128个参数的隐藏层应该算是比较好的了,尝试性增加了层数反而test acc非常的不稳定,最后降低了学习率增加了次数。这个应该算是我调到目前比较好的
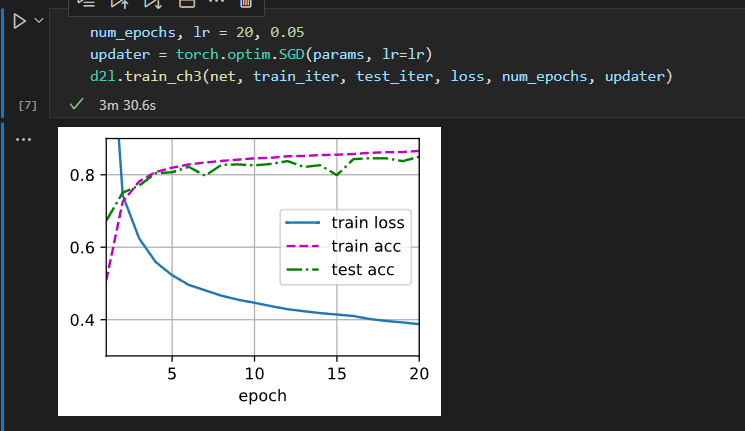

1.在学习率不变和训练次数不变的情况下,增加隐藏单元的数量,train loss 会明显降低 test acc 曲线也会更加平滑
实验如下:
num_hiddens尝试了4,8,16,32,64,128,512 学习率0.1,num_eporch=20不变
num_hiddens = 4 train loss > 0.5 直接报错了

num_hiddens = 8
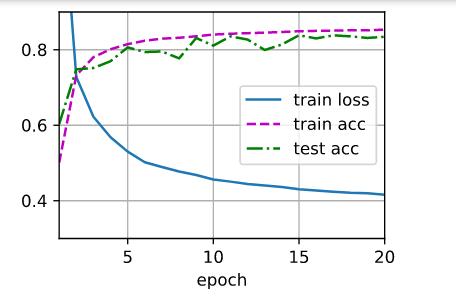
num_hiddens = 16
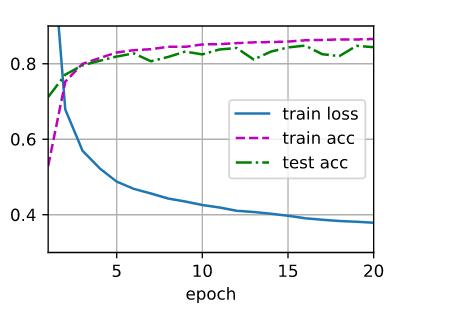
num_hiddens = 32
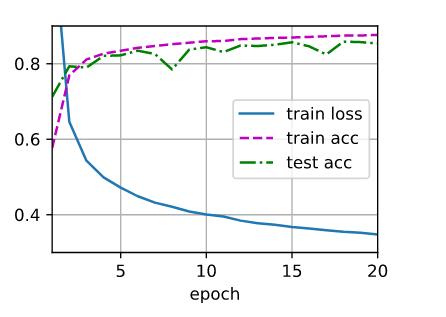
num_hiddens = 64
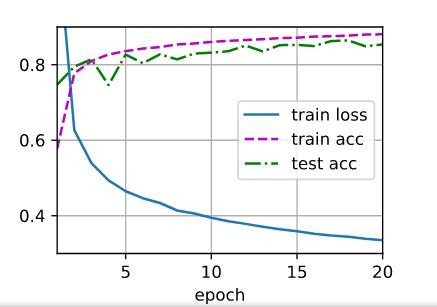
num_hiddens = 128
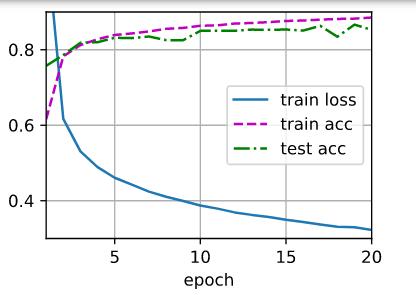
num_hiddens = 512
1 Like
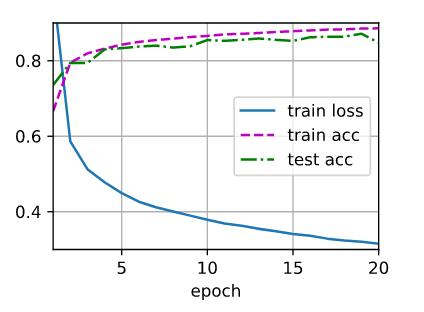
2.尝试添加更多的隐藏层,并查看它对结果有何影响。
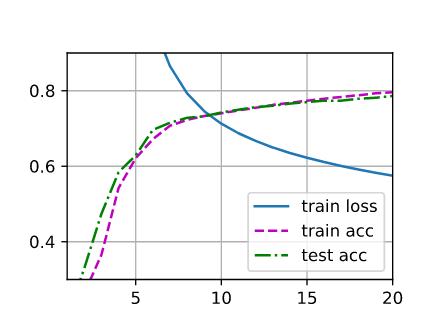
结论:增加隐藏层,发现效果反而更差了
2层 num_hiddens = 64 epoch =20 lr = 0.1
3层 num_hiddens = 64 epoch =20 lr = 0.1
4层 num_hiddens = 64 epoch =20 lr = 0.1
1 Like
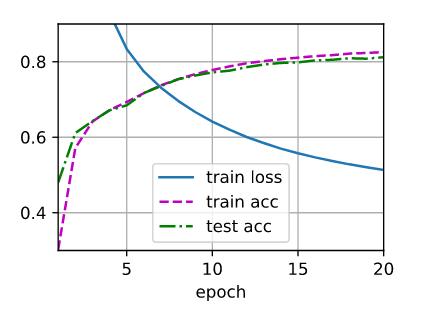
3.改变学习速率会如何影响结果?保持模型架构和其他超参数(包括轮数)不变,学习率设置为多少会带来最好的结果?
结论:学习率太大,无法训练,学习率适当增大,能够使模型尽快收敛,学习率太小,收敛太慢
epoch=20 2层网络 num_hiddens = 256
lr = 1
lr = 0.2
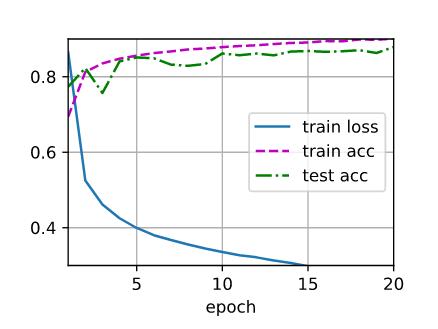
lr = 0.1
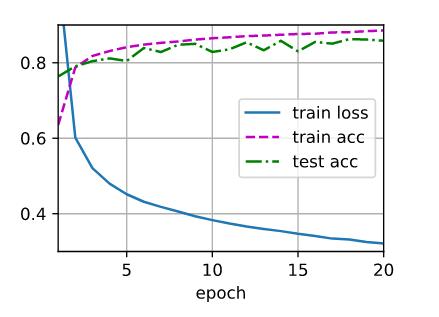
lr = 0.01
1 Like
reduction=‘none’
实在不行的话,进入d2l找到trainch3epoch那个函数,看第一个l.sum是不是在那,改成l.mean。
您好,请问一下您解决了吗?我也出现了一样的问题
增加了hidden layer后,参数更多,有更多、更复杂的模型可以选择,理论上效果肯定要比简单的模型好(因为模型的参数增加了,由更多的参数肯定可以拟合成之前参数较少的模型),但是因为可选择的模型多了,你的寻找模型的难度增加了,需要找(训练)得更久,或者换更好的寻找方法(优化算法)。
1 Like
您可以直接通过下边代码找到d2l库路径,修改d2l库的源码:
from d2l import torch as d2l
import os
print(os.path.abspath(os.path.dirname(d2l.__file__)))
我按照文章中的代码在 mac pro 上总是 AssertionError: 2.9569401362101235 报loss不能降下来,有人遇到相同的问题吗?
为什么前面的章节初始化参数没有用nn.parameter(),这一节初始化参数的时候用了,有大佬解答一下嘛
loss = nn.CrossEntropyLoss(reduction=‘none’) 为什么要加上括号里的东西
Because The loss function value is too large, resulting in no display above the image.
-
reduction (str, optional) – Specifies the reduction to apply to the output:
'none'|'mean'|'sum'.'none': no reduction will be applied,'mean': the weighted mean of the output is taken,'sum': the output will be summed.
之前取得参数标准差为0.01,方差为0.01^2.
这里乘以0.01,整体方差为0.01^2.
所以,参数分布一致,方便后续性能比较。
个人理解,欢迎勘误。
我发现,hidden layer调到16,然后优化器用adam,也能取得很好的结果
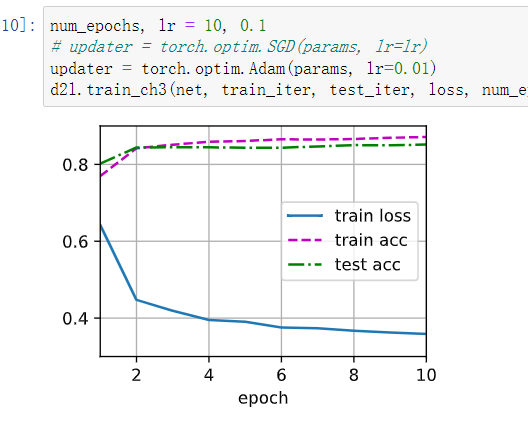
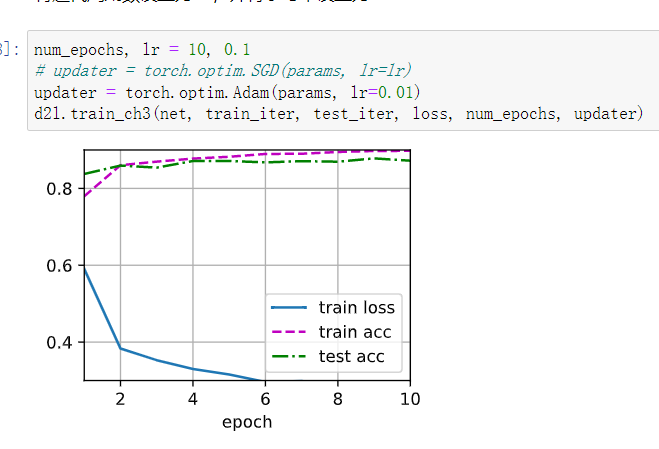
添加多一层128的层在输出前,使用adam优化器,性能进一步提升,证明了网络的深度对提取特征有很大帮助:
我从一开始就没有用notebook,直接命令行Python,把torch.py里的显示方法改一下就行了。
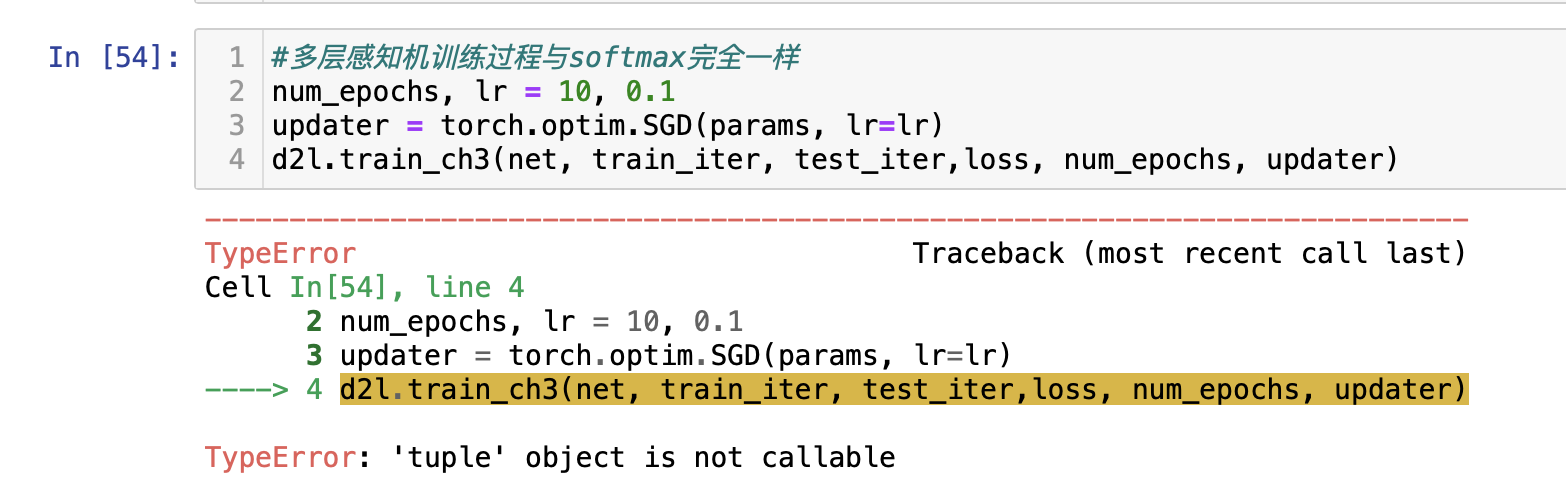
softmax放在交叉熵的损失函数里面了