Because b -= c Still operating in original memory.
Distinguish between b = b - c and b -= c.
这是因为,-=,+=等符合运算符,对tensor对象有副作用,会直接改变tensor对象的值,可以通过设计两个函数,来测试一下,一个试用+=运算符,一个没有使用,看看函数内外操作后,对象的id有没有变,顺便输出值验证一下:
import torch
def change_value(data):
data += 2
print(f"change_value:id(data):{id(data)}, data:{data}")
def not_change_value(data):
data = data + 2
print(f"not_change_value, id(data):{id(data)},data:{data}")
return data
x = torch.tensor([1,2])
print(f"original, id(x):{id(x)},x:{x}")
change_value(x)
y = not_change_value(x)
print(f"after not_change_value, id(x):{id(x)},id(y):{id(y)}")
结果如下:
original, id(x):2575192710096,x:tensor([1, 2])
change_value:id(data):2575192710096, data:tensor([3, 4])
not_change_value, id(data):2575227454544,data:tensor([5, 6])
after not_change_value, id(x):2575192710096,id(y):2575227454544
可以看到,change_value函数使用了+=操作符直接在原对象上面进行操作,not_change_value使用了普通的赋值符号,实际上会创建一个新的局部变量data,然后更新这个data的值,最后再返回,可以看到,返回前后data和y的id也是对得上的。
可以参考:pytorch中自加(+=)与普通加的区别,及原位操作_pytorch +=-CSDN博客
首先我们需要了解 python 中变量的类型:
- 不可变对象:int,string,float,tuple
- 可变对象: list, dictionary
对于不可变对象,改变对象的内容,对象在内存中的地址不会改变;对于不可变对象,改变对象内容,对象在内存中的地址会改变,但是注意不可变对象的一些 in-place 操作是不会改变地址的,比如说 i+=1 这种。
其次,python 中函数传递参数的机制有两类:
- 值传递:适用于实际参数类型 为 不可变类型;
- 引用(地址)传递:适用于实际参数类型 为 可变类型;
值传递和引用传递的区别是,函数进行传参后,若形参的值发生改变,不会影响实际参数的值;而传址,改变形参的值,实际的值也会改变。
在这里 params 是作为一个 list,属于可变对象,那么就是传址(引用传递)。在 for 循环中:
param -= lr * param.grad / batch_size
这句话对 w or b 对应的参数进行了更新迭代。所以我们实际的 [w, b] 的值也会改变。
其实这里有两层,第一层是函数传参 [w, b],通过前面的分析我们知道,参数是传引用;第二层是 for 循环中的操作,for 循环中的 p 参数也是一个引用。
一般一个工程项目中不都会有一些工具函数(包)吗,就是为了工程上的统一和更好的模块性。
不然,可能出现重复引用和多人开发各用各的的问题。
besides,假如我们以后不用这个库了,那是不是只用改定义处的接口就好了,不用再改每一次使用的接口呀
根本原因是为了节省内存。
因为对于设置 require_grad 为 True,在反向传播时,会进行自动求导。如果一个创建的 tensor 的该属性设置为 True,则所有依赖于它的节点的 requires_grad 都为True。实际上,对于 param 和 train_l (都是依赖于w or b的),是不需要这个自动求导的能力的。
因此,使用 with torch.no_grad,在该模块下,所有计算出的tensor的requires_grad都自动设置为 False。
在3.2.1下方的代码中,有一段:
y = torch.matmul(X, w) + b
这里要注意一下,X是二维张量,w是一维张量(向量),两者相乘时w会做广播变成二维张量,即由[2, -3.4]广播为[[2, -3.4],[2, -3.4]],再进行乘法运算,计算结果最后再降为一维张量。
在3.2.1中,y.reshape((-1, 1))的使用会升维:
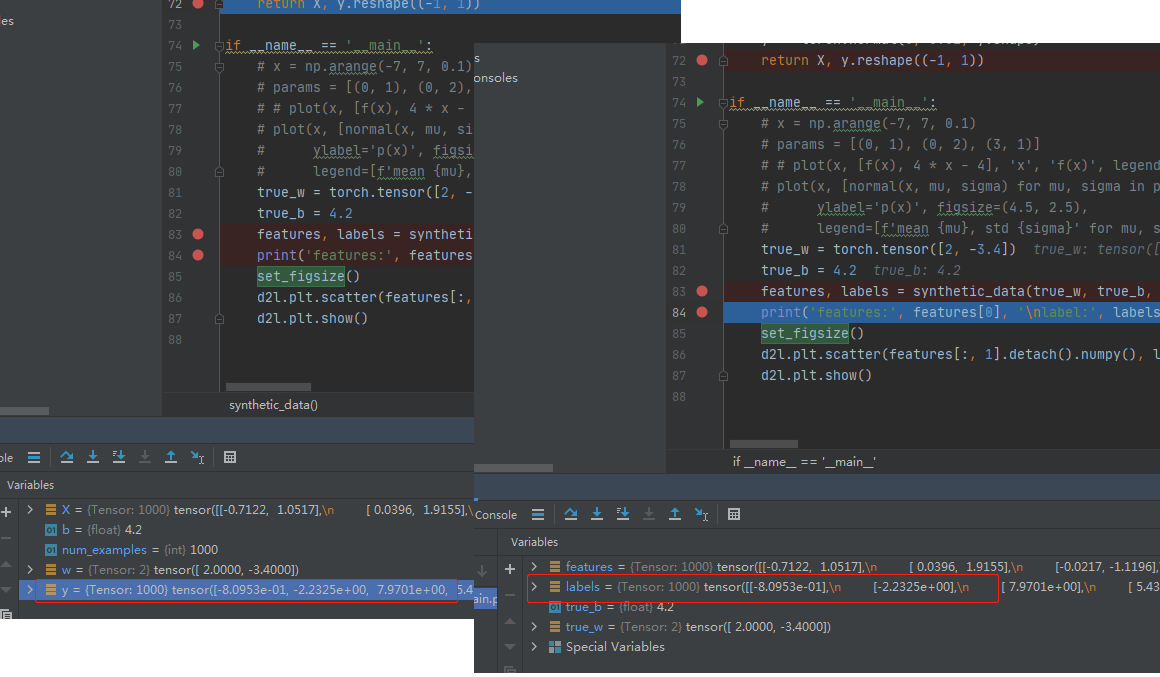
reshape前y是一维张量,ndim是1。此刻一维张量里有一千个元素。
reshape后传给了labels,注意看此时多了中括号,已经变成二维张量了,ndim是2,变成了1000个一维张量,每个一维张量里只有一个元素。
l.sum().backward()为什么我的这句会出错,代码根书上的一样的,但是报错说某个带有梯度信息的变量在被执行了一次后,这些梯度信息就被计算图释放掉了。但是损失l是定义在for循环内了,每次循环不是因该重新计算梯度了吗,如果加上retain_graph=True的话每次迭代用的都是一样的梯度,就没意义了啊。一直搞不明白,求大佬指教 ![]()
![]()
在“l.sum().backward()”的时候,请问在哪里定义了是对w和b来求导的?因为“l”本身是关于X, y, w, b的函数,做backward的时候怎么决定是相对谁求导的呢?
1 Like
哦知道了,是requires_grad的时候定义了
1 Like
这里应该是数据类型定义有问题,我一开始也会报错,定义成这样之后就没有错了w=torch.tensor([[0.],
[0.]],requires_grad=True)
弄了半天也没明白为什么不行
参数的梯度除以批量大小是什么意思?感觉求出了梯度,直接赋予即可
回看计算梯度的公式,代码这里 l.sum().backward() 为什么不是 l.backward().sum() 呢?有大佬懂吗
因为不除的话,梯度会随着批次大小而变化。。。。。。。。。。。。。
我感觉是要求个平均梯度,全部梯度求和可能跨度太大了
好像是backward函数是对标量处理的,而且最后的总损失是一个值,所以要求和变成标量
这样修改代码后和原来的代码是等价的吧:这里直接把损失求均值了 l.mean().backward() , sgd函数中不再需要除batch_size了 param -= lr * param.grad
param.grad.zero_()
sgd 里最后的这个 zero 后面加了一个_ 代表原位操作
为了方便进行原位操作,pytorch中的函数可以在调用之后加下划线 ,强调这是进行原位操作(在模型训练中经常用到的w.grad.zero() 即为原位更新,注意 _ 是放在()之前的),简单得用上述例子进行实现,
参考:
看了所有的回答,也查阅了一些资料,有了一些自己的理解,回答一下刚好梳理一下思路,欢迎批评指正!
我认为回答这个问题要清楚两点:1. 可变对象与不可变对象的区别;2. 对tensor使用复合运算符与否的区别。
首先,在函数内部改变可变对象(列表、字典等)和不可变对象(int float tuple等),该对象在函数外面的值会不会发生改变?对于可变对象,答案是yes,对于不可变对象,答案是no。
那么,为什么会出现不同呢?这个博文Why Functions Modify Lists and Dictionaries in Python讲得非常清楚,简单来说就是:当你改变可变对象,因为他是可变对象,改动可直接发生在原对象身上,即直接改变原地址中的值,;当你改变不可变对象,由于对象本身是不可变的,程序会分配一个新地址给你改动后的值,原地址中的值不受影响,因此函数外该对象的值不变。
以下面两个程序为例。
当x是不可变对象时,比如int:
def add_one(x):
x += 1
return x
x = 1
add_one(x), x
输出结果为(2, 1):
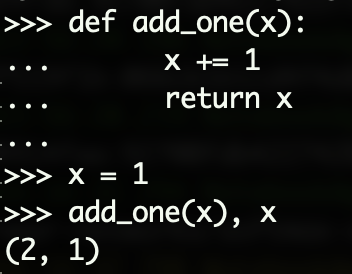
因为在函数内部改变的对象是int类型,是不可变对象,因此程序会分配一个新地址给改动后的值2,函数外的x仍指向原地址,存储的1不受影响。
当x是可变对象时,比如list:
def add_one(x):
for i in range(len(x)):
x[i] = x[i] + 1
return x
x = [1, 2]
add_one(x), x
输出结果中原x也被改变了
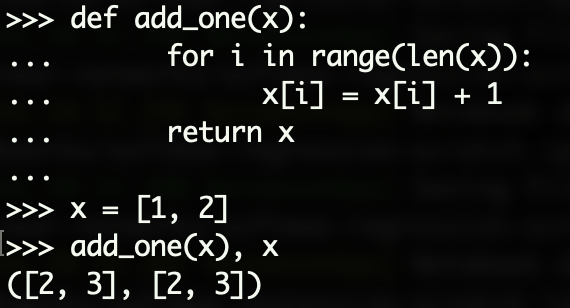
因为x是可变对象,改变x[i]相当于直接对原地址中的列表做改动,因此函数外列表值被改变了。
值得注意的是,以上所说的这种“联动改变”的特性的存在与否只和被改变的对象是否是可变对象有关,和你是否使用了复合运算符无关。也就是说,在上面两个程序中,你将 x += 1 改写成 x = x + 1 或将 x[i] = x[i] + 1 改写成 x[i] += 1,结果都是一样的。
在理解了可变对象与不可变对象后,对于程序中 for param in params 的表述就有更清楚的认识了。由于param是tensor,也是可变对象,因此对param的改变会影响到函数外面params的值。
但是,如果你使用 param = param - lr * param.grad / batch_size 那又不对了。
这就来到了第二点,对于tensor而言,是否使用复合运算符是有影响的。具体来说,使用复合运算符是in-place的改动,效果上等同于对可变对象改动;而不使用的话就会重开一个新地址,改动便不会同步到函数外面的params上,效果上等同于对不可变对象的改动(当然,不使用自增运算符但使用slice op结果也是in-place的改动 param[:] = param - lr * param.grad / batch_size,前面章节有介绍)。
实例对比程序如下所示:
使用自增运算符:

不使用自增运算符和切片时:

请问在“读取数据集”这块中,'for X, y in data_iter(batch_size, features, labels):'该步骤调用的【data_iter】函数,并无X,y的处理过程,X,y是如何被这个循环处理的?