在windos里 不能多线程,把4改成1,在linux里才可以多线程
show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y));
请问运行这行代码的时候jupyter核为什么会自动死亡呢?
不加分号会显示一个类别array,加了分号不会显示出图像,并且核自动死亡。
代码复用, 便于修改,动态设置。 这些都是为什么可能想要创建一个单独的函数来确定num_workers 数量的理由。然而,对于简单的代码,或者你确定num_workers 不会改变的情况下,直接设置num_workers 为一个常数也是完全可以的。
2 Likes
将图像尺寸从原始的28x28像素调整为64x64像素是为了实验目的(比如看看尺寸变化如何影响模型的性能)。你可以根据自己的实际需求来决定是否需要调整图像尺寸,以及如何调整。
1 Like
笨方法,非常慢
a=torch.arange(4,516,4).tolist()
b=torch.zeros(int(torch.arange(4,516,4).shape[0]))
def get_dataloader_workers(): #@save
“”“使用4个进程来读取数据”“”
return 4
for batch_size in a:
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers())
timer = d2l.Timer()
for X, y in train_iter:
continue
b[(batch_size-4)//4]=timer.stop()
图象是
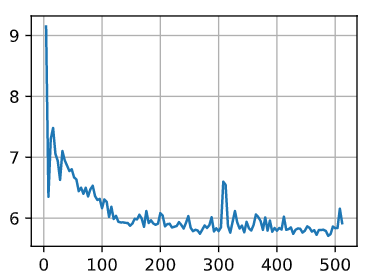
应该把间距和范围改大,这样画出来曲线光滑而且更能说明256的合理性
这代表X有四个维度,大小分别是32,1,64,64.含义分别是X所含图片的数量,灰度值,图片的h,图片的w
X,y = next(iter(data.DataLoader(mnist_train, batch_size=18)))
show_images(X.reshape(18,28,28), 2, 9, titles=get_mnist_labels(y))
是不是每次运行这段代码都应该出现新的18幅图像呢?可是我的没有出现
想问一下这个trans = transforms.ToTensor()是干嘛的
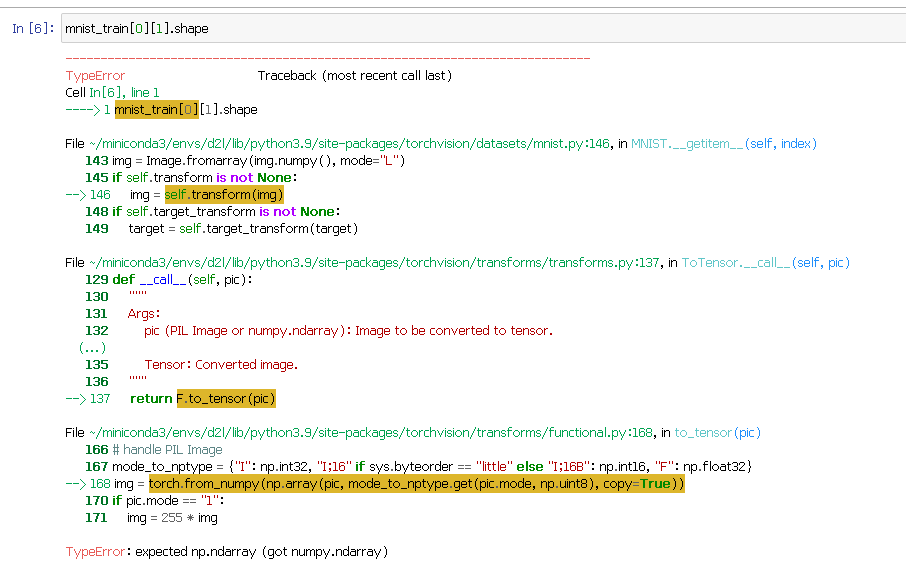
另外这里为啥有个[0][0],mnist_train[0][0].shape
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
如果resize 为True, 那么trans 就是一个数组[resize trans, totensor trans],这里的Compose主要是为了将两个trans组合在一起
加一行d2l.plt.show()[quote=“lsadfj_dslfj, post:38, topic:1787, full:true”]
查看数据集图片的函数是少了show()么
[/quote] 为什么要打满20个字符iwjdsidj
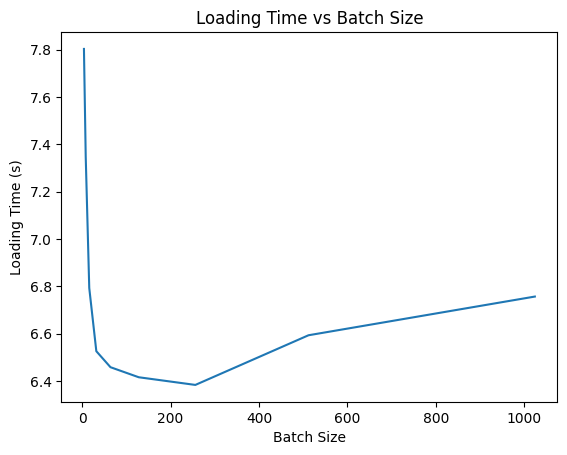
我要6秒多…
train_iter,test_iter = load_data_fashion_mnist(32,64)
if name==“main”:
for X,y in train_iter:
print(X.shape,X.dtype,y.shape,y.dtype)
break
改成这样即可运行
不会出现新的,因为每次都是初始化一个新的迭代器,所以X, y每次都是训练集的第一个batch(前18张图像)的数据。
“train=True“表示下载训练集,训练集样本量为60000。
“train=False“表示下载测试集,测试集样本量为10000。
分号表示不显示函数返回值(这个函数的返回值是坐标轴)。
四个数字分别是:批量大小,通道数,高,宽