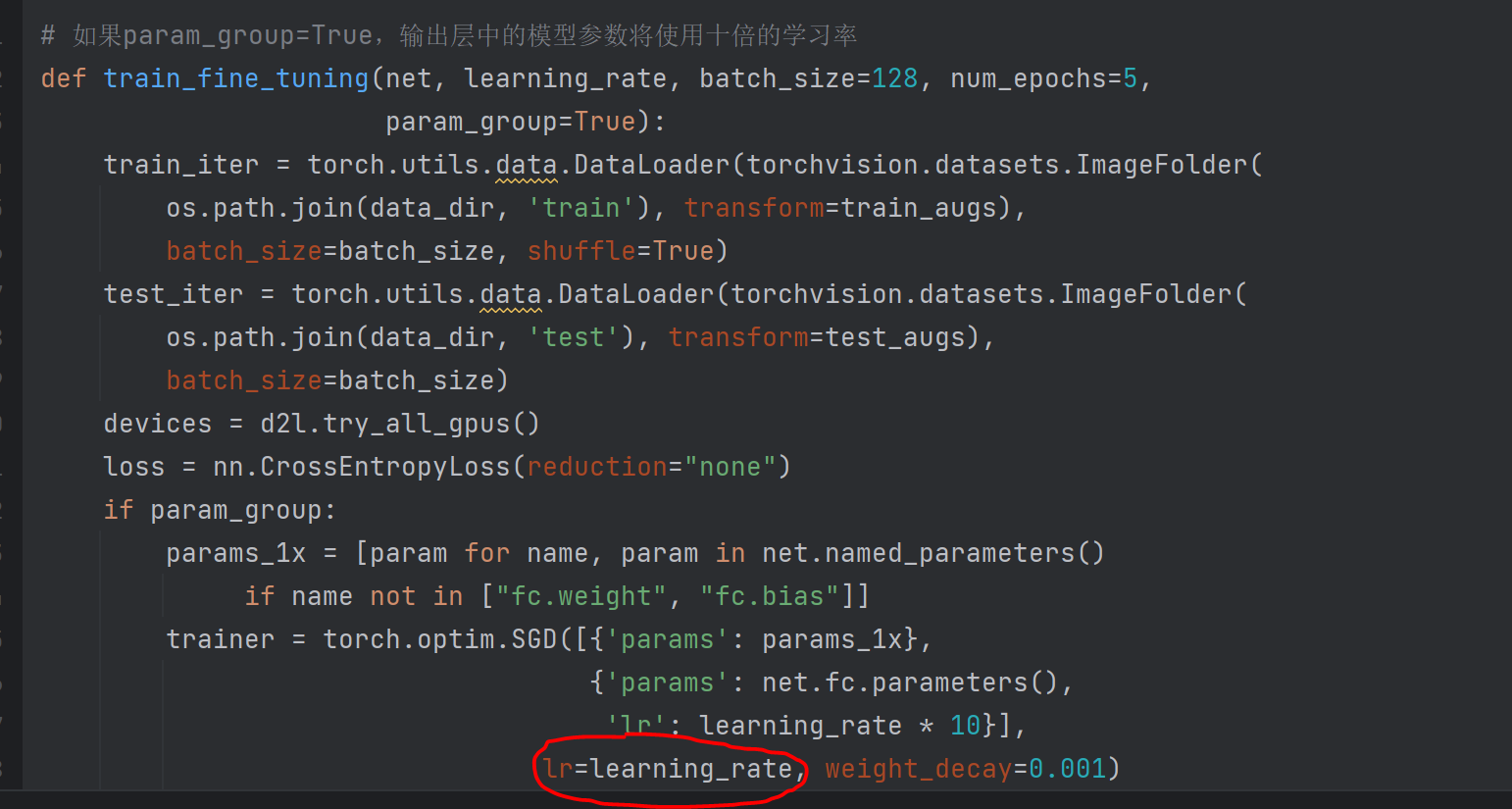
个人做法是用hotdog_w代替finetune_net.fc的第一行权重
for _ in range(0):
with torch.no_grad():
finetune_net.fc.weight[0] = hotdog_w.reshape(-1)
训练结果:loss 0.135, train acc 0.945, test acc 0.948
1.使用4e-4的学习率,速度变快了(176.2->190.3 examples/sec),准确度提升了(train acc 0.933->0.951)
检查将模型移动到gpu的代码是否在,没有的话显式地进行移动:
device = torch.device("cuda:0" is torch.cuda.is_available() else "cpu")
model.to(device)
如果已经如上面显式地进行了移动,还在cpu上的话。检查你的torch是否安装了支持gpu版本的,安装是否正确 ,命令行输入以下指令测试,返回True的话就已经正确安装:
torch.cuda.is_available()
我是直接把训练函数的学习率调为0了,这样就不会更新了。你的报错应该是在train_batch_ch13中计算l.sum().backward()的时候报错了,我们已经把requires_grad参数设置为False了,如果还试图求backward的话,自然会报错。另一种方法就是去修改train_batch_ch13。
因为预训练模型是在 imagenet 上训练的,然后 imagenet 的 transform 中进行了这样的一个 normalize,所以在这个数据集也进行了同样参数的 normalize.
1 Like
请问把这里的learning_rate改为0是不是就是不更新fc层前的参数?
关于练习第四题,事实上,ImageNet数据集中有一个“热狗”类别。我们可以通过以下代码获取其输出层中的相应权重参数,但是我们怎样才能利用这个权重参数?
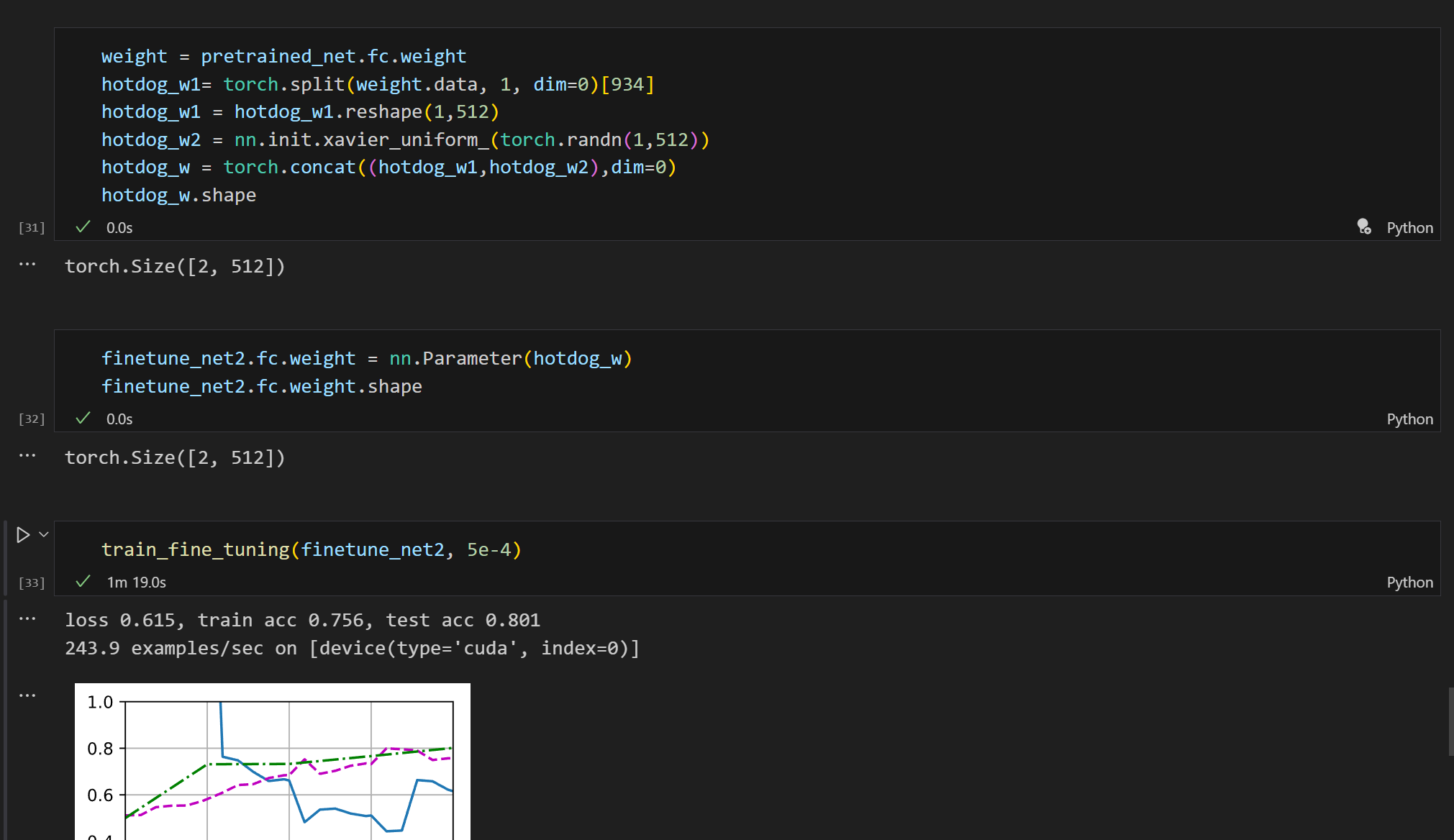
我是这样处理的,把热狗的[1,512]权重拿出来,再用xavier_uniform获得一个[1,512]的tensor,两者拼接成[2,512]的weight给微调模型
Xiyu
November 21, 2023, 1:17pm
30
关于第四题,事实上我猜想应该通过修改fine-tuning中得最后一个全连接层来实现权重参数的利用,
通过这个方法,最后的参数在训练集上略有上升。
hotdog & not-hotdog的想法是来自美剧硅谷里面的梗吧,哈哈哈哈
用pretrained加hotdog fc+微調 的結果最好,有0.934.
下面是我自己对于冻结除最后一层所有层参数进行finetune的代码,不知道对不对,lr=5e-5,内部不乘10,就是5e-5
froze_net = torchvision.models.resnet18()
element 0 of tensors does not require grad and does not have a grad_fn的原因可能是你把全部的参数都给冻结了,那pytorch反向传播也很无奈啊:“你都冻结了我传播个啥”,我的修改方案是:
# 如何冻结预训练的参数?
# # 以下代码放在更改fc之前,或者主动声明fc的参数需要更新
# for param in finetune_net.parameters():
# param.requires_grad = False
# # 解冻fc的参数(非必要):
# finetune_net.fc.weight.requires_grad = True
# finetune_net.fc.bias.requires_grad = True
# 效果与微调模型相似,但是速度更快。
如果你在finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2) 前面用param.requires_grad = False,此时fc因为你要更改他所以他的.requires_grad = True,但是如果你先更改了finetune_net.fc 然后又for循环把他冻结了那肯定没有参数可以被更新了,所以我就使用
finetune_net.fc.weight.requires_grad = True
finetune_net.fc.bias.requires_grad = True
来解冻fc了
预训练的热狗权重:
# 使用预训练的模型的热狗权重(acc比xavier初始化高多了)
weight = finetune_net.fc.weight
hotdog_w = torch.split(weight.data, 1, dim=0)[934] # torch.Size([1, 512])
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
not_hotdog_w = torch.randn_like(hotdog_w)
finetune_net.fc.weight.data = torch.cat((hotdog_w, not_hotdog_w), dim=0)
finetune_net.fc.bias.data.fill_(0)
Saminey
September 25, 2024, 3:36pm
37
finetune_net = torchvision.models.resnet18(pretrained = True)当从torchviion中导入与训练模型时,python会提示 Arguments other than a weight enum or None for ‘weights’ are deprecated,因为pretrained在0.15以后的版本后会被删除,避免以上err,可以使用’‘weights= torchvision.models.ResNet18_Weights.DEFAULT’‘或者’‘weights=‘DEFAULT’’'来进行代替,参考资料如上:[1]. 模型和预训练权重 - Torchvision 0.19 文档 - PyTorch 中文 [2]. resnet18 — Torchvision main documentation (pytorch.org)
DJDTB
November 14, 2024, 7:46am
38
但是根据交叉熵损失在梯度下降公式里面应该就是用梯度均值来更新参数的(之前章节的代码里也都是默认均值),不知道为什么在train_ch13里面沐神用的是sum梯度总和来进行反向传播更新参数的
maybe the weight_decay will change the learning_rate.if learning_rate always equals 0,fc.parameters() will not change.
W.Yun
October 10, 2025, 6:53am
40
其实是一样的,metric.add(l.detach() * X.shape[0], metric.accuracy(y_hat, y), X.shape[0]) 其实使用平均值*了数量metric.add(l, acc, labels.shape[0], labels.numel()) l就等价于l.detach() * X.shape[0]
# * 3
finetune_net = torchvision.models.resnet18(weights=resnet18_weights)
for param in finetune_net.parameters():
param.requires_grad = False
new_linear = nn.Linear(finetune_net.fc.in_features, 2)
nn.init.xavier_uniform_(new_linear.weight)
finetune_net.fc = new_linear
train_iter = torch.utils.data.DataLoader(
torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'), transform=train_augs),
batch_size=128, shuffle=True)
test_iter = torch.utils.data.DataLoader(
torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'), transform=test_augs),
batch_size=128)
loss = nn.CrossEntropyLoss(reduction='none')
# * 只更新输出层参数
trainer = torch.optim.SGD(new_linear.parameters(), lr=5e-4, weight_decay=0.001)
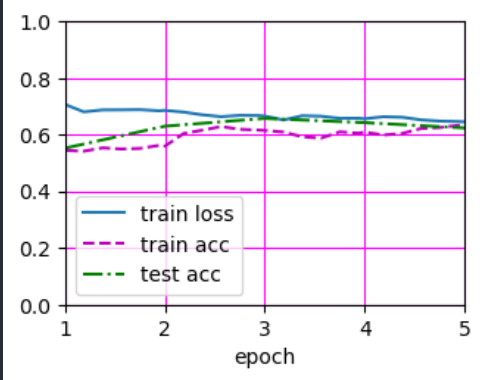
d2l.train_ch13(finetune_net, train_iter, test_iter, loss, trainer, 10)
# * loss 0.287, train acc 0.898, test acc 0.909 虽然最终结果还行,但训练过程中不稳定。
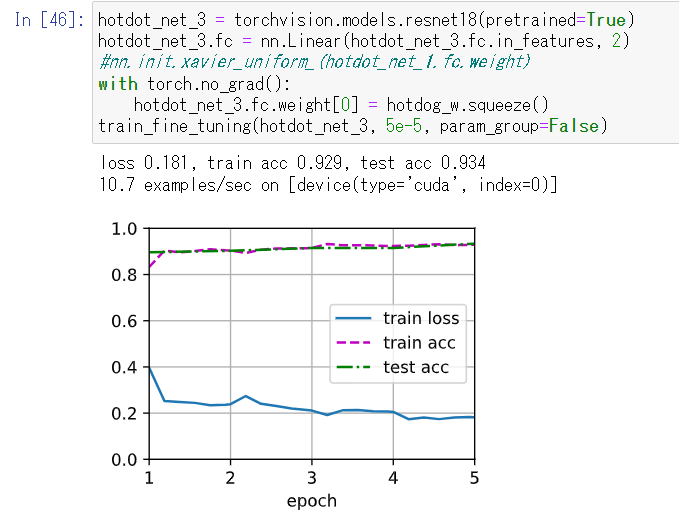
# * 4 可以把这个权重当做最后一层中的输出是热狗单元的参数
finetune_net = torchvision.models.resnet18(weights=resnet18_weights)
weight = finetune_net.fc.weight
hotdog_w = weight[934].detach().reshape(1, -1)
not_hotdog_w = torch.zeros(1, hotdog_w.shape[1])
nn.init.xavier_uniform_(not_hotdog_w)
new_linear = nn.Linear(finetune_net.fc.in_features, 2)
new_linear.weight = nn.Parameter(torch.concat((hotdog_w, not_hotdog_w)))
finetune_net.fc = new_linear
train_fine_tuning(finetune_net, 5e-5)
# * loss 0.180, train acc 0.933, test acc 0.956 这样训练出来的精度很高