https://zh-v2.d2l.ai/chapter_computer-vision/fine-tuning.html
1 Like
书中翻译错误指正。
Torch版459页,“我们使⽤的热狗数据集来源于⽹络。该数据集包含 1400 张包含热狗的正⾯类图像以及包含其他⻝物的尽可能多的负⾯级图像。两个 课程 的 1000 张图⽚⽤于训练,其余的则⽤于测试。”
应该是 类别 ,我猜英文版可能是class,翻译错了
1 Like
你好!请教一下,demo上采用的resnet18模型是torchvision.models库里的,采用pretrained=True进行。
pretrained_net = torchvision.models.resnet18(pretrained=True)
如果不采用torchvision.models库里的模型,而是从外部提供的模型进行fine tuning,需要怎么操作?谢谢
首先你要构建一个和你所说的外部模型一样结构的模型(你想要载入的那部分要一致,无需载入的部分如最后的输出层倒无所谓),然后加载那个模型预训练的state_dict,要注意的是你构建的模型与预训练的模型各层的命名要一致,否则load_state_dict会报错。load_state_dict中参数设置strict=False,仅加载一致部分(如下代码)
# 构建模型
# Build your model
# 加载预训练的state_dict
pretrained_state_dict = torch.load(pretrained_path)
# 检验参数数量,确保能匹配
matched_state_dict = {k: v for k, v in pretrained_state_dict.items()
if model.state_dict()[k].numel() == v.numel()}
# 不严格载入,加载模型中一致的部分
model.load_state_dict(matched_state_dict, strict=False)
# 后续微调
# To be implemented
2 Likes
冻结分类层之前的参数,跟微调哪个效果会更好?
微调就是冻结分类层前面的层的参数,我猜你想问的是微调和全部不冻结训练二者哪个更好?一般后者会更佳,但是相应地要更新的参数也更多,训练所需时间也更多,需要权衡一下
T3 与 T4 实验
原迁移学习本地结果:
loss 0.287, train acc 0.901, test acc 0.927
1501.1 examples/sec on [device(type=‘cuda’, index=0), device(type=‘cuda’, index=1), device(type=‘cuda’, index=2), device(type=‘cuda’, index=3)]
冻结预训练参数结果:
loss 0.362, train acc 0.884, test acc 0.922
2197.8 examples/sec on [device(type=‘cuda’, index=0), device(type=‘cuda’, index=1), device(type=‘cuda’, index=2), device(type=‘cuda’, index=3)]
利用原hotdog类参数做初始化结果:
loss 0.210, train acc 0.923, test acc 0.938
1022.9 examples/sec on [device(type=‘cuda’, index=0), device(type=‘cuda’, index=1), device(type=‘cuda’, index=2), device(type=‘cuda’, index=3)]
1 Like
想请问一下利用原hotdog类参数做初始化具体是指用什么做初始化结果?
你好,我想请教一下全部不冻结时,每次用梯度下降法是对全部层的所有参数进行减去梯度来更新吗
对的,此时所有参数都要更新,但是由于是在预训练的参数基础上更新的,收敛得会比较快
可以给一下冻结的代码嘛?
我按照练习题上的冻结,但是出错了
请教一下,为什么我将 loss = nn.CrossEntropyLoss(reduction=“none”)
改为 loss = nn.CrossEntropyLoss()后,结果天差地别
train_batch_ch13中定义
l = loss(pred, y) l.sum().backward()
l需要是张量即loss = nn.CrossEntropyLoss(reduction=“none”),然后l.sum()求和,得到一个batch上的总损失
你改成loss = nn.CrossEntropyLoss()是均值了,肯定天差地别啊。
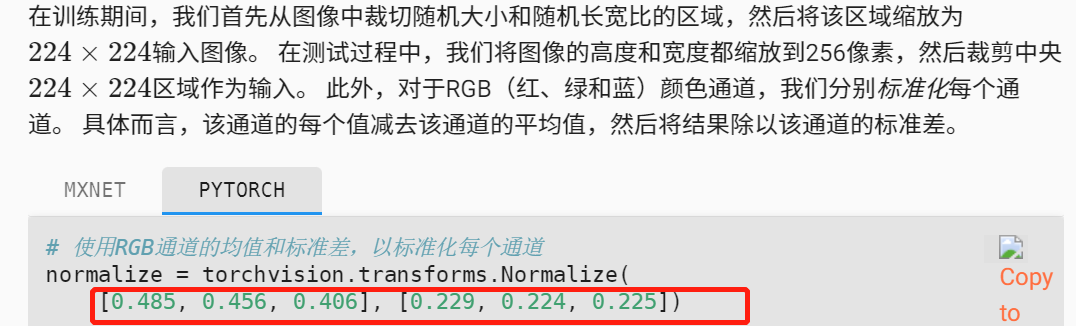
这个应该不是怎么算,而是大量统计数据,我记得以前图像课上讲过,可以视为自然界图像的总体特征吧
这个建议去看一下nn.CrossEntropyLoss()的源代码,如果删掉reduction=“none”,默认求平均。这里加上这句话,返回的是一个列表,里面是每个样本的损失。然后我们在去看一下老师写的train_ch13,在反向传播的时候使用loss.sum().backward(),等于是将n个样本的梯度加起来。如果不加这句话,等于对n个样本梯度加起来求和。总结:去掉这句话等于把所学习率缩小了N倍,结果当然差距很大。
为什么微调会是冻结,冻结不应该是保持权重不变吗,而微调是在较小的学习率进行权重更新,减小学习率太大带来的跨过最优解的可能13.2.2.3中的SGD实例化中的参数很好的说明了这点
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225] ,是从 ImageNet 数据集的数百万张图片中随机抽样计算得到的。