现在还是在用cpu训练,要使用gpu的话需要把模型等to devices(cuda)
我也遇到了。从实验结果看,使用uniform必须保持区间对称,[-1,0]、[0,1]、[-2,1]、[-1,2]都会遇到梯度消失的问题,原因不清楚。
请问这么设置区间,背后的原理或者说原因是什么呢?
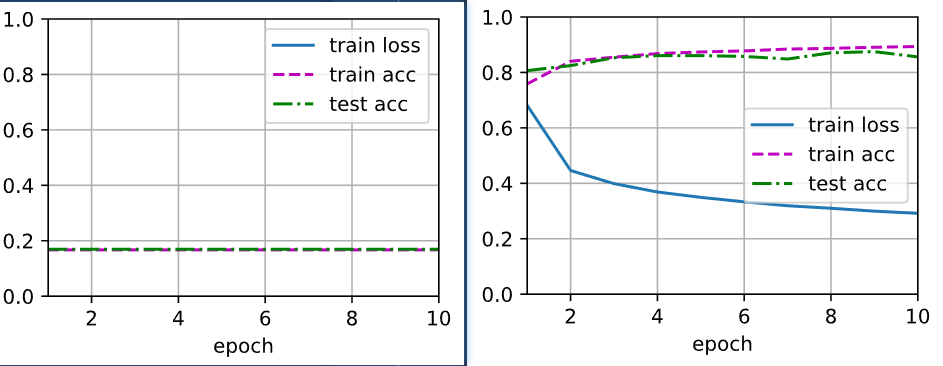
在使用uniform分布初始化线性层权重时遇到个问题——如果分布区间关于y轴不对称,模型就会因为梯度消失而无法正常工作,具体结果如下,同时也尝试了类似[-2,1]、[-1,2]等更多的非对称区间,无一例外。
有哪位同学能解释一下原理吗?先行谢过 ![]()
a=-1, b=1
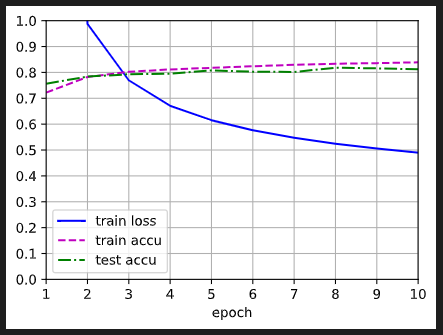
a=0, b=1
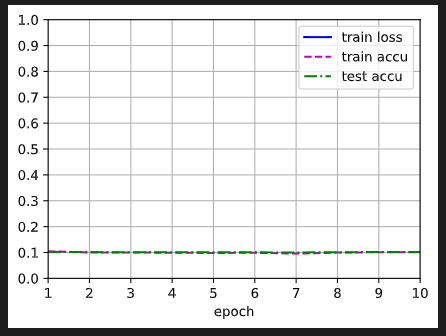
a=-1, b=0
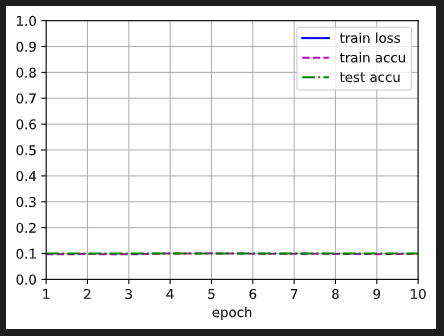
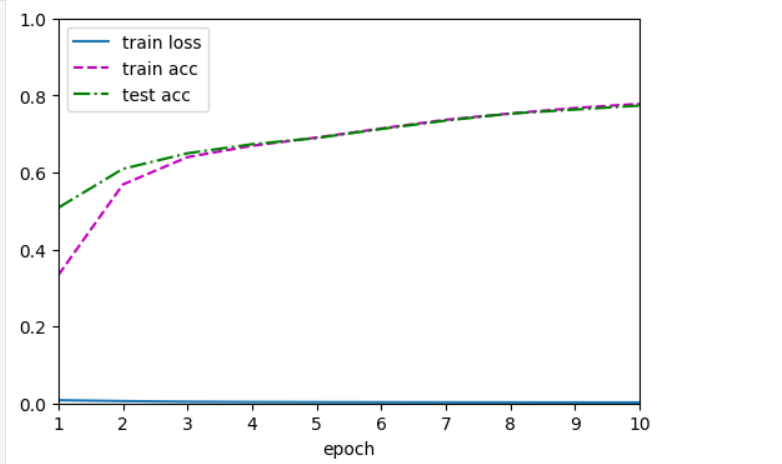
修改了一下网络的层数,多加了一层隐藏层,同时把epoch调为20,训练的结果loss还挺低的,我的net长这样:
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 64),
nn.ReLU(),
nn.Linear(64, 10))
训练的结果长这样:
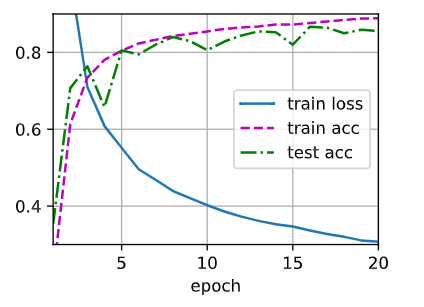
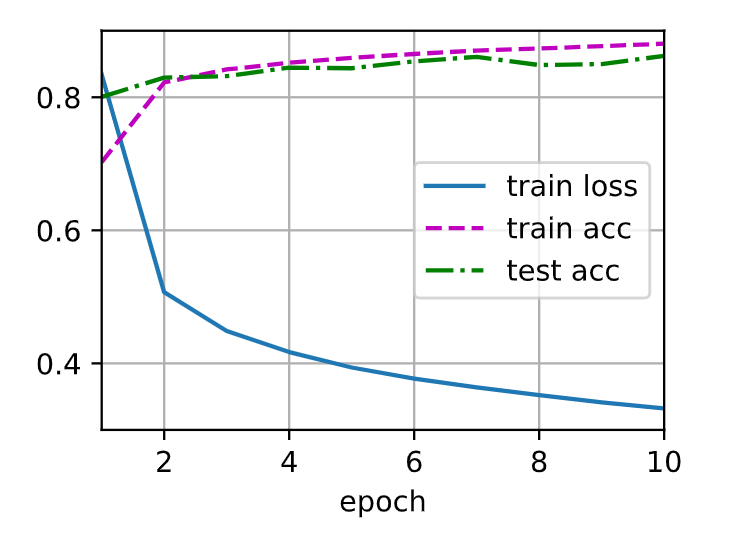

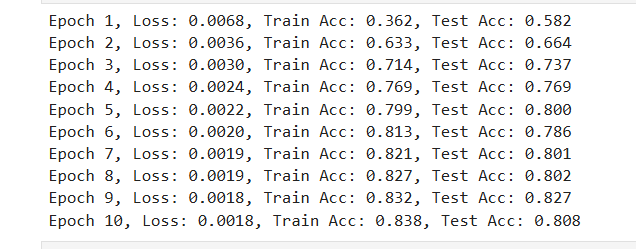
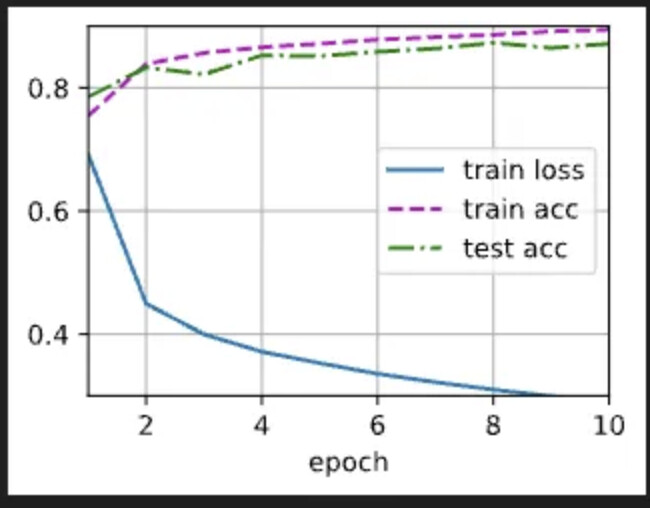
有可能只是训练轮数不够,sigmoid需要的轮数多一些?多训练一些轮,最终结果是不是一样的呢?
请问您这个解决了吗,我这个也有这个问题。
为什么会出现assert预警呢,我是按照书上打的代码。
结果每次,输出的loss高达2.0以上,nn.CrossEntropyLoss,交叉熵应该不会返回大于1的损失吧,怎么会这样呢
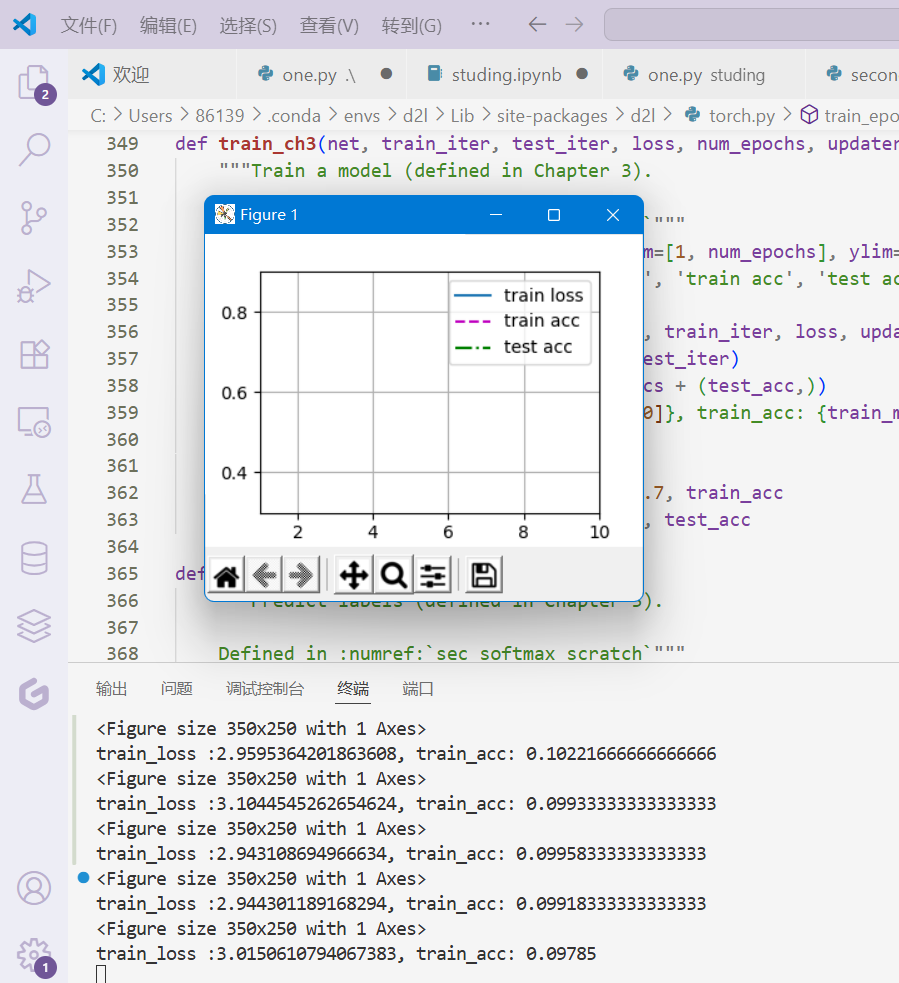
代码:
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
请问一下简洁实现中没有对bias初始化官方文档写的是均匀分布初始化,但是从零开始的bias取的全是0吗?
看看loss = nn.CrossEntropyLoss(reduction=‘none’) 引号内是不是none,或者train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)是不是用的trainer,再不行就重启jupyter的kernel