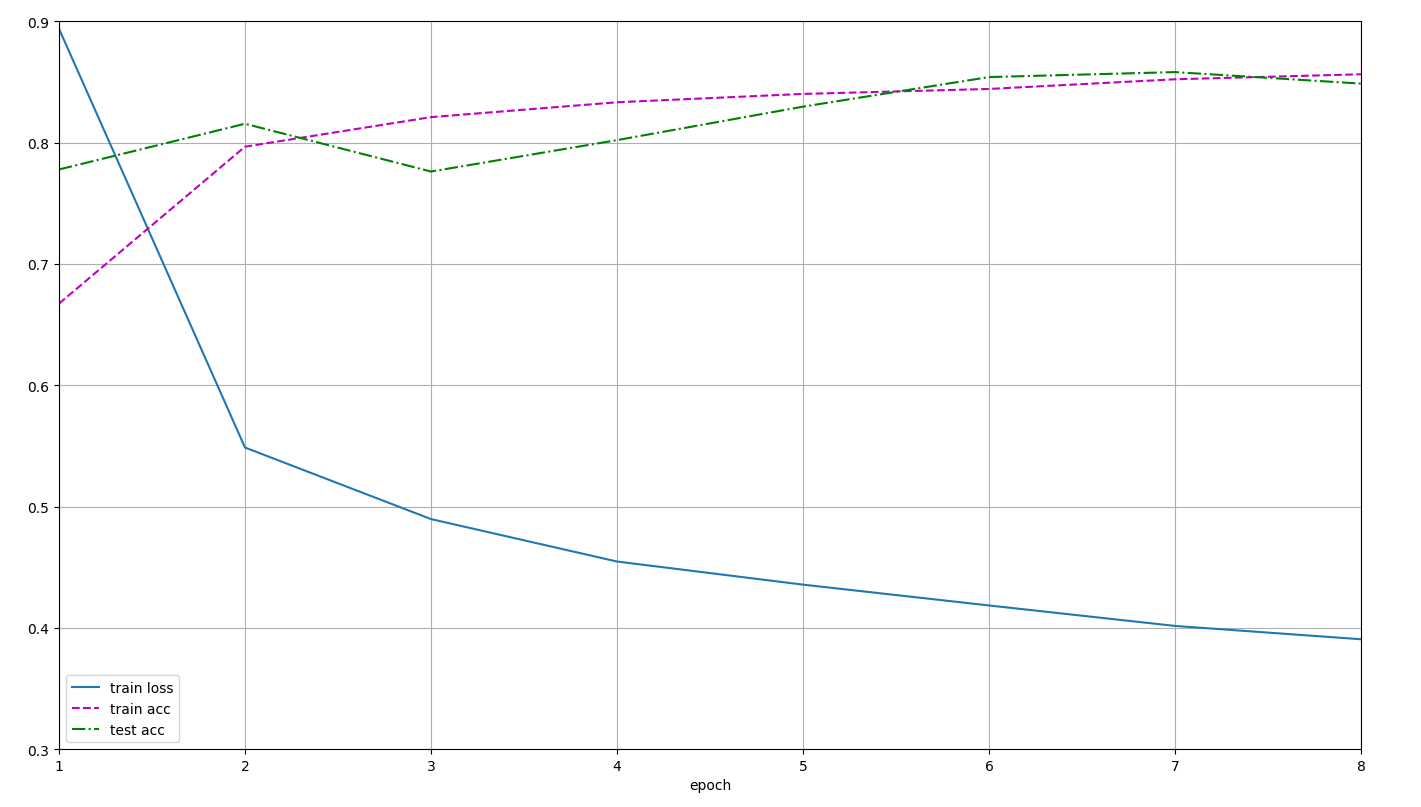
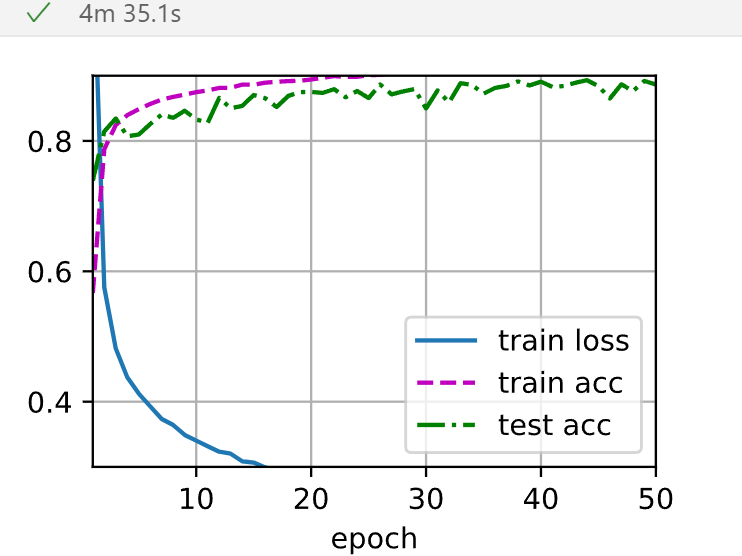
老师同学们好,我把两个隐藏层改成三个隐藏层,想请问一下:
1.为什么第一次运行和第二次运行差别这么大?
2.怎么修改图片的坐标轴啊?第一次的结果loss和acc的初始值都不在图片之内?
非常感谢!!!
第一次:
我个人的理解权重衰减法是降低模型的复杂性,因为如果模型越复杂,也就是阶数越高,L2范数正则项就会越大,这种方法使得阶数越高权重衰减越快,从而减低模型的复杂性。
而暂退法我认为实际上可以理解是一种脱敏法,也就是说你的输出结果不能完美拟合所有的输入,换句话说你的拟合效果不能对于每个数据都过分敏感。这种过分敏感会导致过拟合。因此加入Dropout层,在每一次遍历你的数据的时候,模型不会完全依靠所有神经元的激活结果进行调整,而是扔掉其中的一部分,用新的神经元组合来进行拟合。就像书中说的,暂退法的核心理念其实是加入噪声,从而增加模型的平滑度。
9 Likes
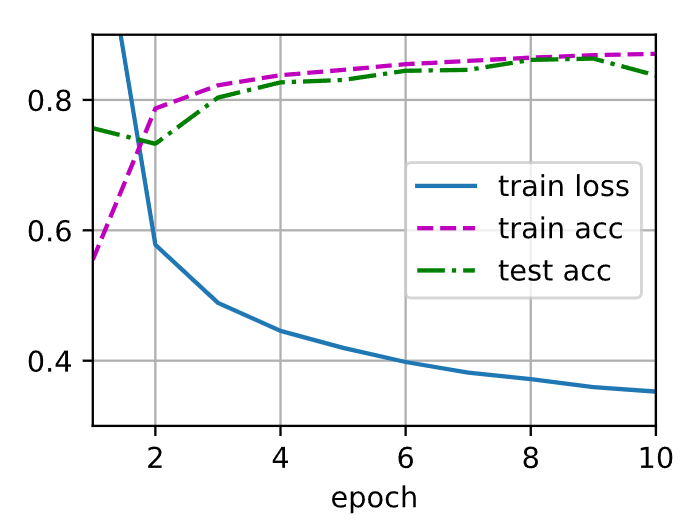
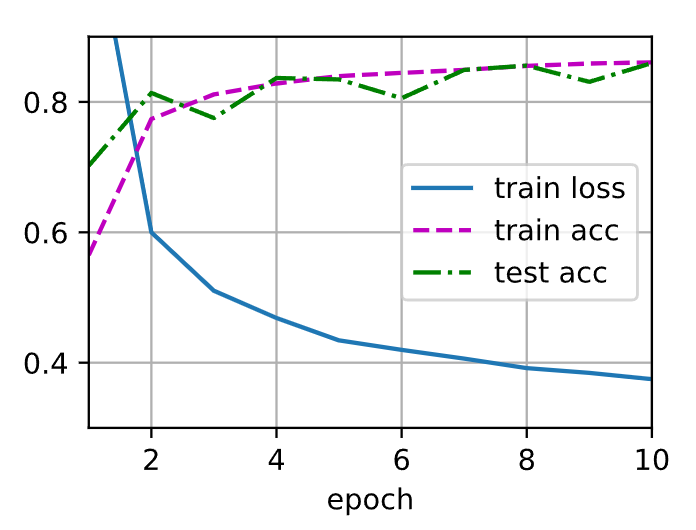
将dropout1和dropout2的概率值互换后(0.5, 0.2)感觉差别不是很大(当次数为8)
2 Likes
这是因为你在第一训练的基础上进行了第二次训练,这就会导致你的结果会继续上一次的模型参数进行继续训练,如果你想得到和第一次训练一样的结果,那就把参数重新初始化一下,然后在进行训练
2 Likes
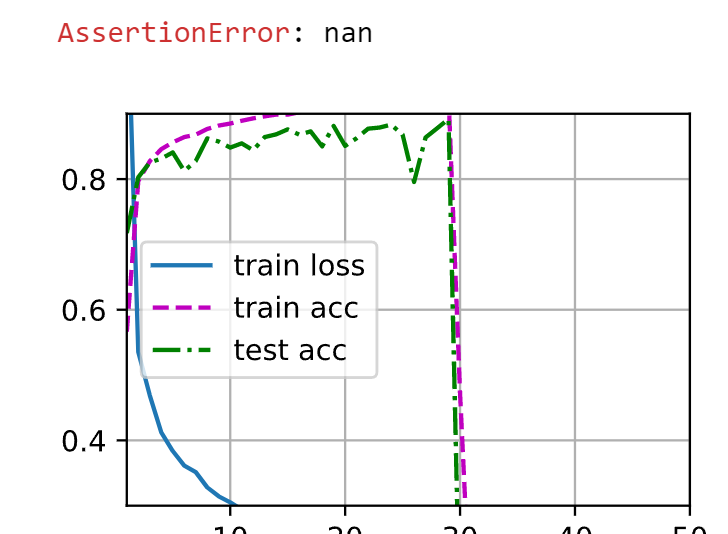
新版代码报错
grad can be implicitly created only for scalar outputs
如何修改?
error grad can be implicitly created only for scalar outputs
when using nn.CrossEntropyLoss(reduction=‘none’)
删去reduction=‘none’ 正常了
这里面的原因能请教一下吗?谢谢
1 Like
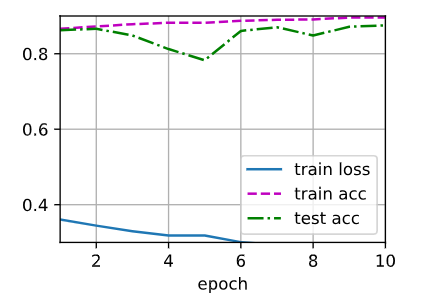
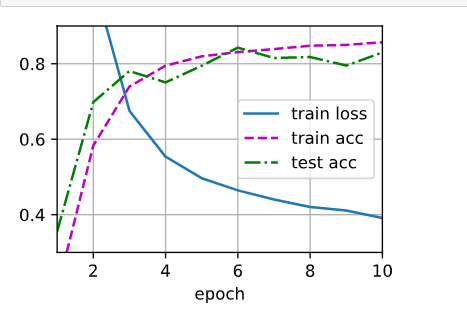
我在使用d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)的时候,loss曲线总是不显示怎么办,求大佬解答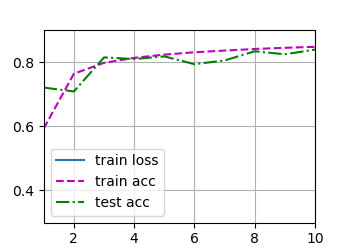
dgw
34
torch 简洁版本
`# 简洁实现 dropout
net = nn.Sequential(nn.Flatten(),
nn.Linear(784,256),
nn.ReLU(),
# 对一个隐藏层添加 dropout
nn.Dropout(p=0.5),
nn.Linear(256,256),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(256,10))
def init_weight(w):
if type(w) == nn.Linear:
nn.init.normal_(w.weight,std=0.01)
net.apply(init_weight)
num_epochs, lr, batch_size = 10, 0.5, 256
train_iter,test_iter=d2l.load_data_fashion_mnist(batch_size)
loss = nn.CrossEntropyLoss(reduction=“none”)
updater = torch.optim.SGD(net.parameters(),lr=lr)
d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,updater)`
修改epoch后图像显示不全,不会改调用模块的坐标。会改matplotlib的
你需要自己运行一下,可以点 kernel—> restart & run all
1 Like
为什么这些书都要把regular翻译成正则,那这和机翻有什么区别。英语中regular有简单的意思,所以翻译成简单化不好理解吗???为什么不说人话??? 
1 Like
因为你第二次运行没有重置模型参数。你是在第一次训练完后继续训练的
1 Like
4.6.2 "我们在4.4节讨论线性模型的单项式函数时探讨了这⼀点。此外,正如我们在4.5节中讨论权重衰减(L2正则化)时看到的那样,参数的范数也代表了⼀种有⽤的简单性度量。"这句话中表明范数是对模型简单性(复杂性)的度量,我想这是一个很关键的问题:对于模型复杂度的度量。请问关于这个问题是否有些不错的文章,综述推荐?谢谢!
1 Like
请问这个train_loss曲线无法显示的问题解决了嘛?我在训练时也出现了没有train_loss曲线的问题。
各位大神,咨询一个问题。在做dropout练习的时候,出现train_loss曲线无法显示的问题,如下图所示。
不知道如何解决,请指点一下,谢谢!