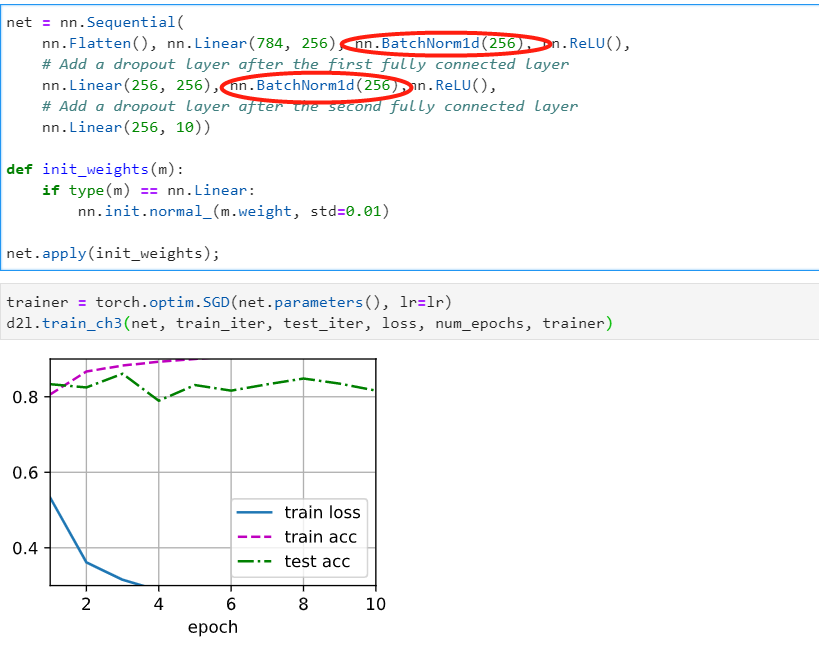
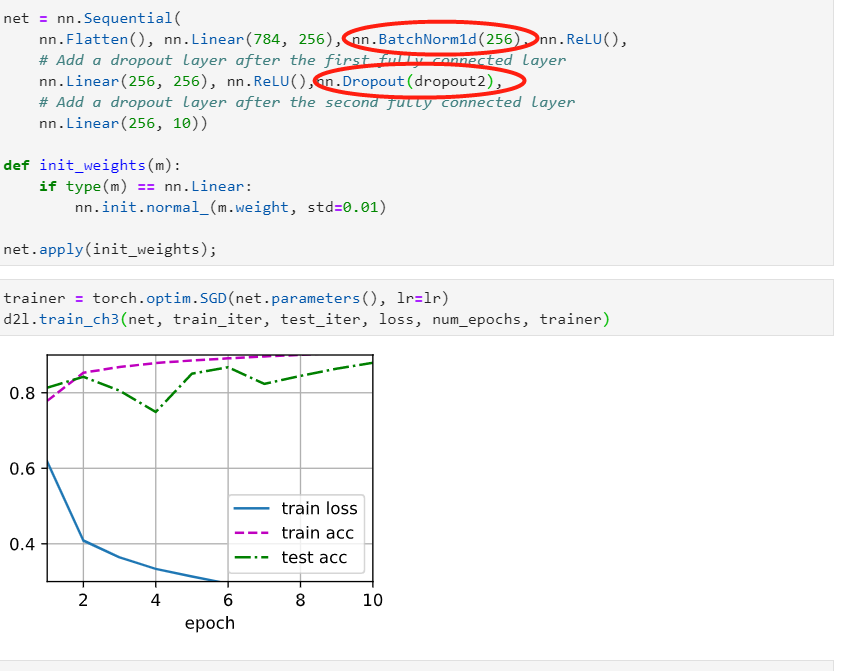
Is there any trick when applying dropout for improving (test) accuracy? – In this example, by using the dropout approach, the test accuracy on the Fashion-MNIST dataset does not get improved compared to the MLP approach in section 4.3
Specifically, denote gap = accuracy_train (A1) - accuracy_test (A2). By using dropout, I would expect a smaller gap and a smaller A1 due to the regularization property of the dropout. Hence there should not always be guaranteed that the test accuracy A2 will increase.
Hey @Angryrou, yes you supposition is right! We cannot promise there is always an increase of test accuracy. However, what dropout ultimately does is to overcome “Overfitting” and stabilize the training. Once your model is overfitting (like the mlp example), dropout can help.
In practice, we usually use a dropouts of 0.2 - 0.5 ( 0.2 recommended for input layer). Too low dropout cannot have regularization effect, while a too high dropout may lead to underfitting.
Could you explain more on how the dropout stabilize the training? I do find it more stable in terms of the variance of the activations in each hidden layer (from the exercise 3), but cannot figure out the reason behind. Any intuitive explanation or references should be very helpful!
Hi @Angryrou, here are some intuitions. We pick random neurons to dropout at each epoch, so the layer won’t really too much on one or two specific neuron (i.e., all other neurons have a closed to zero weights)
Suppose we have 4 neurons at one layer, A, B, C, D. With some random unexpected initialization, it is possible that the weights of A & B are closed to zero. Imagine the following two situations:
If we don’t have dropout, this layer only relay on neurons C & D to transform information to the next layer. So the neurons A & B might be too “lazy” to adjust its weight since there are C & D.
If we set dropout = 0.5, then at each epoch, two neurons are dropped randomly. So it is possible that both C and D are dropped, so A & B have to transform information and adopt the gradients weights adjustment.
Thanks again for the reply. However, I still have some follow up issues unclear:
Without the dropout in your example, only 2 of the 4 neurons take effects mostly. In other words, the model may have less representation property (due to smaller capacity in the model) without using dropout. So my understanding from your example is: a model with more capacity should be more stable than a model with less capacity. Is my statement correct?
I do not think A & B will be too “lazy” to adjust weights. Assume the model is y = f(X) = A * x_1 + B * x_2 + C * x_3 + D * x_4, the gradient on A is dl/dy * dy/dA and the dy/dA = x_1, so the adjustment on A is mainly rely on the feature x_1 instead of the value of A.
Without the dropout in your example, only 2 of the 4 neurons take effects mostly. In other words, the model may have less representation property (due to smaller capacity in the model) without using dropout. So my understanding from your example is: a model with more capacity should be more stable than a model with less capacity. Is my statement correct?
We don’t dropout during inference, so we still have 4 neurons to keep the original capacity.
I do not think A & B will be too “lazy” to adjust weights. Assume the model is y = f(X) = A * x_1 + B * x_2 + C * x_3 + D * x_4 , the gradient on A is dl/dy * dy/dA and the dy/dA = x_1 , so the adjustment on A is mainly rely on the feature x_1 instead of the value of A.
Your intuition is right! Theoretically it depends on the input features and the activation function. So the dropout method “force” the neurons A&B to learn if their features are not as effective as the other neurons’ features.
what dropout ultimately does is to overcome “Overfitting” and stabilize the training.
Do you have any recommended papers or blogs that have theoretical support about how dropout can help stabilize the training (e.g., avoid gradient explode and varnish)? I find this is very interesting to explore.
For any ML problem, we ultimately care about the model performance through evaluation metrics (such as accuracy). However, lots of metrics are not differentiable, hence we use the loss functions to approximate them.
We use loss function just for training’s Backpropagation, and we don’t need to train anymore when we are in test. Similiarly, we just care the final scores of exam instead of the concrete answers.
Do I understand it rightly?
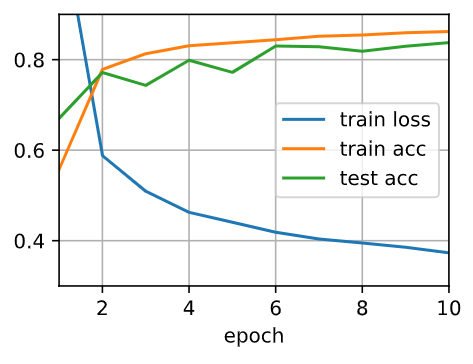
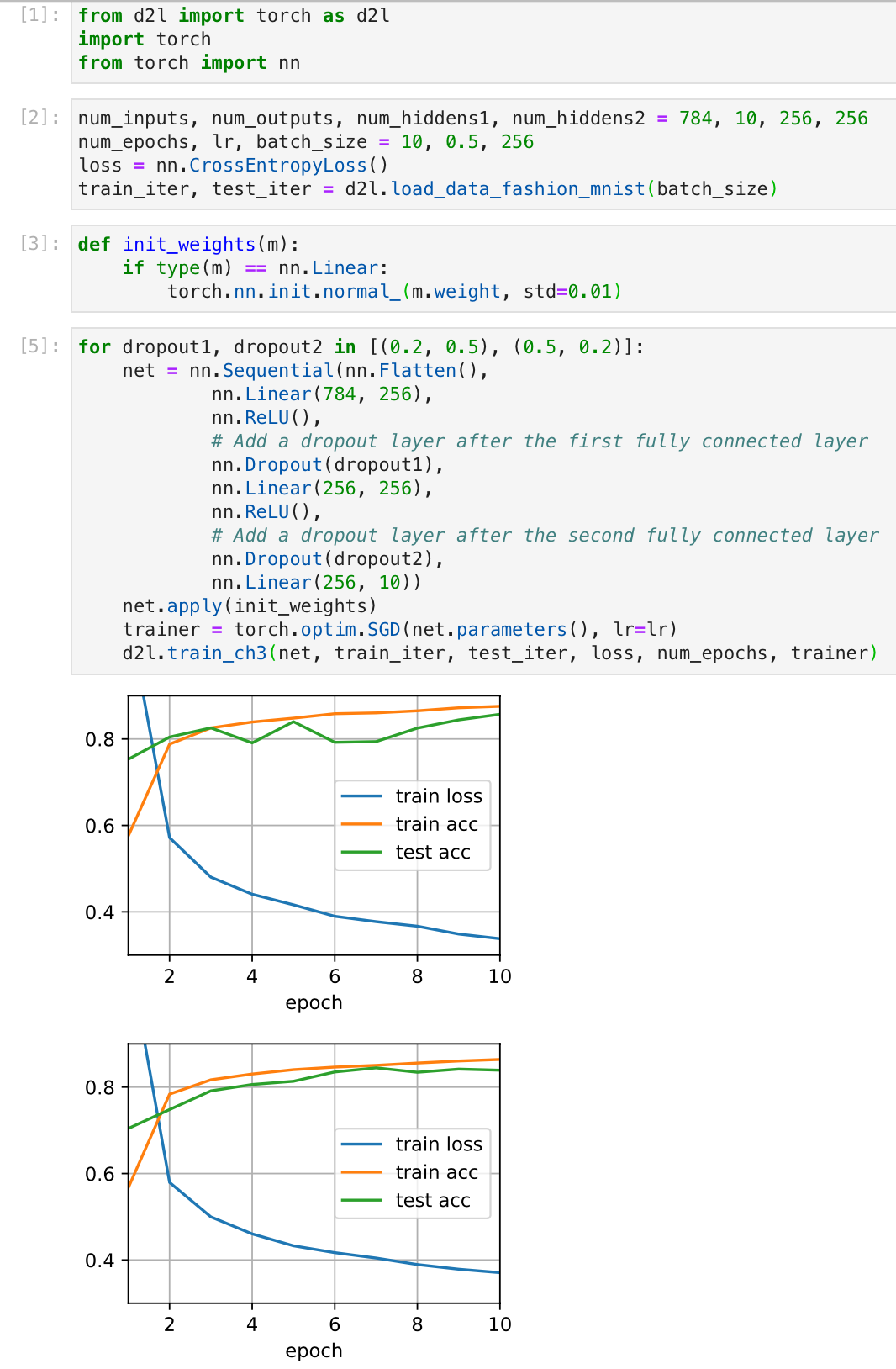
I tried swapping the dropout probabilities for Layers 1 and 2, and did not notice much of a change:
Is there an error in my implementation? Or is this because of the simple nature of the dataset (eg I note that dropout doesn’t help too much over the standard implementation in the first place) and would I normally notice some difference? Thanks!
Hi @Nish, great question! It may be hard to observe a huge loss/acc difference if the network is shallow and can converge quickly. As you can find in the original dropout paper (http://jmlr.org/papers/volume15/srivastava14a/srivastava14a.pdf) as well, the improvement with dropout on MNIST is less than 1%.
Hi, I’ve noticed that we enable Dropout while training, and we may disable it while doing inference. But whether we enable or disable Dropout while testing? If I am not mistaken, in our implementation, we have allowed Dropout in the test. Is that right?
Also, I have another question. We implement Dropout just by zeroing some elements in the forward stage, but whether the weights corresponding to those zeros update in the backward stage?
However, there are two main reasons you should not use dropout to test data:
Dropout makes neurons output ‘wrong’ values on purpose
Because you disable neurons randomly , your network will have different outputs every (sequences of) activation. This undermines consistency.
the weights corresponding to those zeros will still update, because the weight not only corresponds to those zeros, but also other not zeros in the same hidden layer.
Thanks for your answer. But I’m still wondering for something:
How we disable Dropout in testing in the implementation of this book, either from scratch or using high-level API? I’ve found in the implementation from scratch that during training and testing we use the same net, whose attibute is_training is to True. Also, in the implementation using high-level API, I didn’t find the difference of Dropout layer while training and testing.
So could you please tell me where in the code did we disable Dropout while testing?
because the weight not only corresponds to those zeros, but also other not zeros in the same hidden layer.
Is this means each weight corresponds to multiple hidden units? I’m not sure about this, but I think each weight corresponds to a unique input (hidden units) and a unique output in MLP.
After we dropouted, the corresponding hidden layers have already changed. Enable/Disable is confusing.
Test is just a process of calculating a prediction by weights after bp. We don’t need to disable Dropout!
Yes, matrix multiplication is the reason of corresponding to multiple hidden units.
More intuitively, we might argue that we encouraged the model to spread out its weights among many features rather than depending too much on a small number of potentially spurious associations.
In the interactive example from google’s crash course I’m seeing roughly the same amount of features being used when comparing training the model with and without L2 regularization/weight decay:
This means I couldn’t verify the claim or intuition that weight decay spreads out it’s weight among many features.
What is the variance of the activations in each hidden layer when dropout is and is not applied? Draw a plot to show how this quantity evolves over time for both models.
Is the number of hidden units that are activated the subject of the question or the numerical outputs of the hidden units?
Hi,
I’m a bit confused between Dropout and Regularization. Should we use them both to train a neural network or one method is enought.
I tried using L2 regularizaion with Drop out in the exmaple in the book but I got an error
let’s leverage the efficient built-in PyTorch weight decay capability
def train_concise(wd): #net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
# Add a dropout layer after the first fully connected layer
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
# Add a dropout layer after the second fully connected layer
nn.Dropout(dropout2),
nn.Linear(256, 10))
net.apply(init_weights)
for param in net.parameters():
param.data.normal_()
loss = nn.MSELoss()
num_epochs, lr = 100, 0.003
# The bias parameter has not decayed
trainer = torch.optim.SGD([
{"params":net[0].weight,'weight_decay': wd},
{"params":net[0].bias}], lr=lr)
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
with torch.enable_grad():
trainer.zero_grad()
l = loss(net(X), y)
l.backward()
trainer.step()
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('L2 norm of w:', net[0].weight.norm().item())
The error says “‘Flatten’ object has no attribute ‘weight’”. Can someone explain this to me???
Do different neurons get dropped out during different training epochs? For example, if the first and last neurons of a layer are dropped out in the first forward pass, a gradient is eventually calculated at the output and then backpropagated. When the second forward pass starts, do the same neurons that were dropped out during the first forward pass get dropped out? Or a different set of neurons drop out?
Hi @tinkuge, great question. A different set of neurons will be dropped out (or turned off), i.e., we don’t include them in calculation but temporarily froze their weights.
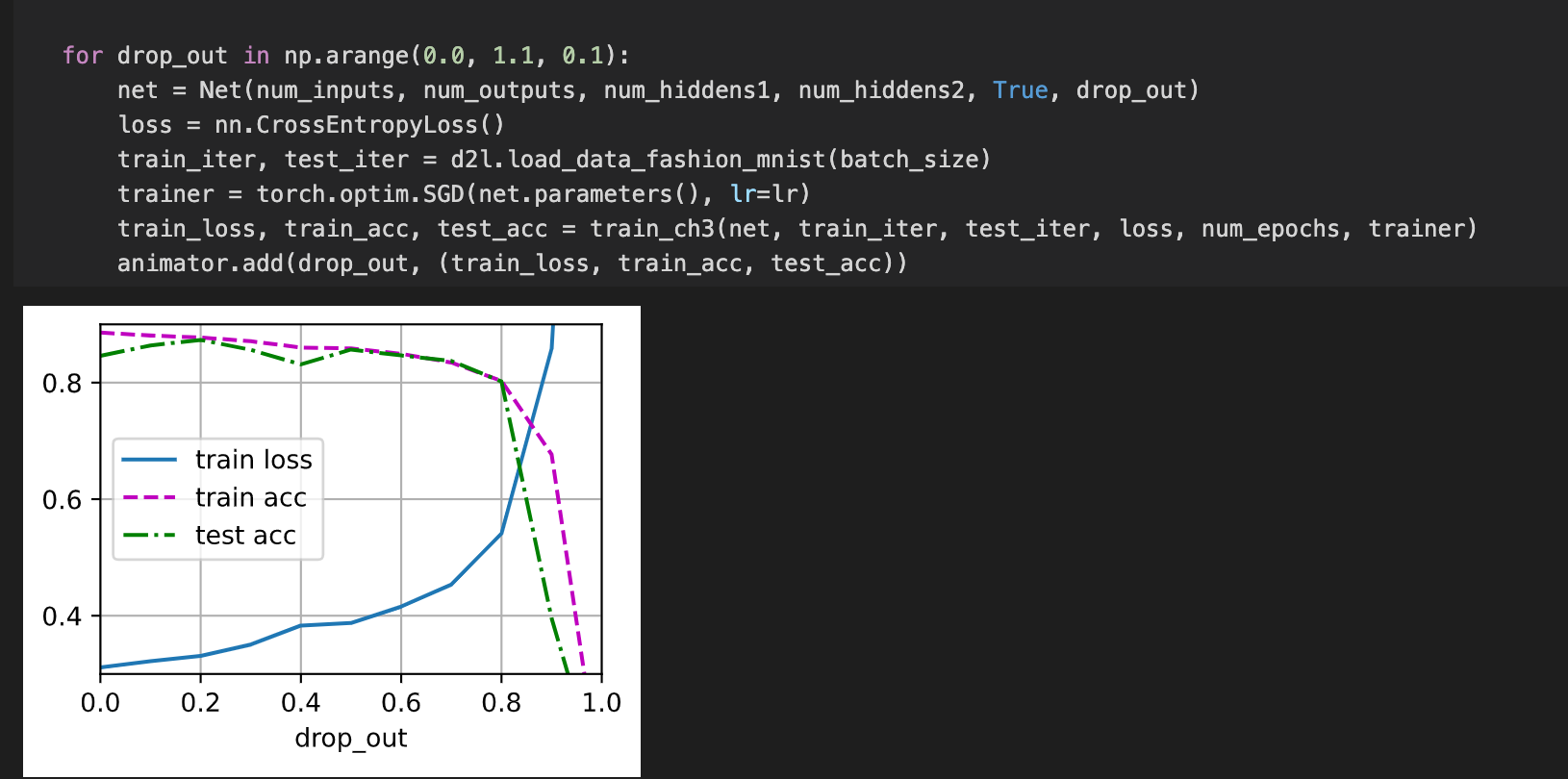
By plot the train loss and accuracy where drop_out1 from 0 to 1, I find that the train loss is relatively low, train acc and test acc is relatively high when drop_out1=0.2. Similarly, the overall training results is best when drop_out2=0.5. Is it right? @goldpiggy1 reply
Great work @Alvin! Typically we use dropout between 0.2 and 0.5. While it really depends on what the network architecture (number of layers, etc.) we are using.
When I used weight_decay and delete drop out, i got the assertion error that the train loss is larger than 0.5. Does anyone have the same error?
I get this workaround by creating another loss function, but just curious why loss would go up to over 1 since we are using cross entropy loss.
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
# nn.Dropout(0.5),
# Add a dropout layer after the first fully connected layer
nn.Linear(256, 256),
nn.ReLU(),
# nn.Dropout(0.5),
# Add a dropout layer after the second fully connected layer
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
in Exercises 7, i make two test.
when i replace dropout with batchnorm1d, the train loss go down quickly , but in the test set is not better than dropout, i think there is maybe some overfit in the model, so in the final layer i use the dropout. in the test it better than normal.
so i think ,maybe we can use batchnorm and dropout together.
i think the model maybe underfitting when you use weight_decay=2. the model can’t fit the dataset.so the loss is large, maybe you can smaller the weight_decay.
Here are my questions about the exercises in this chapter. If anyone have some ideas, open to communication and discussion.
– Excercise 2
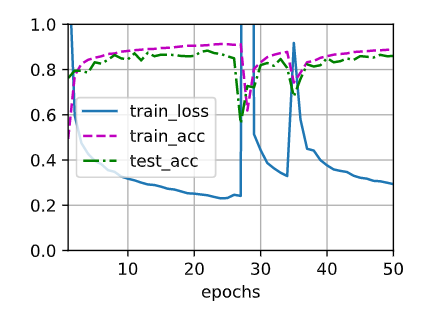
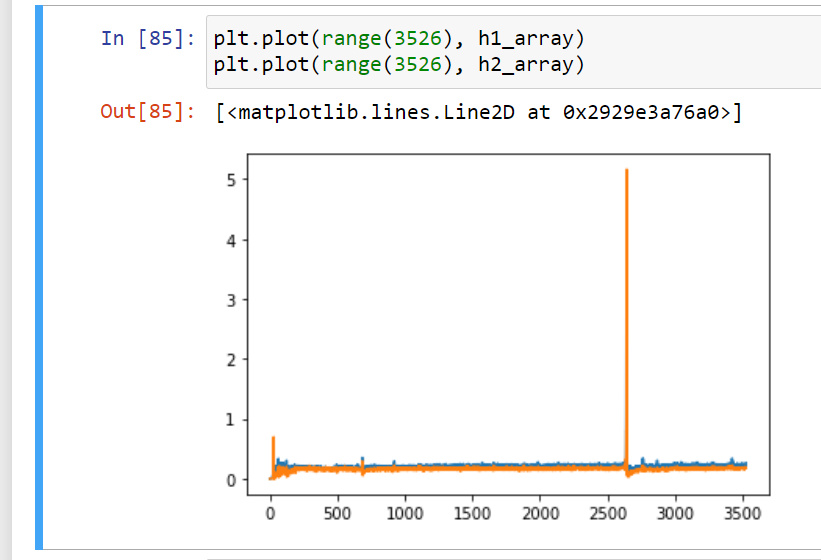
When I tried to increase the value of epoch for the model without dropout, I found the curve of loss and accuracies will change drastically at some points just as picture shown below. Does anyone know the reason for this changes? Does it means that maybe we select a great learning ratio so that we will travel across the optimal point when training?
– Excercise 5
When I tried to use weight decay instead of dropout as the regularization method, I found that only when I select a small value of weight decay (1e4~1e3), I can got a good performance as dropout. Maybe there exist too many parameters here and we cannot set the weight decay too high, otherwise the parameter will decrease to zero rapidly.
– Excercise 3
I didn’t do the implementation on this question, but I have some ideas about it.
As a regularization method, the dropout should be able to decrease the model variance so the variance of the activations may be smaller with the dropout method. But different with weight decay who will decrease values of all the weights so that the values of the activations will be smaller and then variance will be reduced, dropout will decrease the dependencies on strong neuron so the activation values of strong neuron will be decreased but activation values of weak neuron will be increased. In this way, the variances become smaller.
– About the dropout value selection 0,2 and 0.5
We use smaller dropout value for pervious layer but greater value for deeper layer. The change of one layer will affect the following layers so we should be more careful to select dropout value for the anterior layers because the same change on it will have deeper impact.
Dropout Intuition
First, we randomly assign probabilities to hidden units using samples from some distribution (eg: Gaussian distribution) and zero out the hidden units where its randomly assigned probability is < given probability.
Furthermore, the outputs are scaled by a factor of 1/(1-p) during training. This means that during evaluation the module simply computes an identity function.
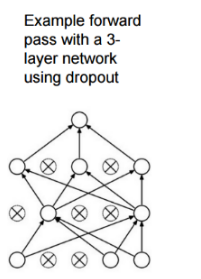
Code: Example forward pass with a 3 layer network using dropout
# dropout implementation
p=0.5 # probability of keeping a unit disable i.e zero
def train_step(X):
# forward pass for example 3-layer neural network
# relu(W1*X + b)
H1 = np.maximum(0, np.dot(W1, X) + b1) * (1/(1-p)) # scale the activation function
U1 = np.random.rand(*H1.shape) < p
H1 *= U1 # dop!
# relu(W2*H1 + b)
H2 = np.maximum(0, np.dot(W2, H1) + b2)* (1/(1-p))
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3
# backward pass: compute gradients ... (not shown)
# perform parameter update... (not shown)
And we do not use dropout during inference time.
Hope this helps you.
What happens if you change the dropout probabilities for the first and second layers? In
particular, what happens if you switch the ones for both layers? Design an experiment to
answer these questions, describe your results quantitatively, and summarize the qualitative
takeaways.
Nothing much changes based on the final accuracy to compare. I compared for 10 epochs but no significant difference.
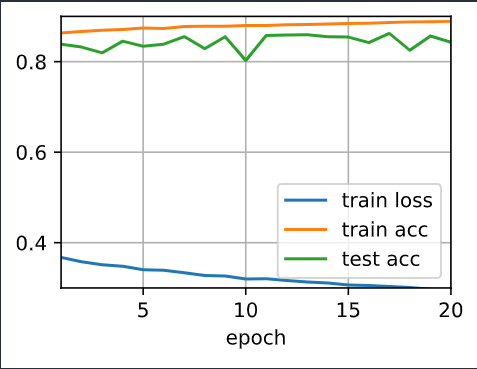
Increase the number of epochs and compare the results obtained when using dropout with
those when not using it.
there is no significant difference in loss. I am getting comparative results in both. (I am wondering if my implementation is faulty)
What is the variance of the activations in each hidden layer when dropout is and is not applied? Draw a plot to show how this quantity evolves over time for both models.
What is meant by variance here do we just apply torch.var over the net.linear weight layers? this is the graph I came up with. after getting variance in forward propogation of hidden layers.
Why is dropout not typically used at test time?
Because we would like all the features weights to be useful and consequential to making the prediction.
Using the model in this section as an example, compare the effects of using dropout and
weight decay. What happens when dropout and weight decay are used at the same time?
Are the results additive? Are there diminished returns (or worse)? Do they cancel each other
out?
The returns are diminished when using both, compared to using them individually.
What happens if we apply dropout to the individual weights of the weight matrix rather than
the activations?
it is still training. But with some slight oscillation in loss. This is the forward implementation
def forward(self, X):
out = self.lin1(X.reshape(-1,784))
out = dropout_layer(out, self.dropout1)
out = self.relu(out)
out = self.lin2(out)
out = dropout_layer(out, self.dropout2)
out = self.relu(out)
out = self.lin3(out)
return out
Invent another technique for injecting random noise at each layer that is different from the
standard dropout technique. Can you develop a method that outperforms dropout on the
Fashion-MNIST dataset (for a fixed architecture)?
I propose to add noise after each hidden layer.
class net_epsilon(nn.Module):
def __init__(self, num_inputs=784, num_outputs=10, num_hidden1=256, num_hidden2=256, epsilon_m=0.02, epsilon_d=0.02):
super(net_epsilon, self).__init__()
self.lin1 = nn.Linear(num_inputs, num_hidden1)
self.lin2 = nn.Linear(num_hidden1, num_hidden2)
self.lin3 = nn.Linear(num_hidden2, num_outputs)
self.relu = nn.ReLU()
self.epsilon_m = epsilon_m
self.epsilon_d = epsilon_d
self.num_inputs = num_inputs
def forward(self, X):
out = self.relu(self.lin1(X.reshape(-1,self.num_inputs)))
out = out + torch.normal(self.epsilon_m, self.epsilon_d, (out.shape))
out = self.relu(self.lin2(X.reshape(-1, self.num_inputs)))
out = out + torch.normal(self.epsilon_m, self.epsilon_d, (out.shape))
out = self.lin3(out)
the results are not that promising though. The thing is the model predict well the losses are so close that you cant really conclude anything.
May I ask a question about Dropout method?
The method is promising to avoid overfitting. But I don’t know how can we ensure it won’t cause underfitting?
In probabilistic terms, we could justify this technique by arguing that we have assumed a prior belief that weights take values from a Gaussian distribution with mean zero.
When did we assume that weights follow Gaussian Distribution?
@goldpiggy, regarding exercise 5, @fanbyprinciple said that “The returns are diminished when using both, compared to using them individually.” Do you think we should use dropout and weight decay at the same time in practice? Could you explain it? Thanks.
Hi, AdaV when I implemented it , it somehow was the case. But I am not sure of the veracity of my claims. I guess I am the most unreliable person on this chat !XD
I would love some guidance on question 3. How might we visualization or calculate the activation, or variance of the activation, of hidden layer units?
Thanks
Exercise 6:
dropout one row of W(2) at a time is equivalent to dropout on the hidden layer.
dropout one col of W(2) at a time is equivalent to dropout on the output layer.
A total random dropout on W probably leads to worse slower converging speed.
decrease dropout: didn’t see any change of results;
increase dropout: val_acc significantly decrease when dropout > 0.9;
without dropout: see sudden decrease and increase of val_acc with epoch increasing, is this a sign of overfit? double decent?
I guess the var will increase after dropout be applied.
I think dropout will decrease the performance of model during test, and you have no benefit by doing this.
I find adding weight decay reduced the performance of my MLP, the performance rank: MLP+WD < MLP+WD+dropout<MLP+dropout. Is this because WD impaired the express ability of MLP? Below are my code, I’m not sure if its correct:
class WD_DropOutMLP(d2l.Classifier):
def init(self, num_outputs, num_hiddens_1, num_hiddens_2, dropout_1, dropout_2, lr, wd):
super().init()
self.save_hyperparameters()
self.wd = wd self.net = nn.Sequential(
nn.Flatten(), nn.LazyLinear(num_hiddens_1), nn.ReLU(), nn.Dropout(dropout_1),
nn.LazyLinear(num_hiddens_2), nn.ReLU(), nn.Dropout(dropout_2), nn.LazyLinear(num_outputs))
def configure_optimizers(self):
params = list(self.net.named_parameters())
weight_params = [param for name, param in params if ‘weight’ in name]
bias_params = [param for name, param in params if ‘bias’ in name]
return torch.optim.SGD([
{‘params’: weight_params, ‘weight_decay’: self.wd},
{‘params’: bias_params}], lr=self.lr)