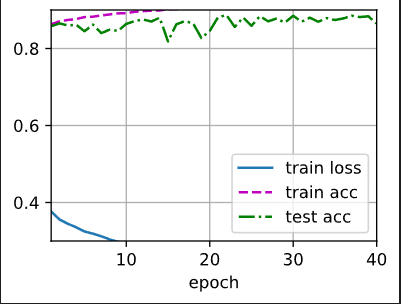
epoch:40,lr:0.1, 2 hidden , hidden num(1&2) :256
参数初始值跟书上一样吗,感觉是参数初始值不一样导致的,可能初始值大了
暴力解决方案把所有程序放进如下语句内容中
if name == ‘main’:
几个超参的影响
- Loss的reduction:默认是mean;如果用sum梯度变大,难以收敛,配合调小batchsiz、lr可以解决。
- num_hiddens:过小准确率低,过大会导致过拟合,表现train_acc>>test_acc。
- lr:过大会震荡,过小优化的慢。
- 多个超参,num_hinddens、num_layers、batch_size、lr、loss_reduction、num_epochs等参数,会互相影响,联合找到最优组合,寻优空间很大。
- 多个超参数的搜索方法?
- 经验搜索:batch_size、num_hiddens参考同类业务,重点看学习速度、震荡情况调整lr,看损失曲线、过拟合调整num_epochs。
- 随机搜索:碰运气
- 网格搜索:暴力穷举
- 基于梯度的优化方法,参与反向传播
求教各位大佬,李老师直播里面提到的将weight的初始值设为0会出现问题,我自己尝试了一下,loss跟acc会保持在一个常数不变。我的理解是sgd里对weight的导数为0,所以参数保持不变。请问我这样想是对的吗,有没有哪里有这块的数学推导,谢谢了。
-
different width of hidden layer
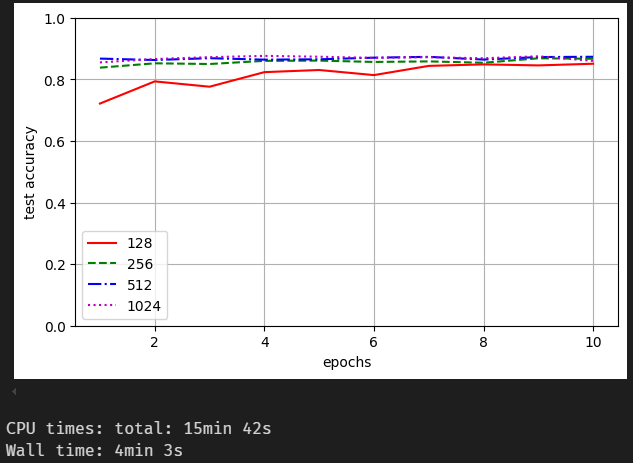
256 seems to be good enough. -
different depth of hidden layers with same width (256)
1 layer
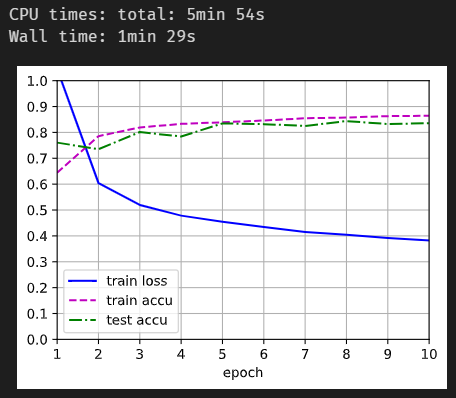
2 layers
3 layers
given the same batches of samples and other hyperparameters, the more hidden layers there are, the more time is needed for convergence, and possibly, the less accurate the model becomes. This is likely due to the activation function “ReLU”, which prevents the model from learning certain features, thereby diminishing the model’s expression. -
learning rate mostly takes effect on rate and result of convergence.
-
lists all discrete values for each hyperparameters, and uses DFS to traverse every combinations.
Submit my Work
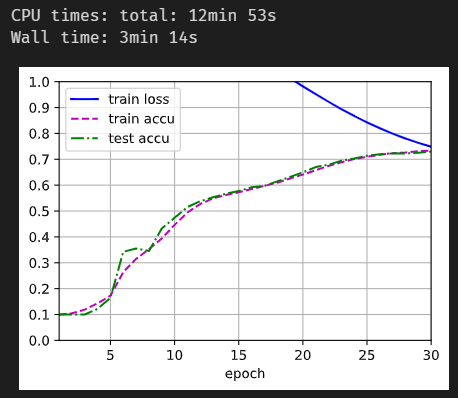
1. 似乎将隐藏层的元数提升到512准确率更好
2. 再加入了一层1024个元的隐藏层后,似乎增长更快了
也不难,数一线代学好即可
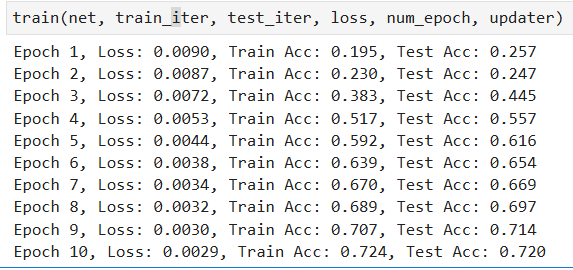
3. 学习率这我可不知道了
4. 懒得试谢谢
最新版的d2l把这个函数删了,你得下载老版本的
其实也可以用最新版的,因为源码他已经放在第3章的softmax回归那部分了。
也就是如下部分的代码:
def evaluate_accuracy(net, data_iter): #@save
“”“计算在指定数据集上模型的精度”“”
if isinstance(net, torch.nn.Module):
net.eval() # 将模型设置为评估模式
metric = d2l.Accumulator(2) # 正确预测数、预测总数
with torch.no_grad():
for X, y in data_iter:
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
def train_epoch_ch3(net, train_iter, loss, updater): #@save
“”“训练模型一个迭代周期(定义见第3章)”“”
# 将模型设置为训练模式
if isinstance(net, torch.nn.Module):
net.train()
# 训练损失总和、训练准确度总和、样本数
metric = d2l.Accumulator(3)
for X, y in train_iter:
# 计算梯度并更新参数
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad()
l.mean().backward()
updater.step()
else:
# 使用定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()), d2l.accuracy(y_hat, y), y.numel())
# 返回训练损失和训练精度
return metric[0] / metric[2], metric[1] / metric[2]
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save
“”“训练模型(定义见第3章)”“”
animator = d2l.Animator(xlabel=‘epoch’, xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=[‘train loss’, ‘train acc’, ‘test acc’])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
我把这里的loss函数换成之前自己定义的cross_entropy,然后报错:(
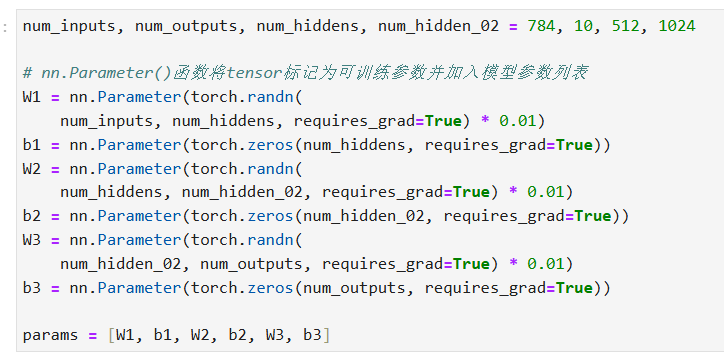
参数初始化使用这个:
input_size = 28*28
hidden_size = 256
output_size = 10
# 初始化参数
W1 = torch.normal(0,0.01,size=(input_size,hidden_size),requires_grad=True)
b1 = torch.zeros(hidden_size,requires_grad=True)
W2 = torch.normal(0,0.01,size=(hidden_size,output_size),requires_grad=True)
b2 = torch.zeros(output_size,requires_grad=True)
params = [W1,b1,W2,b2]
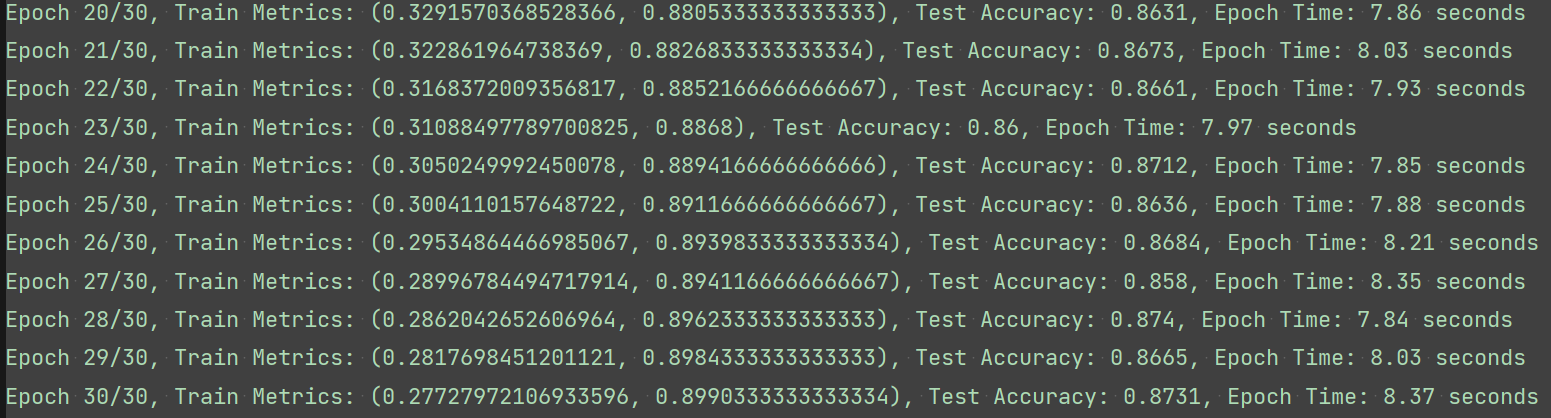
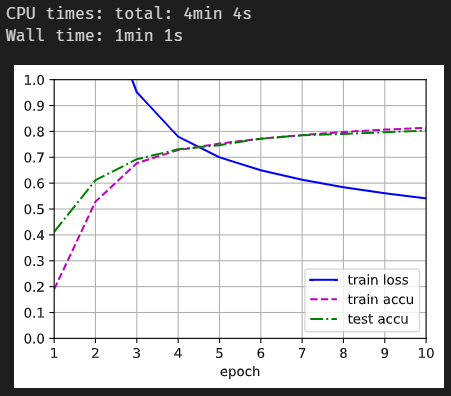
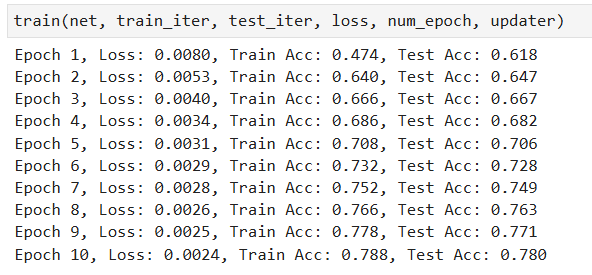
训练结果如下:
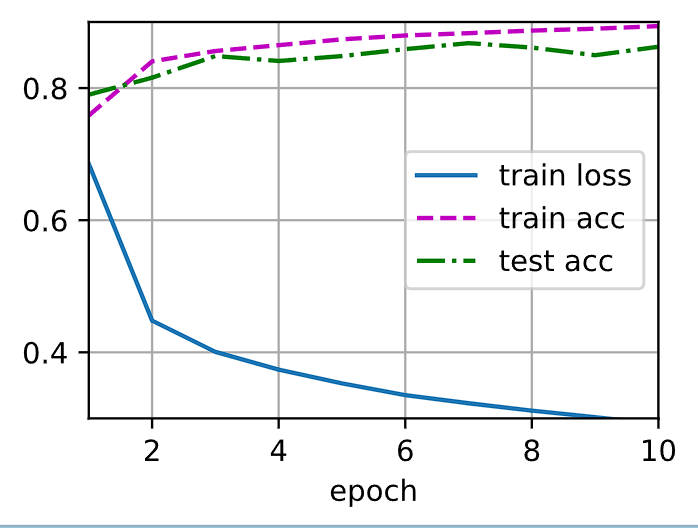
为什么loss和acc和教程中使用的参数初始化方式得出的训练结果相差有点大?
感觉效果更好了?
【小白,刚开始学习,希望有大佬能解释一下两种参数初始化的区别】