http://zh.d2l.ai/chapter_convolutional-modern/batch-norm.html
关于这一段“请注意,如果我们尝试使用大小为 1 的小批量应用批量归一化,我们将无法学到任何东西。 这是因为在减去均值之后,每个隐藏单元将为 0。 所以,只有使用足够大的小批量,批量归一化这种方法才是有效且稳定的。 请注意,在应用批量归一化时,批量大小的选择可能比没有批量归一化时更重要”,请问怎么理解呢?这里的批量请问是网络训练的batch吗?
2 Likes
是的。如果是全连接层,对应的batch_size为输入X.shape[0]。如果batch_size为1(只有一个样本),没有均值和方差可言(数值上存在均值和方差),做不了批量归一化
5 Likes
是的,指batch_size,notebook上设置为256。如果batch_size为1,那么这个小批量的均值就是这个样本值本身,则样本值减去均值就为0了,也即文中所说的”每个隐藏单元将为 0“,所以batch_size要足够大,但也不要太大
3 Likes
所以说,对于2d Conv层的BN操作,均值的计算方法,是该批次下,每个通道里,所有example所有像素的平均值?按代码来看是这样,但是这和公式7.5.2不符合吧?公式7.5.2表达的是,均值的计算只在first dim也就是batch example这一维度求平均,均值应该是个shape为(num_channels,height,width)的tensor。
4 Likes
对的。7.5.2中𝐱是一个tensor,可以是n维的
请问一下我在按课程中代码实现LeNet+BatchNorm得到的结果是train loss 和 test loss由较大的差距,为什么加以BatchNorm后出现了过拟合现象呢?
请问课后练习的答案哪里可以找到?谢谢回复
官方没有给答案,而且很多问题是开放性的,有疑惑的地方可以在论坛和大家讨论

在“由于单位方差(与其他一些魔法数)是一个任意的选择,因此我们需要通常包含拉伸参数(scale)和偏移参数(shift),它们的形状与x相同”这里不应该是与x相同,而是应该与样本均值和样本标准差相同吧
看了这里的“簿记”原文是“bookkeeping”。
我的理解“簿记问题”是指一些事务性工作,不一定要跟某个特定算法直接相关。
We then integrate this functionality into a custom layer, whose code mostly addresses bookkeeping matters, such as moving data to the right device context, allocating and initializing any required variables, keeping track of moving averages (here for mean and variance), and so on.
我的也是,后来发现是使用了多卡训练造成的。我觉得可能是自己实现的batch Norm在多GPU数据分发后,每个GPU上单独计算自己拿到的那一小块样本,使得生效的batch size变得很小,并没有把我们设置的batch size内的样本数据归拢一起做平均求方差。
-
我认为可以,因为是否使用偏置不改变样本方差,而使用偏置b则数据x和均值u会分别变成x+b和u+b,做差的结果仍然是(x-u),和没有偏置的情况是一样的,因此偏置可以被去掉
-
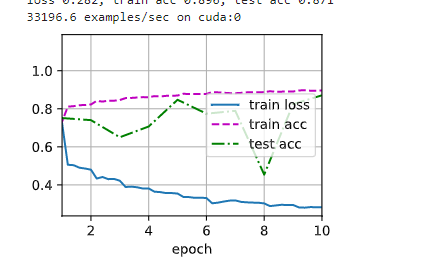
不使用Batch Norm则学习率为0.9,使用则变成1.0,同时训练精度从81.1%提高到90.3%,而测试精度则从78.1%提高到78.3%。通过实验发现使用Batch Norm比能够整体提高训练和测试精度,10个epoch结束时train acc提高0.068, test acc提高0.066,loss降低0.177,可见确实能够提高网络性能
-
不删除BN层,则loss 0.268, train acc 0.901, test acc 0.861
只保留第二个和第四个BN层,则loss 0.289, train acc 0.894, test acc 0.787
只保留第一个和第三个BN层,则loss 0.286, train acc 0.893, test acc 0.820
只删除第一个BN层,则loss 0.272, train acc 0.899, test acc 0.769
只删除第二个BN层,则loss 0.269, train acc 0.901, test acc 0.774
只删除第三个BN层,则loss 0.272, train acc 0.901, test acc 0.857
只删除第四个BN层,则loss 0.283, train acc 0.895, test acc 0.857
可以看出删除全连接层后面的批量规范化对结果影响不大,因此实际上是可以删除的 -
似乎是可以的,BN层兼具稳定训练过程和正则化的效果,将全连接阶段的BN层全部替换为弃置概率为0.5的Dropout层, 则loss 0.486, train acc 0.827, test acc 0.763,对比而言精度不如使用BN层的情况,而且train acc与test acc的差距也更大,说明BN反而能够起到比dropout更好更稳定的正则化效果
-
通过实验观察模型中gamma和beta的情况。从结果来看,随着网络加深,beta的值逐渐稳定到0附近,而gamma的值则逐步稳定到1到2之间,说明BN层确实有助于稳定中间结果的数据分布
12 Likes
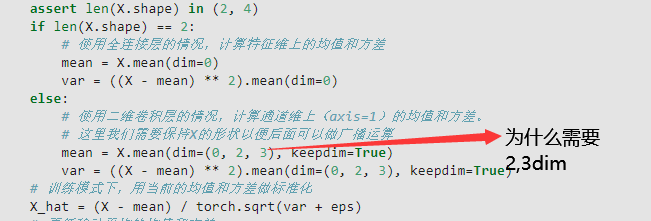

除了通道维度(dim=1)其余维度都要求均值,最后求出的张量只有通道一个维度,keepdim=True即为(1,channel,1,1)的4D张量。
1 Like
同问,这个是batch_size吗?
mini_batch和batch_size有什么不同?
请问一下计算是不是批次中的一个样本的第一个通道,加上第二个样本的第一个通道,。。。,第N个样本的第一个通道,得到第一个通道的和, 除以NHW而不是单纯除以N,最后得到的是代表这个batch的第一个通道的平均值的数字,而不是一个HW的矩阵
1 Like
请问一下为什么在加入batchnorm层之后test acc会上下波动呢?