Sigmoid:
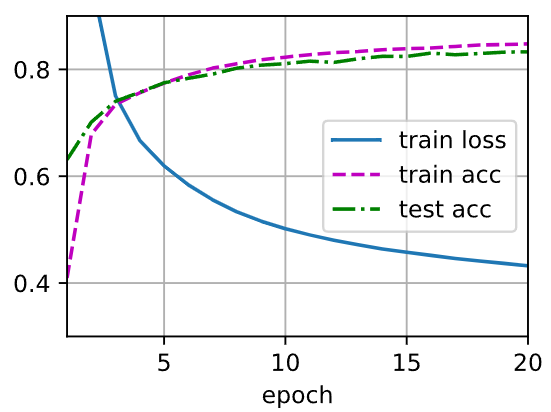
还有比我更牛逼的吗?
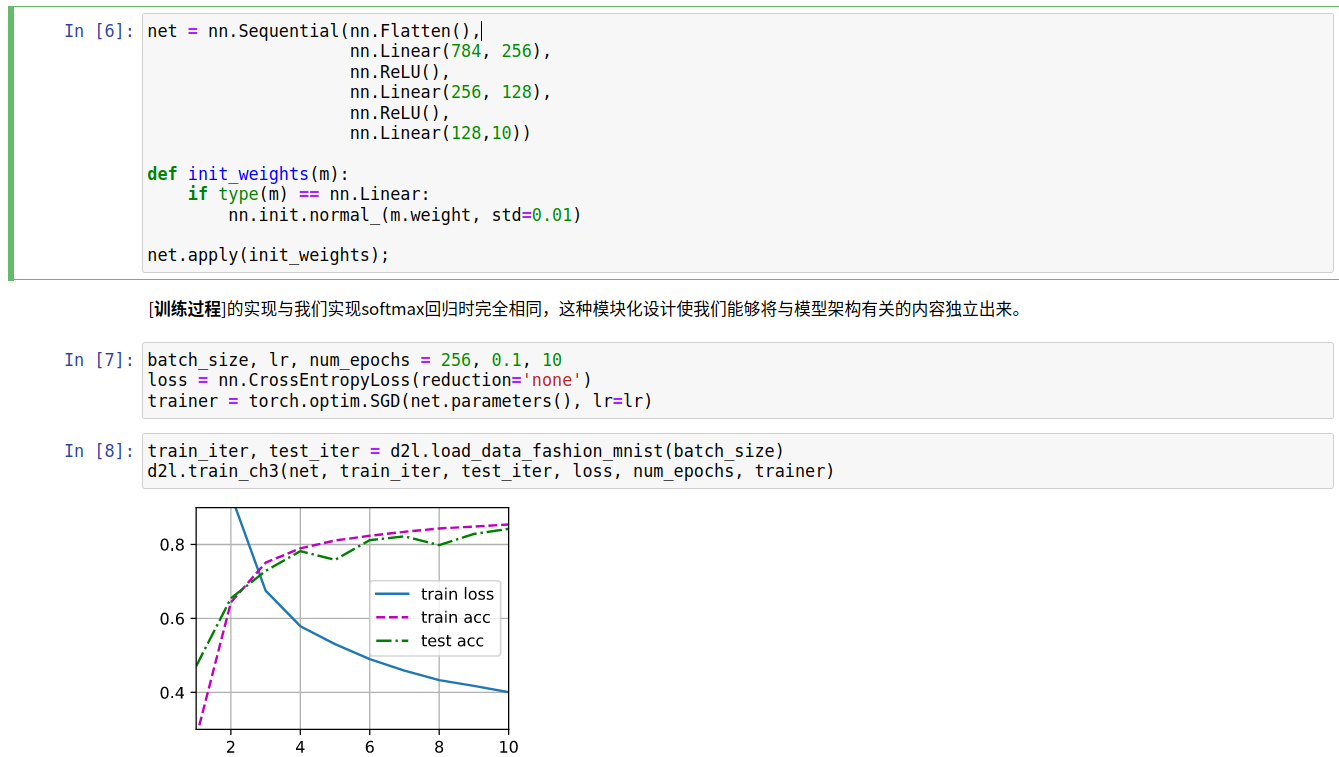
调整了层数和batch_size,代码和结果如下:
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(nn.Flatten(),nn.Linear(784,512),nn.ReLU(),nn.Linear(512,256),
nn.ReLU(),nn.Linear(256,64),nn.ReLU(),nn.Linear(64,10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight,std=0.01)
net.apply(init_weights);
batch_size,lr,num_epochs = 64,0.1,10
loss = nn.CrossEntropyLoss(reduction=‘none’)
trainer = torch.optim.SGD(net.parameters(),lr=lr)
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,trainer)
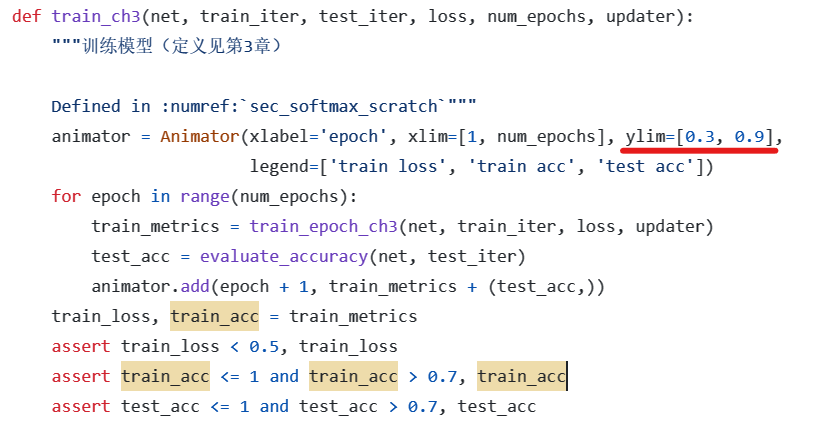
均值初始化时,需要将a b范围设置为-1/sqrt(n) 和 1/sqrt(n),n是每层的权重个数。
nn.init.uniform_(m.weight, a = -1/len(m.weight) ** (1/2), b=1/len(m.weight) ** (1/2) )
def init_weights(m):
if type(m) == nn.Linear:
# nn.init.normal_(m.weight , mean = 0 ,std = 0.01) # 正态分布
nn.init.uniform_(m.weight, a = -1/len(m.weight) ** (1/2), b=1/len(m.weight) ** (1/2) ) # 均匀分布
# nn.init.eye_(m.weight) # 填充1 使得特征尽可能多的保留
# nn.init.dirac_(m.weight) # 用dirac 函数填充 ,尽量保持卷积层中的特征
可以试试填充1的初始化权重 效果也挺好
1 Like
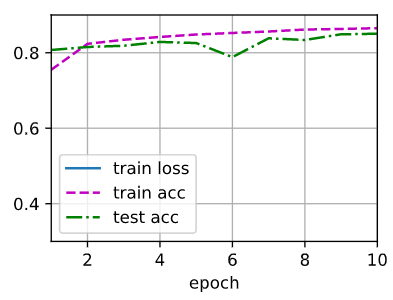
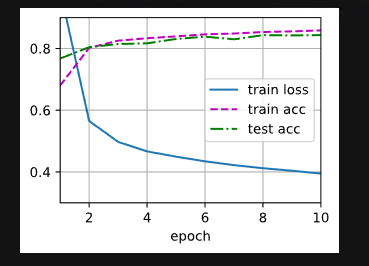
你确定是sigmoid更好么
为什么我看这个图最后的 train_acc 和 test_acc 都比前两个更低啊 , 明显Tanh更好啊
3 Likes
如果出现过拟合的话,该怎么解释 train_acc 的降低和 train_loss 的增大呢?
Original:
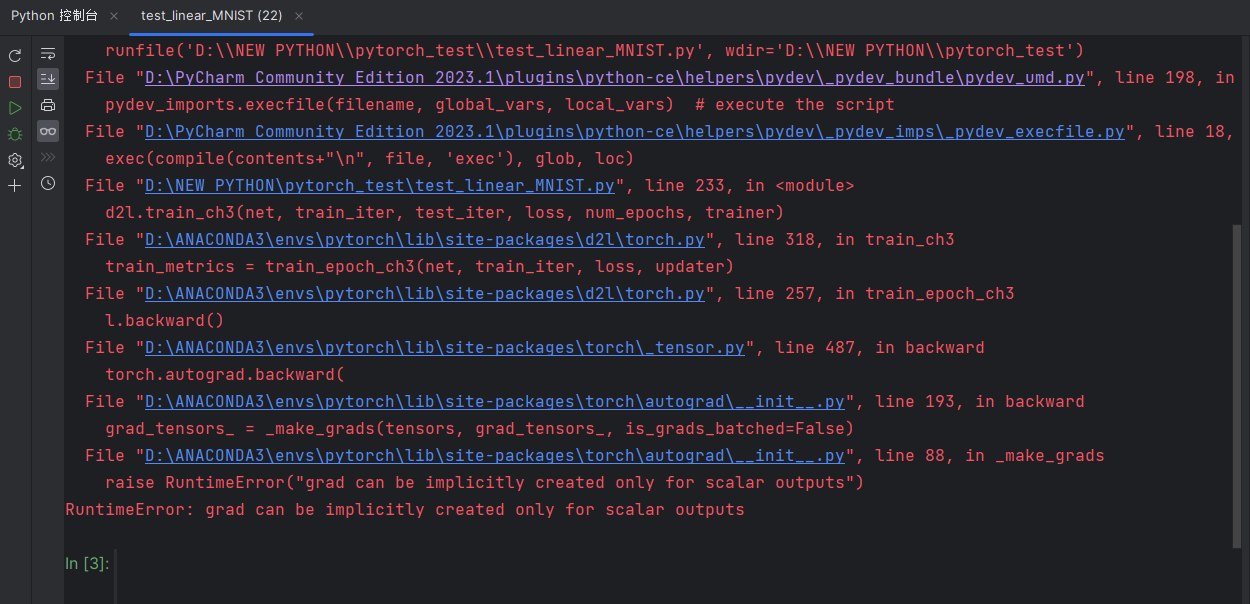
升级了,反而#@save保存不到d2l是因为什么,现在是1.0.3
1 Like
TANH:
SIGMOID:
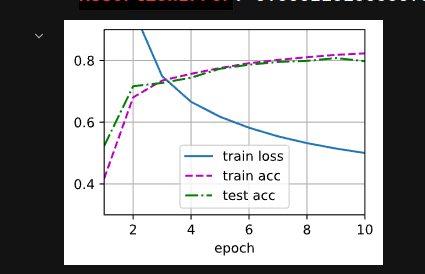
RELU:
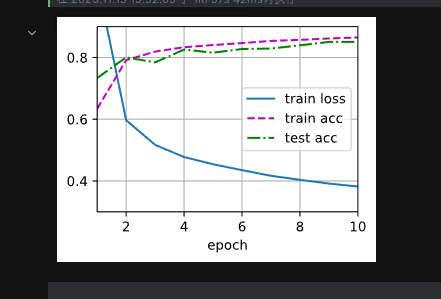
你好,请问你的trian loss 是怎么显示出来的,为什么我的损失图像没有trian loss,即使调整了显示的范围,是因为loss太大了吗
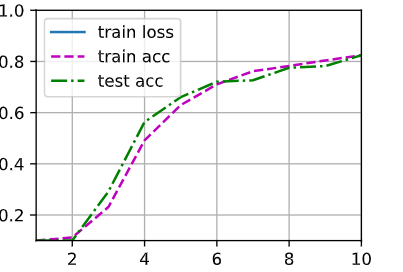
是太小了
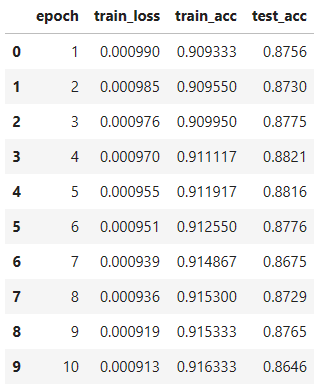
我把loss打印出来看了
我感觉本来就没有保存功能。#@save只是示意以后可以直接用d2l.xxx,因为d2l原本就有xxx
python运行一下:
device = torch.device(‘cuda’ if torch.cuda.is_available() else ‘cpu’)
print(f"Using device: {device}")
##检查是否用到cuda
把loss=nn.CrossEntropyLoss(reduction=‘none’)改成loss=nn.CrossEntropyLoss()
想问下各位大佬,我在anaconda上配好了pytorch,在pycharm中运行,GPU-cuda那些都按照教程一步步搞好了,运行这段代码的时候,我看了一下任务管理器,CPU的占用率将近40%,结果独显的占用率就1%,0%,这是为啥啊
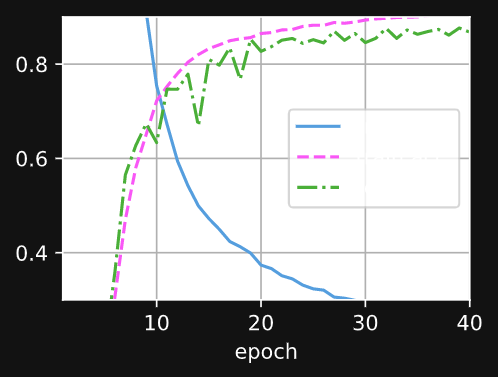
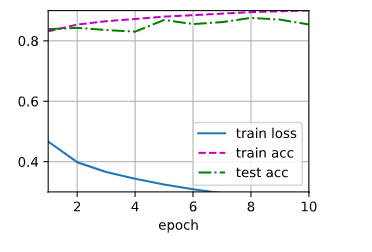
依次是 64, 128, 256



可以看到 64 ,损失很大。且训练遇到瓶颈,训练不能增加准确率。
256 训练损失还很大,10个epoch还没有收敛


对比 96 和 160 , 都没有收敛的很好

这个160 的训练结果,它运气比较好,10个eopch时收敛的很好。延长epoch可以训练的更好。