https://zh.d2l.ai/chapter_multilayer-perceptrons/mlp-concise.html
I think the semicolon in the last line of 4.3.1 Model is unnecessary.
1 Like
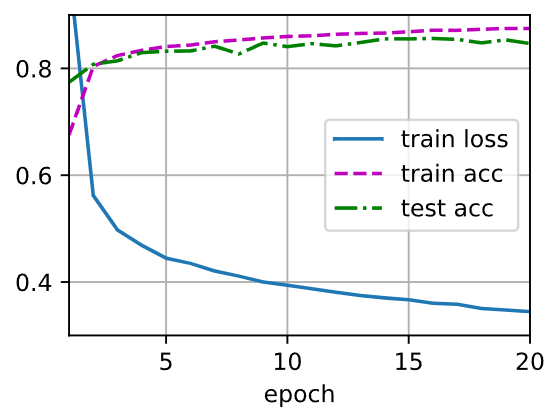
不同激活函数测试结果:
Tanh:
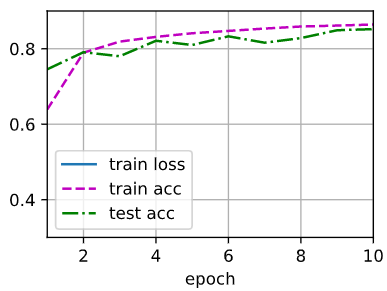
Relu:
Sigmoid
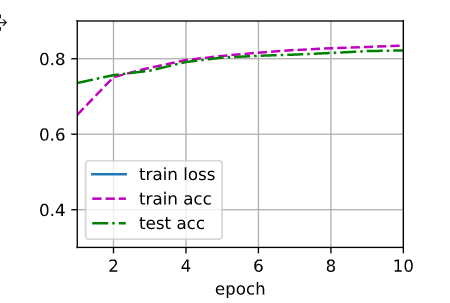
Sigmoid看上去更好,波动小,准确率高。
为什么 train loss的曲线不显示,是因为太小了吗
使用cpu和gpu版本的pytorch可能结果不一样,我的cpu训练收敛曲线比gpu要平滑许多
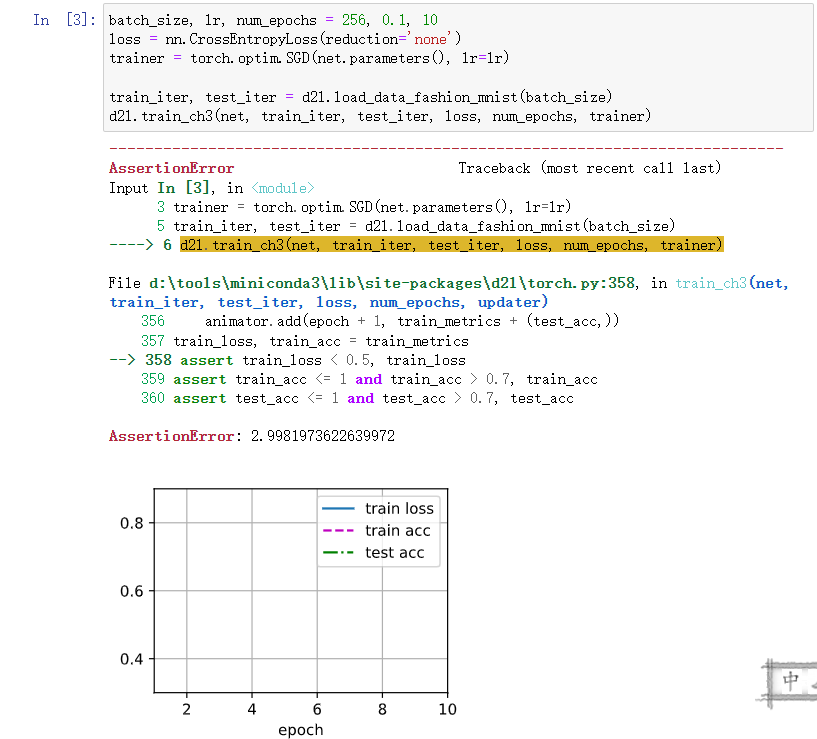
是训练损失太大了报错了,之前我跑的epoch比较少,训练损失还是大于0.5就会报错。
从代码实现来看,d2l.train_ch3()里面调用的画图函数应该是针对jupyter notebook写的,我用pycharm显示不了。你可以在训练完后加一句d2l.plt.show(),使画的图显示出来。
老师,在使用init_weights初始化参数时,m.weight是否只是对w矩阵进行了初始化?不需要对b进行初始化吗?
2 Likes
https://pytorch.org/docs/stable/generated/torch.nn.Linear.html#torch.nn.Linear
这里说了,nn.Linear的weight和bias会自动初始化,这里使用init_weight只是不希望采用对weight的默认初始化,对bias采用默认初始化就可以
3 Likes
loss=nn.CrossEntropyLoss(reduction=‘none’)
这些assert就是为了在训练完之后,判断一下loss和accuracy是否在预期值之内,不在的话就报个error。没别的用。
2 Likes
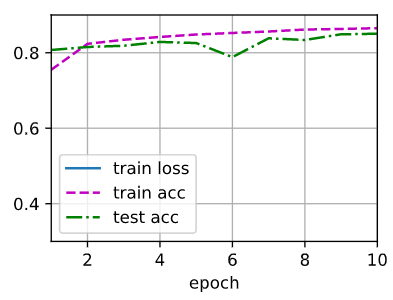
各位同学好,我是用均匀分布对Linear层的weight做初始化。
得到的结果是这样子的。
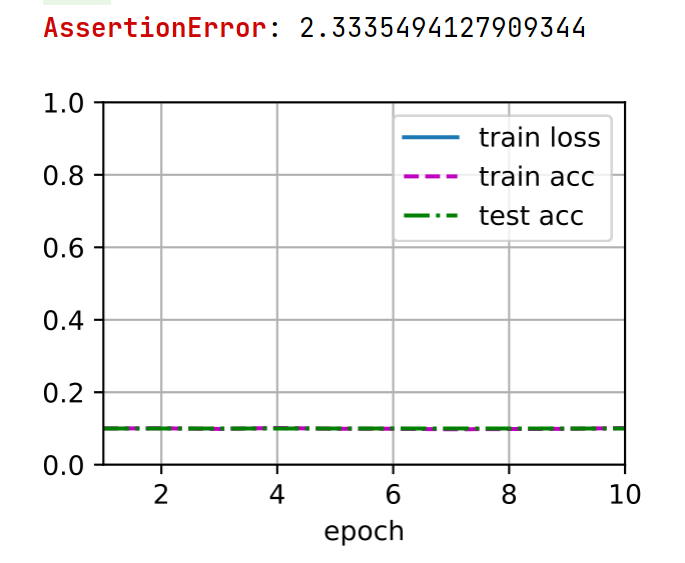
代码如下
import torch
from torch import nn
from d2l import torch as d2l
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
"""Train a model (defined in Chapter 3).
Defined in :numref:`sec_softmax_scratch`"""
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1.0],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics = d2l.train_epoch_ch3(net, train_iter, loss, updater)
test_acc = d2l.evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.Tanh(),
nn.Linear(256, 128),
nn.Tanh(),
nn.Linear(128,10)
)
def init_weights(m):
if type(m) == nn.Linear:
nn.init.uniform_(m.weight)
nn.init.zeros_(m.bias)
#nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
我检查了初始化后的weight,发现权重并不是对称的,但仍然无法训练。

1 Like
我将均匀分布的区间改为-1到1之后可以正常训练了。Pytorch默认是0到1的均匀分布。
但是仍未解决我的问题。
def init_weights(m):
if type(m) == nn.Linear:
nn.init.uniform_(m.weight,-1.0,1.0)
nn.init.zeros_(m.bias)
#nn.init.normal_(m.weight, std=0.01)
2 Likes
怎么知道我现在是用CPU还是GPU在训练呢?
pip install --upgrade d2l就能解决
尝试更改初始化权重或者lr,发现改了初始化权重以后有用。怀疑初始化权重太小了,导致w变化太小了。
使用四层网络+ReLU
batch_size, lr, num_epochs = 256, 0.2, 40
net = nn.Sequential(nn.Flatten(),
nn.Linear(784,256),
nn.ReLU(),
nn.Linear(256,64),
nn.ReLU(),
nn.Linear(64,32),
nn.ReLU(),
nn.Linear(32,10)
)
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
batch_size, lr, num_epochs = 256, 0.2, 40
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = load_data_fashion_mnist(batch_size)
train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
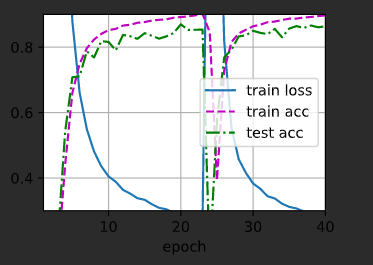
看起来使用 batch_size, lr, num_epochs = 256, 0.2, 20
会让准确率非常高和loss很低,增加epochs会导致过拟合
epochs = 20, lr = 0.01
ReLU:
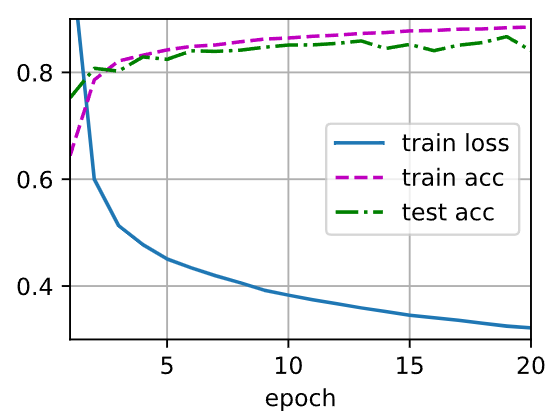
1 Like
Tanh: