http://zh.d2l.ai/chapter_attention-mechanisms/attention-scoring-functions.html
请问这里的batch_size 和num_queries的区别是什么 batch_size不应该是代表了一个batch里面查询的数目吗??
查询的shape: (batch_size, num_queries, q)
keys的shape:(batch_size, num_keys, k) (这里假设k和q不同)
我个人理解是比如1组数据包括5个batch(小批量),在CV里面是不是可以理解为有5张图片,每一张图片上做num_queries次询问,每一张图片提供num_keys条线索。
然后在一张图片完成所有的询问;再然后是一个小批量完成所有的询问。(暂时这么理解的,李沐老师后面的课还没有看 ![]() )
)
1 Like
文中提到查询和键特征维度不同的时可以采用加性注意力,那么是不是也可以对查询和键采用全连接层将他们映射到特征维度相同的隐藏层,这样他们的特征维度就相同了,是不是也就可以接着使用前面提到的Nadaraya-Watson核来计算权重?类似于:
![]()
1 Like
为什么两个均值为0方差为1的向量相乘后的方差是d呢?
1 Like
点积是向量对应位置相乘再相加。两个独立的N(0,1)的随机变量相乘得到的变量方差还是1。Q,K都是d维, 相加步骤是d个方差为1的变量相加,方差就是d了。
3 Likes
懂了,非常感谢[date=2023-03-05 timezone=“Asia/Shanghai”]
书里在缩放点积注意力的第一句话:“使⽤点积可以得到计算效率更⾼的评分函数,但是点积操作要求查询和键具有相同的⻓度d。”,我想问相同长度d是什么意思,我可以通过Linear层把不同的特征数映射成相同的长度吗?可是如果这样操作就跟上文提到的加性注意力类似了?我不太明白为什么要求查询和键有相同的长度d。 ![]()
这里的sequence_mask函数中的d2l.sequence_mask里,不应该用元素的大小作为遮掩比较的值么?直接用元素的序号作为遮掩比较的话,没有办法找出score最高的那几个键值对吧。
1 Like
相同长度d是q的特征维度等于k的特征维度。因为点积需要对应维度相同。这里是需要q的特征维度等于k的特征维度才能得到对应的未一化相关系数。
加性注意力因为q与k特征维度不等,所以用Wq和Wk将他们的维度放缩到同一个维度,然后使用广播机制让同一个q与每个k相加,然后使用共享的Wv来将他们点积得到一个标量,也就是相关系数。
也就是说,缩放点积直接通过点积得到注意力分数,没有任何的学习参数。而加性注意力是通过可学习参数先进行放缩,然后进行q与k的特征相加。区别在于:①是否可学习 ②特征进行点积还是特征进行相加
5 Likes
文中定义的AdditiveAttention类似乎就是这么定义的

前者是的,后者你可以认为是序列长度或者时间步长度
公式是这么定义的
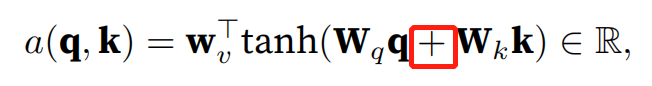
d个方差为1的相互独立的变量相加起来的方差等于d。那么怎么证明q_ik_i 与 q_jk_j 是相互独立呢 ![]()
这是原文里的假设欸,“ 假设查询和键的所有元素都是独立的随机变量”
只使用矩阵乘法,能否为具有不同矢量长度的查询和键设计新的评分函数?
这个怎么做
通过广播机制实现不同形状的矩阵相加,这种操作在数学上是否成立呢?还是说仅仅是深度学习在实现的时候的一种骚操作?
请教下大家,为什么 加性注意力的激活函数是tanh而不用softmax?