https://zh.d2l.ai/chapter_linear-networks/image-classification-dataset.html
1.Yes. With the batch_size 1, it took me 37.22 seconds to read the dataset.
2.Pass.
3.e.g. ImageNet, Qmnist and Kinetics-400.
3 Likes
It is so confusing that you answered the question in English, but you didn’t read the English version directly.
https://d2l.ai/
我本来觉得阅读中文版速度会快一些,但是目前看来中文版的翻译有些地方还是有点晦涩。可能之后转向看英文版?
1 Like
读取性能随batch_size大小的影响图。可以看到256确实是个很合理的batch_size。
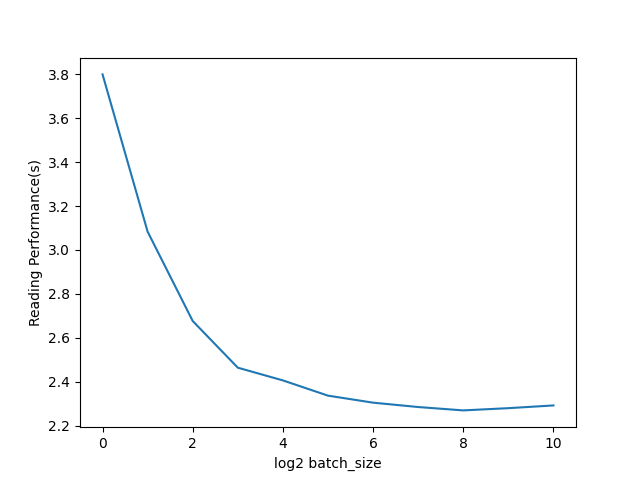
12 Likes
mnist_train[0][0].shape
I want to know what the numbers in the two square brackets represent. Can someone help me?
It’s the index of the tensor, which is line 0 col 0.
mnist_train[0][0].shape #this line is used to print the shape of a typical tensor in the data set(which is train set in this case).
The output is torch.Size([1, 28, 28]) .Represents ([channal,height,width]) .
It’s a grayscale image, so it’s channal will be 1.
2 Likes
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers())
运行到这段程序时,一旦 num_workers>0就会报错,请问如何解决?
使用if name == ‘main’:也不行
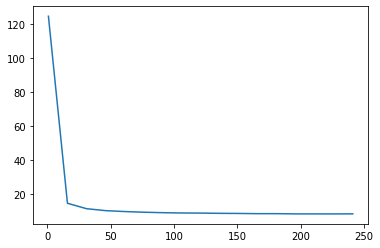
Ax_x is batch size, Ax_y is the time cost. It’s true larger batch size the time cost is much less.
5 Likes
我也遇到了相同的问题
把含有多线程操作的部分放在这个里面可以实现
if __name__ == '__main__':
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers())
timer = d2l.Timer()
for X, y in train_iter:
continue
print(f'{timer.stop():.2f} sec')
1 Like
104.9%
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz
Downloading http://xxx.xx.xxx.xx/ to …/data/FashionMNIST/raw/train-images-idx3-ubyte.gz
RuntimeError Traceback (most recent call last)
/tmp/ipykernel_3542705/3693593615.py in
2 # 并除以255使得所有像素的数值均在0到1之间
3 trans = transforms.ToTensor()
----> 4 mnist_train = torchvision.datasets.FashionMNIST(
5 root="…/data", train=True, transform=trans, download=True)
6 mnist_test = torchvision.datasets.FashionMNIST(
~/miniconda3/envs/d2l/lib/python3.8/site-packages/torchvision/datasets/mnist.py in init(self, root, train, transform, target_transform, download)
85
86 if download:
—> 87 self.download()
88
89 if not self._check_exists():
~/miniconda3/envs/d2l/lib/python3.8/site-packages/torchvision/datasets/mnist.py in download(self)
174 try:
175 print(“Downloading {}”.format(url))
–> 176 download_and_extract_archive(
177 url, download_root=self.raw_folder,
178 filename=filename,
~/miniconda3/envs/d2l/lib/python3.8/site-packages/torchvision/datasets/utils.py in download_and_extract_archive(url, download_root, extract_root, filename, md5, remove_finished)
411 filename = os.path.basename(url)
412
–> 413 download_url(url, download_root, filename, md5)
414
415 archive = os.path.join(download_root, filename)
~/miniconda3/envs/d2l/lib/python3.8/site-packages/torchvision/datasets/utils.py in download_url(url, root, filename, md5, max_redirect_hops)
149 # check integrity of downloaded file
150 if not check_integrity(fpath, md5):
–> 151 raise RuntimeError(“File not found or corrupted.”)
152
153
RuntimeError: File not found or corrupted.
The mnist_train[index] is a turple. The turple contains the image data and its label.So you need set 0or1 in the second square bracket to get the image data or its label.
2 Likes
PermissionError: [Errno 13] Permission denied: ‘…/data/FashionMNIST’
因为我的代码是存在服务器上的,当我执行时,就会报错,当我把torchvision.datasets.FashionMNIST的参数root改为服务器上数据集的绝对路径就不会出错,这是为什么呢?感谢回答
UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at …\torch\csrc\utils\tensor_numpy.cpp:180.)
return torch.from_numpy(parsed.astype(m[2], copy=False)).view(*s)
windows+vs code环境下出现的有人能解决吗
我的batchsize都不怎么影响,反正就都很慢…
测试多少batch是比较合适的,画出图像
import matplotlib.pyplot as plt
a = range(100,500)
c=[]
for i in a:
train_iter, test_iter = load_data_fashion_mnist(i, resize=64)
timer=d2l.Timer()
for X,y in train_iter:
continue
b='%.2f' % timer.stop()
print (b)
c.append(b)
print©
plt.plot(a,c)
3.5.1节中,mnist_train[0][0].shape的两个0有怎样的含义?是否代表第一个图像分类的第一张图片呢?
1 Like
mnist_train中包含60000个数据,第一个0表示其中的第一个数据。每个数据由一张图像和一个label构成。所以第二个0表示其中的图像部分。你可以尝试输出mnist_train[0][1],你将会得到一个int,表示该图像对应的label。
6 Likes
ax.imshow(img.asnumpy())会报错
改成 ax.imshow(img.numpy())就可以了,不知道为什么
Dataloader 设置进程数的时候,为什么要额外定义一个函数,而不直接把参数设置为4?
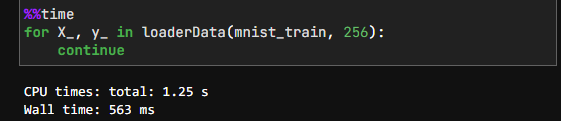
注意到 torchvision.datasets.FashionMNIST 数据集具有 data(图片像素数据), targets(图片类别编号), classes(图片类别名称,列表) 属性。为何不直接操作作为张量的 data, targets,而使用DataLoader呢?这里其读取数据的速度并无显著优势,例如:
def loaderData(mnistData: 'torchvision.datasets.mnist.FashionMNIST',
batch_size: int, shuffle=True) -> tuple['torch.Tensor']:
num_samples = len(mnistData.targets)
indexes = list(range(num_samples))
if shuffle:
random.shuffle(indexes)
for i in range(0, num_samples, batch_size):
slices = indexes[i: min(i+batch_size, num_samples)]
yield mnistData.data[slices], mnistData.targets[slices]
加载数据:
2 Likes