test_iter.num_workers = 0
train_iter.num_workers = 0
这两行甚至还能解决我 plt 弹出多个空图的问题,我是用多线程把绘图放前台,训练放后台,这样能在 pycharm 中实现动态更新图片的功能,代码来自前几节一位大佬的评论,以下是我调试通过的代码,供各位参考:
import threading
import torch
import torchvision
from torchvision import transforms
from torch import nn
from d2l import torch as d2l
from torch.utils import data
from Accumulator import Accumulator
from Animator import Animator
def get_dataloader_workers():
# 使用4个进程并行读取
return 4
# 加载数据集并小批量读取
def load_data_fashion_mnist(batch_size, resize=None):
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(
root='../data', train=True, transform=trans, download=False
)
mnist_test = torchvision.datasets.FashionMNIST(
root='../data', train=False, transform=trans, download=False
)
return (data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=get_dataloader_workers()))
# 激活函数 relu
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
# 模型
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X @ W1 + b1) # 这里“@”代表矩阵乘法
return (H @ W2 + b2)
# 指标评价函数
def accuracy(y_hat, y): # @save
"""计算预测正确的数量"""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
def evaluate_accuracy(net, data_iter): # @save
"""计算在指定数据集上模型的精度"""
if isinstance(net, torch.nn.Module):
net.eval() # 将模型设置为评估模式
metric = Accumulator(2) # 正确预测数、预测总数
with torch.no_grad():
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
# 训练
def train_epoch_ch3(net, train_iter, loss, updater): # @save
"""训练模型一个迭代周期(定义见第3章)"""
# 将模型设置为训练模式
if isinstance(net, torch.nn.Module):
net.train()
# 训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
for X, y in train_iter:
# 计算梯度并更新参数
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad()
l.mean().backward()
updater.step()
else:
# 使用定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回训练损失和训练精度
return metric[0] / metric[2], metric[1] / metric[2]
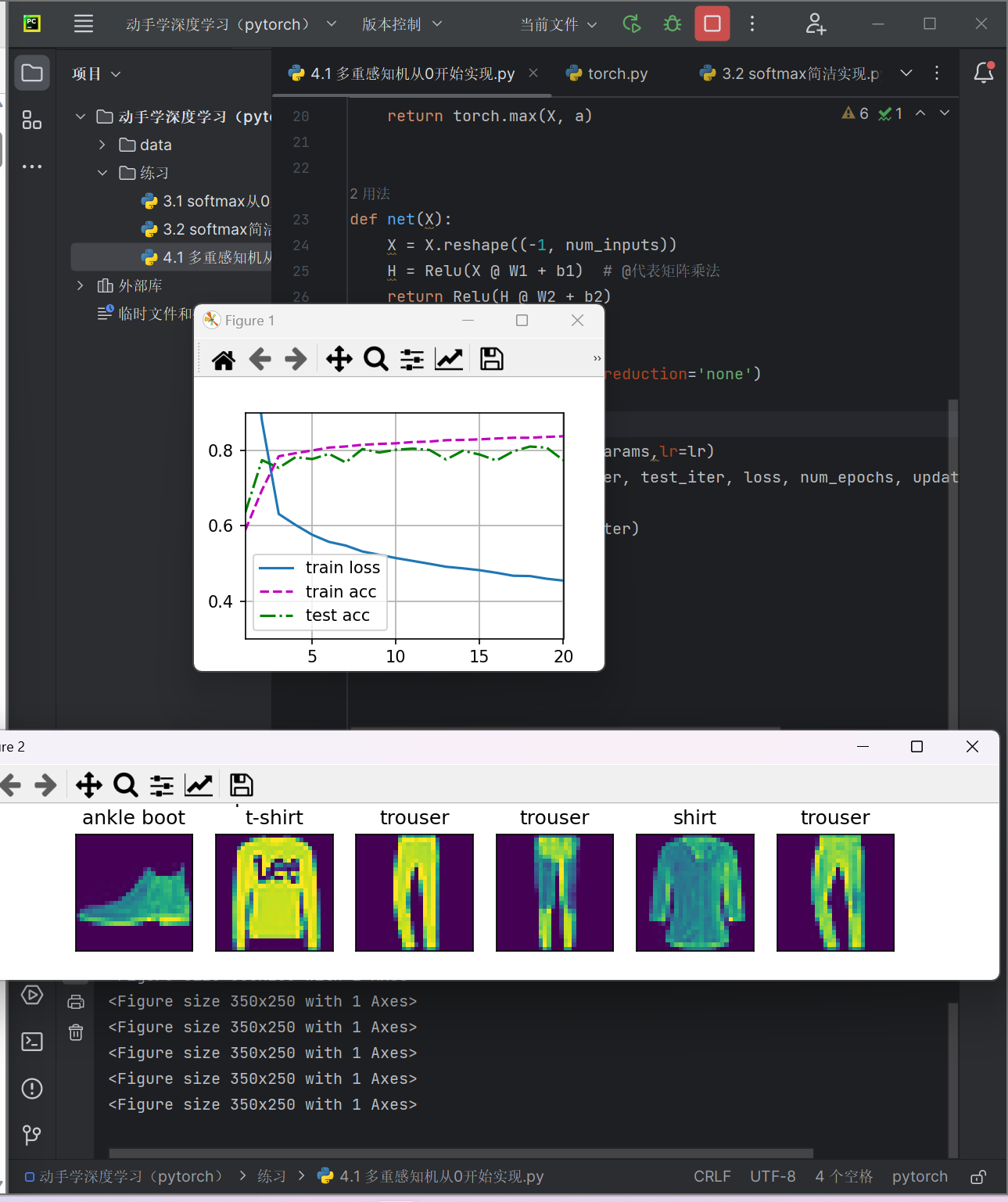
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
# 训练模型
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
def train_thread():
train_metrics = ()
test_acc = 1
for epoch in range(num_epochs):
# 训练该批量样本, 得到的是 [训练损失,训练精度ACC]
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
# 直接用得到的训练权重开始用小批量测试集评估
test_acc = evaluate_accuracy(net, test_iter)
# 调用动画器输出可视化训练进度
animator.add(epoch + 1, train_metrics + (test_acc,))
if 'display' not in globals(): # 在非notebook环境下显示数值结果
print('epoch {0}: train loss {1}, train accuracy {2}, test accuracy {3}.'.format(
epoch, train_metrics[0], train_metrics[1], test_acc
)) # 控制台输出
d2l.plt.draw() # 更新绘图
train_loss, train_acc, = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
# print(globals())
# 在非 notebook 环境中(如pycharm)动态显示绘图
if 'display' not in globals():
th = threading.Thread(target=train_thread, name='training')
th.start()
d2l.plt.show(block=True) # 显示绘图
th.join()
batch_size = 256
train_iter, test_iter = load_data_fashion_mnist(batch_size)
train_iter.num_workers = 0
test_iter.num_workers = 0
# 初始化模型参数
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
# 损失函数
loss = nn.CrossEntropyLoss(reduction='none')
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
1 Like
4.1 练习
original:
- 更改 num_hiddens: 从256 增加为 512
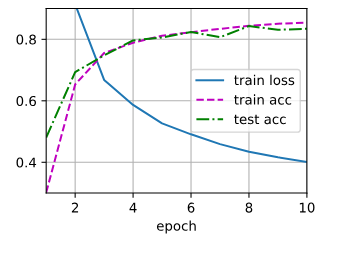
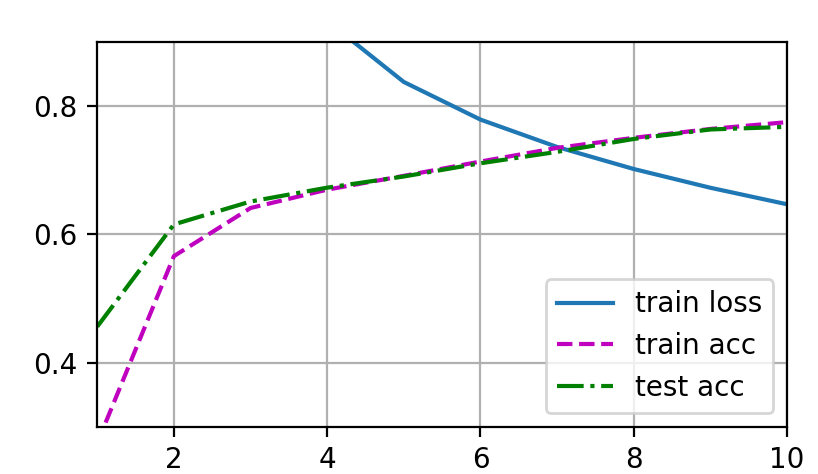
可以看到 训练结果几乎没什么变化
2.增加层数 从两层增加到三层 256->128->10
可以看到与 原始图像比, 一开始的训练精度与测试精度都非常低,后来增长的很快
而且可能由于epoch次数少一些,到最后loss比原始图像更陡峭,可能还有下降的趋势
3.学习率增加 0.1 → 0.3
与原始图像比,虽然10个epoch后loss更低,但是test_acc却出现下降的情况
可能出现了过拟合
4.懒得推 ,无数种模型 选不出来
5.超参数组合太多了 ,排列组合可能性太多,而且一个小改动可能会对模型产生很大影响
6.用一个交叉验证集 ,用来 选择模型
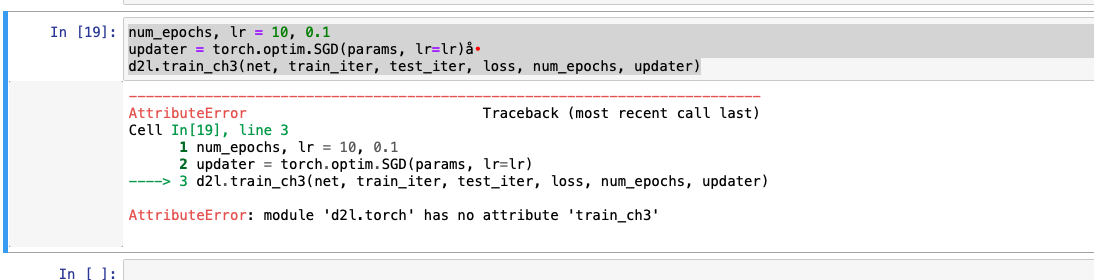
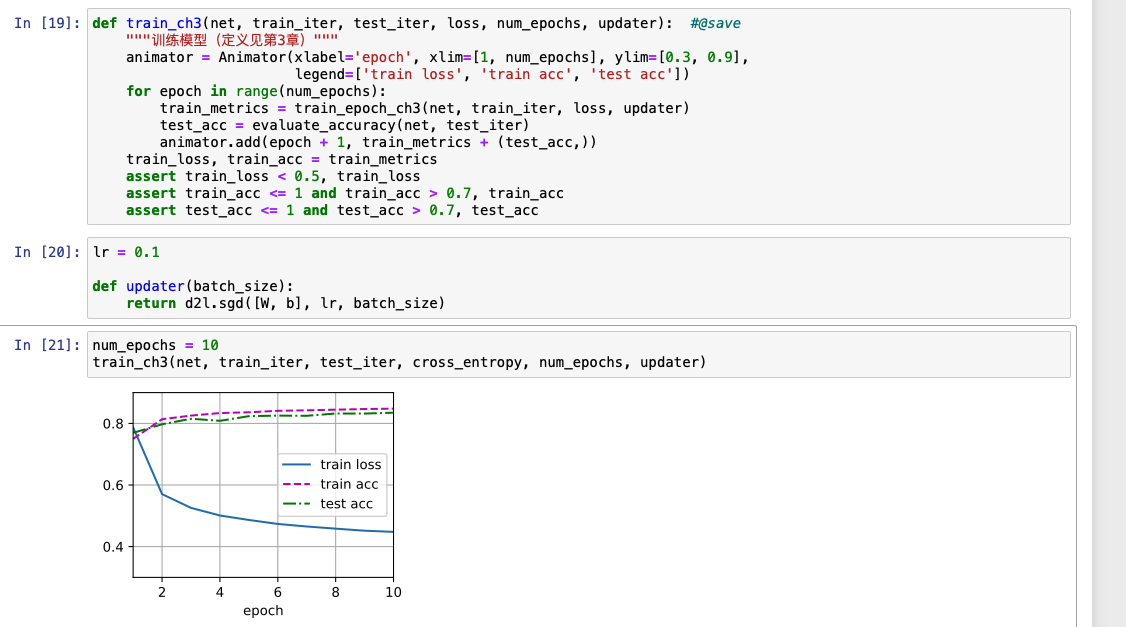
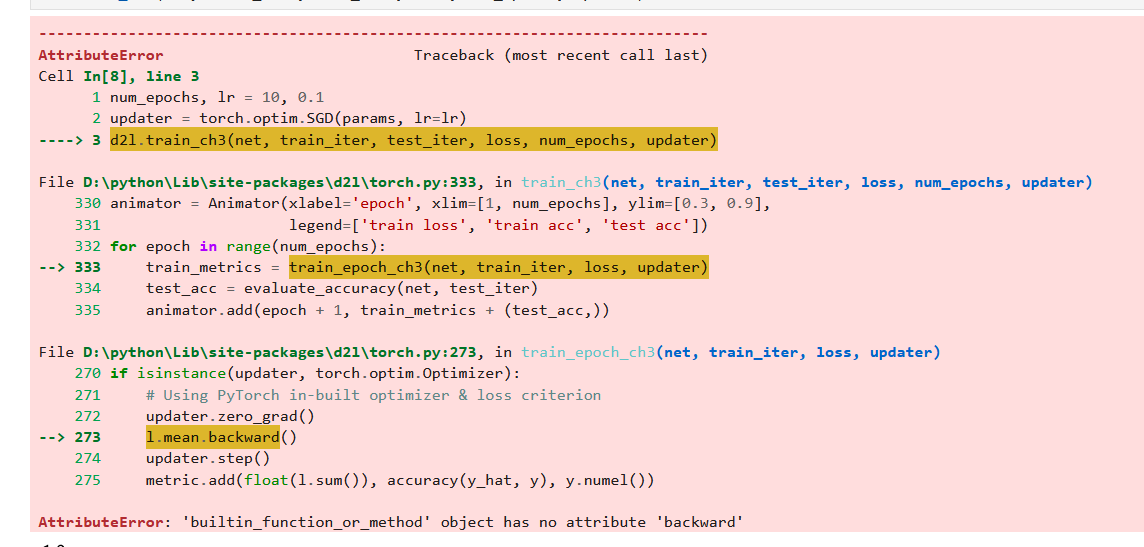
应该是没有保存到d2l ,这个要怎么解决求大神
Run this chapter’s code ,got a " module ‘d2l.torch’ has no attribute ‘train_ch3’ " Error. How to resolve?
兄弟你解决这个问题了吗,我的d2l版本也更新到最新了
from d2l import torch as d2l
import os
print(os.path.abspath(os.path.dirname(d2l.file)))这个代码是找到地址的。找到torch.py用记事本打开然后把相应的函数放进去,如果注释是中文还是不行,可以删掉注释

1 Like
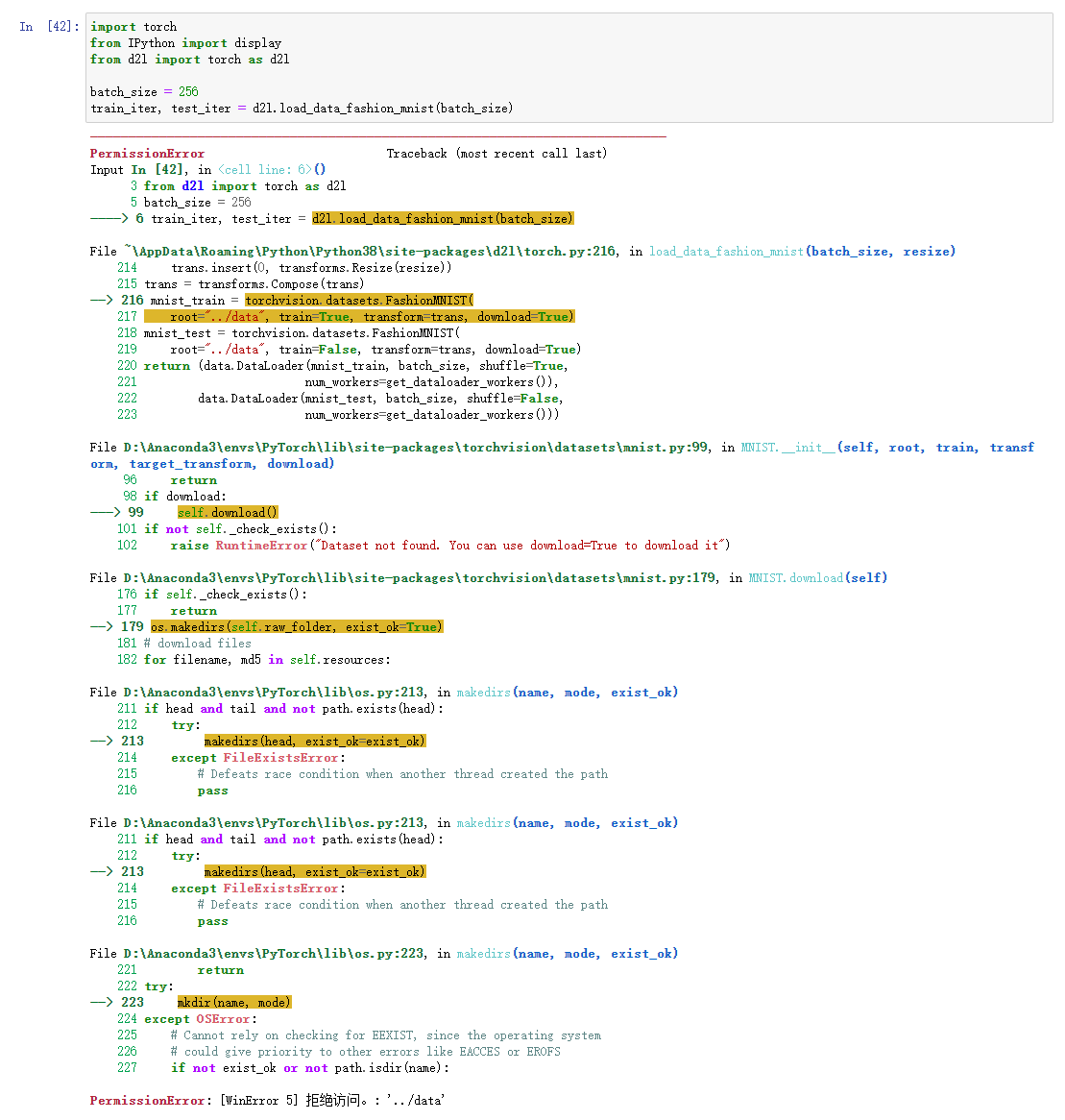
从零实现的过程中出现了参数的梯度为’None’的问题,思前想后还是不知道问题出现在哪里?求助大家帮忙看看,谢谢啦!
import torch
from torchvision import transforms
from torch.utils import data
import torchvision
from torch import nn
#==============读取数据集
def get_dataloader_workers():
"""使用4个进程来读取数据"""
return 4
def load_data_fashion_mnist(batch_size,resize=None):
"""下载Fashion-MNIST数据集,然后将其加载到内存中"""
trans = [transforms.ToTensor()]
if resize:
trans.insert(0,transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(
root="../data",train=True,transform=trans,download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="../data", train=False, transform=trans, download=True)
return (data.DataLoader(mnist_train,batch_size,shuffle=True,num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test,batch_size,shuffle=False,num_workers=get_dataloader_workers()))
batch_size = 256
train_iter,test_iter = load_data_fashion_mnist(batch_size)
#=============初始化模型参数
num_inputs, num_outputs, num_hiddens = 784,10,256
# 权重随机初始化,偏置初始化为零
W1 = torch.randn((num_inputs,num_hiddens),requires_grad=True)*0.01
b1 = torch.zeros(num_hiddens,requires_grad=True)
W2 = torch.randn((num_hiddens,num_outputs),requires_grad=True)*0.01
b2 = torch.zeros(num_outputs,requires_grad=True)
#===========激活函数
def relu(X):
a = torch.zeros_like(X)
return torch.max(X,a)
def softmax(X):
Exp_x = torch.exp(X- X.max(dim=1, keepdim=True)[0])
partition = Exp_x.sum(axis=1,keepdim=True)
return Exp_x / partition
#===========模型
def mlp(X):
"""接收输入数据"""
X = X.reshape((-1,num_inputs)) #展平图像为784的长度
H = relu(torch.matmul(X,W1) + b1) #隐藏层
O = softmax(torch.matmul(H,W2) + b2)
return O
#===========损失函数
def cross_entropy_loss(y_hat,y):
return -torch.log(y_hat[range(len(y_hat)),y])
#===========训练
def accuracy(y_hat,y):
"""计算预测正确的数量"""
# if y_hat a matrix
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
# get the max value in y_hat which denotes the category prediction
y_hat = y_hat.argmax(axis=1)
# == symbol is veray sensitive to the dataType
cmp = y_hat.type(y.dtype) == y
# 返回正确预测的数量
return float(cmp.type(y.dtype).sum())
# 定义优化器
def sgd(params,lr,batch_size):
"""小批量随机梯度下降"""
with torch.no_grad():
for param in params:
param -= lr*param.grad/batch_size
param.grad.zero_()
#============训练
lr = 0.03
num_epochs = 3
net = mlp
loss = cross_entropy_loss
def train():
for epoch in range(num_epochs):
for X,y in train_iter:
# 前向传播
y_hat = net(X)
print(y_hat[0])
print(y_hat.shape)
print(y)
# 计算损失
l = loss(y_hat,y)
print("The shape of loss: ",l.shape)
# 反向传播
l.mean().backward()
assert b2.grad is not None,"b2.grad is none"
assert W2.grad is not None,"W2.grad is none"
# 梯度更新
sgd([W1,b1,W2,b2],lr,batch_size)
with torch.no_grad():
train_l = loss(net(X),y).mean()
print(f' epoch {epoch+1}, loss {float(train_l.mean()):f}')
if __name__=="__main__":
train()
将权重和偏置的参数定义修改为如下,则可进行训练
W1 = nn.Parameter(torch.randn((num_inputs,num_hiddens),requires_grad=True)*0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens,requires_grad=True))
W2 = nn.Parameter(torch.randn((num_hiddens,num_outputs),requires_grad=True)*0.01)
b2 = nn.Parameter(torch.zeros(num_outputs,requires_grad=True))
这是为什么呢?之前在线性回归网络的从零实现中不就是直接定义的参数吗,并没有用到nn.Parameter().
我必须把reduction=‘none’去了才能正常训练,否则acc一直是0.1左右,相当于没训练,是什么原因?
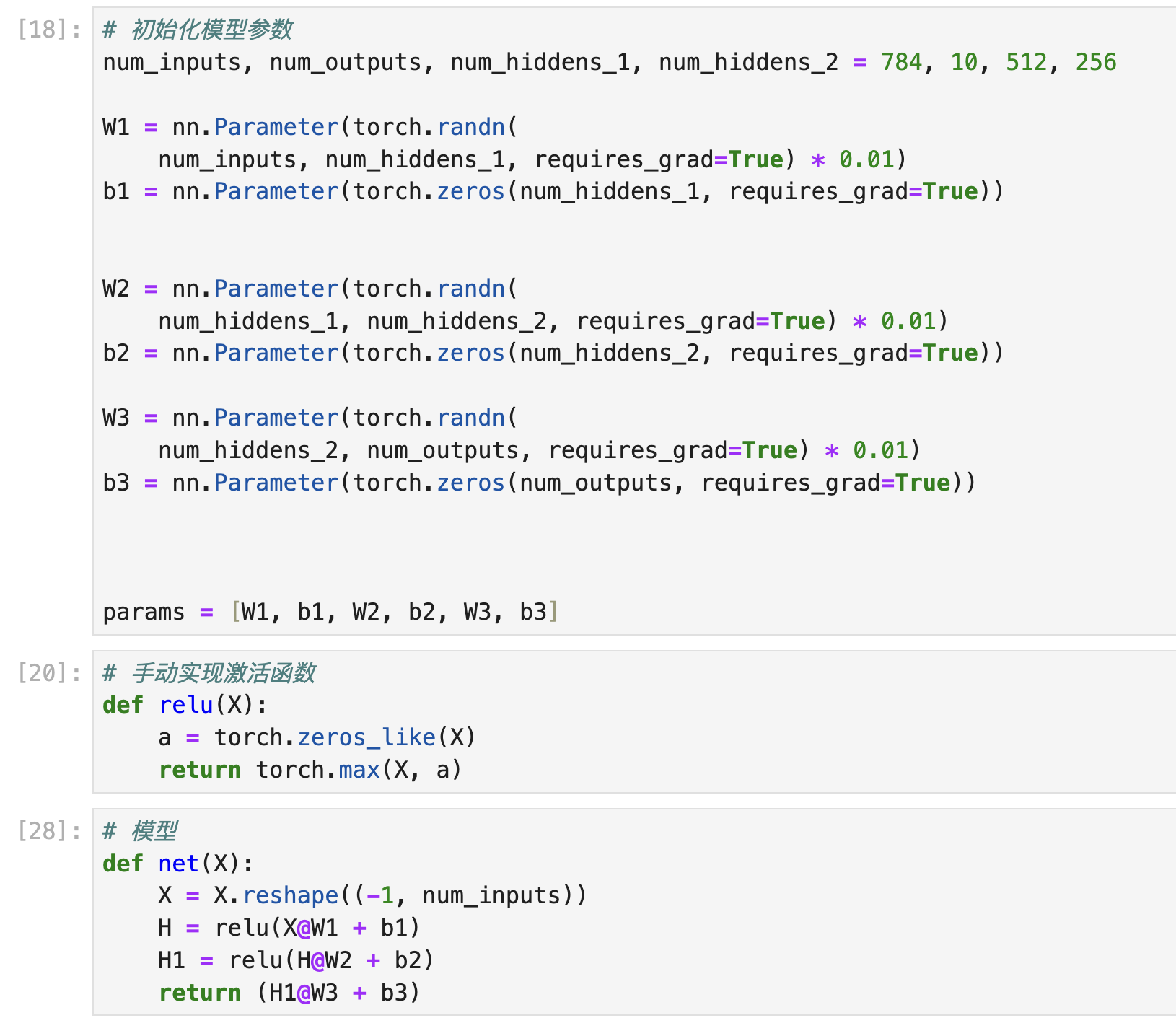
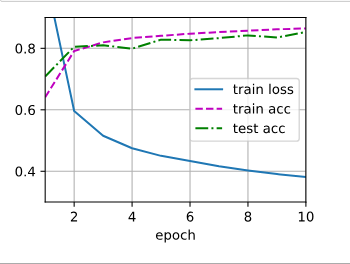
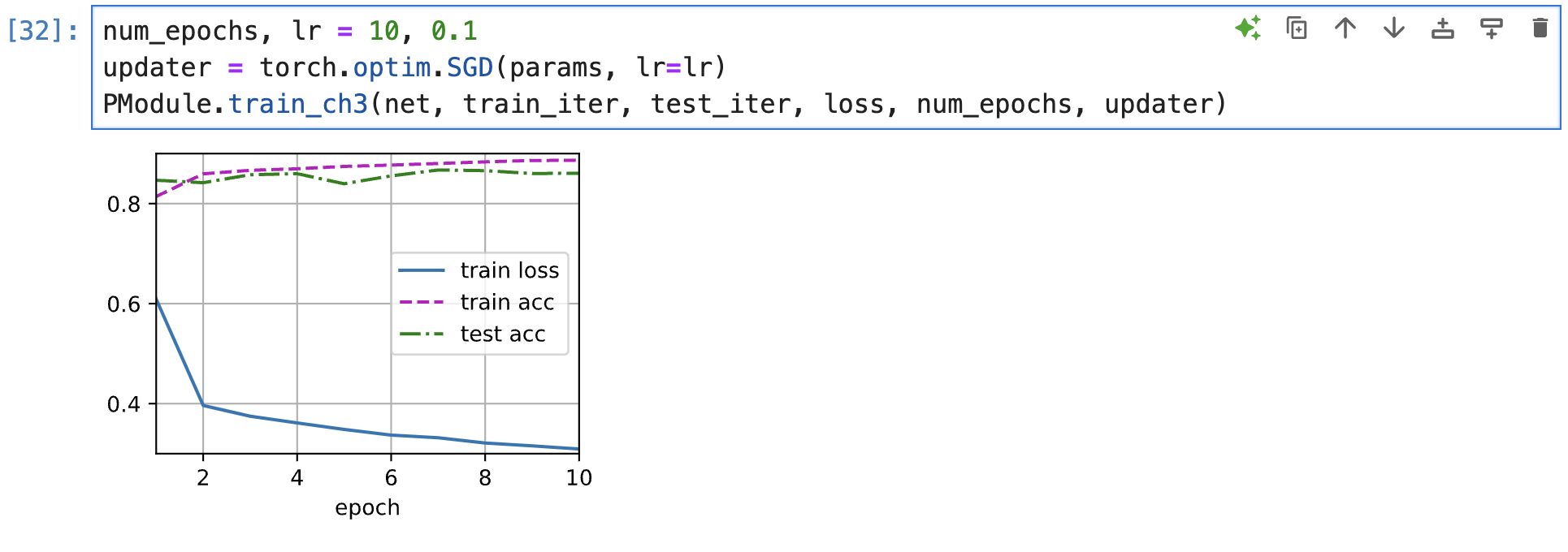
I set two hidden layers, which first layer have 512 neurons and second layer have 256 neurons, the results show in picture, the loss is lower than I expected.
我不理解啊,为什么我把这里的loss函数换成之前自己定义的cross_entropy就废了呢