Li_Ben
88
这里指的是对loss求导,代码案例里面一个批量是10,举个例子来说就是
正向的流程如下
y_hat1 = 0.69w1 + -0.8199w2 +b
y_hat2 = 0.6915w1 + -0.8199w2 +b
y_hat3 = -0.5563w1 + -1.1023w2 +b
y_hat4 = -0.2626w1 + -0.0103w2 +b
y_hat5 = 0.1197w1 + 0.1623w2 +b
y_hat6 = 0.2416w1 + -0.2669w2 +b
y_hat7 = -0.8563w1 + -1.3992w2 +b
y_hat8 = -0.9281w1 + 0.6239w2 +b
y_hat9 = -1.9992w1 + 1.2106w2 +b
y_hat10 = 0.1552w1 + -0.3504w2 +b
然后是求Loss操作(y_hat - y)**2 / 2,这里(y_hat , y)的shape都是(10*1),y是数据给到的正确结果标签
L1=(y_hat1 - y1)**2 / 2
L2=(y_hat2 - y2)**2 / 2
L3=(y_hat3 - y3)**2 / 2
L4=(y_hat4 - y4)**2 / 2
L5=(y_hat5 - y5)**2 / 2
L6=(y_hat6 - y6)**2 / 2
L7=(y_hat7 - y7)**2 / 2
L8=(y_hat8 - y8)**2 / 2
L9=(y_hat9 - y9)**2 / 2
L10=(y_hat 10- y10)**2 / 2
上面的L1、L2的shape都是(10,1)(方便不和1混淆所以用大写的L了),最后一步把Loss求和
L = L1 + L2 + L3 + L4 + L5 + L6 + L7 + L8 + L9 + L10
得到一个(10,1)张量L
tensor([[5.8227e-03],
[3.3351e-02],
[4.5864e-03],
[4.5823e-04],
[1.5342e-02],
[3.0193e-02],
[1.5205e-02],
[7.6718e-04],
[1.6346e-03],
[8.4936e-03],
[1.7764e-04],
[7.4685e-03],
[3.1043e-03],
[1.9390e-02],
[6.6388e-03],
[1.9403e-03],
[1.9872e-03],
[1.8337e-05],
[5.1448e-04],
[3.9950e-03]], grad_fn=)
这里如果对L[0]对w1的导数那就是【反向操作】
先是L的加法反向传递, L1 + L2 + L3 + L4 + L5 + L6 + L7 + L8 + L9 + L10走一层次,
再Loss的反向传递,然后到y_hat1的W1
继续一次是L的加法反向传递, L1 + L2 + L3 + L4 + L5 + L6 + L7 + L8 + L9 + L10走一层次,
再Loss的反向传递,然后到y_hat2的W1
。。。
一直到
最后一次是L的加法反向传递, L1 + L2 + L3 + L4 + L5 + L6 + L7 + L8 + L9 + L10走一层次,
再Loss的反向传递,然后到y_hat10的W1
共10次,正好积累了batch次数的“梯度”,所以要除以batch_size
L[1],L[2] … L[9] 也都是一样的过程。所以再代码里面/batch_size 就去除了累计的梯度,平均了这个“梯度”
1 Like
JJC
89
请问一下这里最后的y为什么要reshape成一个列向量
而且(-1,1)为什么是-1
一样的一样的,只不过是作者把很多包都包到了d2l里罢了,到时候真正用的时候直接把d2l.去掉就好了呗
用-1是python的模糊控制,就根据列自动推断多少行
JJC
92
意思是reshape(-1,1)会自匹配X,y的行数?然后reshape成一个向量?
跟X没关系吧,举个例子,如果y原来是(3 * 4)的矩阵,然后reshape(-1,1)之后(12 * 1)的矩阵了,一共有3 * 4 = 12个元素,然后reshape规定列为1,就自动推断为12行。但是这里我觉得好像不用reshape吧,因为X是一个1000 * 2的矩阵,w是一个2 * 1的向量,乘完之后y应该就是一个向量,不知道为啥还要reshape
1 Like
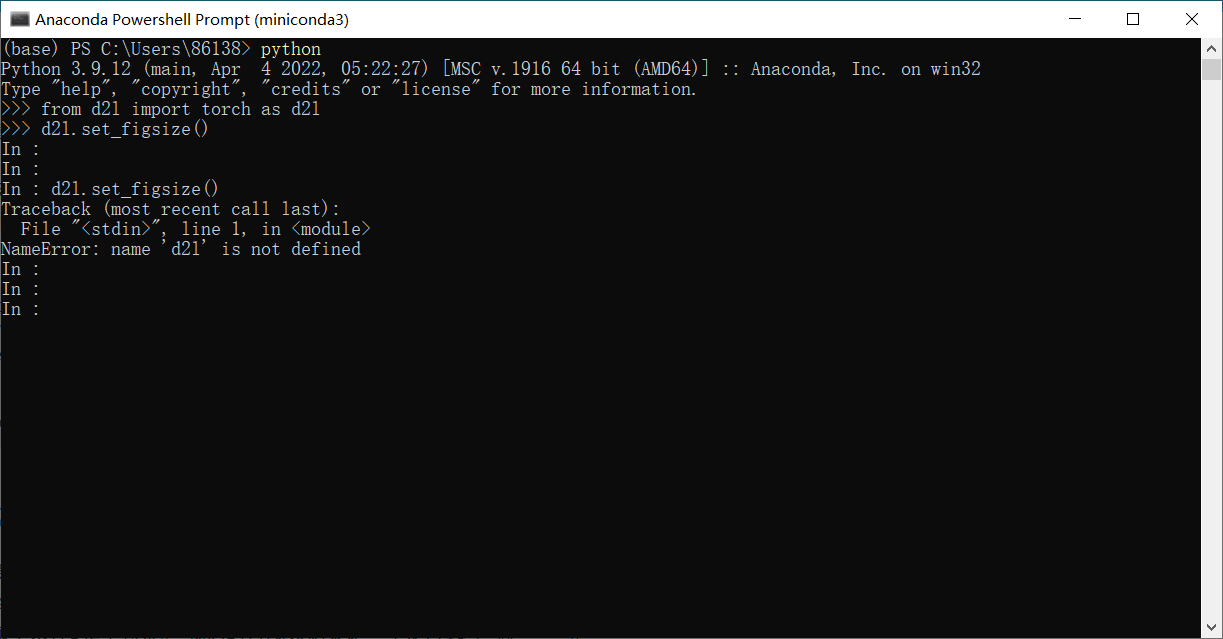
我在miniconda里运行d2l.set_figsize()后,每一行前面的>>>就变成了in,原来的输入还都消失了,请问这是为什么?
这个函数可以删掉,但是有问题的函数不止这一个。
param -= lr * param.grad / batch_size 这里更新b的时候,b是一个标量,b.grad应该是一直等于0的,所以lr * param.grad / batch_size也是等于0,那为什么b会变化呢
Buck
96
pytorch只允许标量对张量求导,张量对张量求导是不存在的,标量对张量求导,那么张量的size和梯度的size肯定一样的呀
不是对tensor带require_grad不能进行inplace,是leaf variables带require_grad 不能进行inplace.
1 Like
1.对于logistic回归,权重全部初始化为0是可以的,但对于多层神经网络,不可以将权重全部初始化为0
#w = torch.normal(0,0.01,size=(2,1),requires_grad=True)
w = torch.zeros(size=(2,1),requires_grad=True)
b = torch.zeros(1,requires_grad=True)
w 偏离:tensor([-1.6928e-05, -1.0133e-04], grad_fn=)
b 偏离:tensor([0.0004], grad_fn=)
5.使用reshape是为了提高代码的适用性,对于本节代码用不用reshape都可以,但对于不清楚需要预测结果的维度是1*n还是n*1时,用reshape转换后就可以计算了
6.学习率越大,损失函数下降越快
学习率为0.001:
epoch:1,loss:14.116592
epoch:2,loss:11.440865
epoch:3,loss:9.272802
epoch:4,loss:7.515996
epoch:5,loss:6.092335
epoch:6,loss:4.938600
epoch:7,loss:4.003555
epoch:8,loss:3.245719
epoch:9,loss:2.631483
epoch:10,loss:2.133610
学习率为0.01:
epoch:1,loss:2.248535
epoch:2,loss:0.308883
epoch:3,loss:0.042466
epoch:4,loss:0.005883
epoch:5,loss:0.000854
epoch:6,loss:0.000161
epoch:7,loss:0.000066
epoch:8,loss:0.000053
epoch:9,loss:0.000051
epoch:10,loss:0.000051
学习率为0.1:
epoch:1,loss:0.000049
epoch:2,loss:0.000047
epoch:3,loss:0.000049
epoch:4,loss:0.000047
epoch:5,loss:0.000047
epoch:6,loss:0.000048
epoch:7,loss:0.000047
epoch:8,loss:0.000047
epoch:9,loss:0.000047
epoch:10,loss:0.000047
1 Like
这个位置我觉得或许可以这么理解,按照上面batch_size的意思,每次都是按照顺序取一部分数据,然后用这部分数据更新梯度和损失,在batch_size中再进行平均。而每一部分的batch_size的数据都是按照顺序取得这是非常重要的,这就代表着每一部分小的数据都呈现着和总体数据几乎相同的趋势,不准确的说可以认为是整体数据的无偏估计,也就是几乎都可以单独的作为训练的数据集。那么意味着每次epoch更新参数的时候,内部实际根据batch_size的整数倍次数对参数进行了更新。而如果进行总体加和,对参数更新就变成了实际的epoch数目,弱化了batch_size的作用。这也表明,如果batch_size是随机采样的数据而不是依次采样的数据,那么模型的loss很可能波动较大,甚至是不收敛。
这个位置我觉得或许可以这么理解,按照上面batch_size的意思,每次都是按照顺序取一部分数据,然后用这部分数据更新梯度和损失,在batch_size中再进行平均。而每一部分的batch_size的数据都是按照顺序取得这是非常重要的,这就代表着每一部分小的数据都呈现着和总体数据几乎相同的趋势,不准确的说可以认为是整体数据的无偏估计,也就是几乎都可以单独的作为训练的数据集。那么意味着每次epoch更新参数的时候,内部实际根据batch_size的整数倍次数对参数进行了更新。而如果进行总体加和,对参数更新就变成了实际的epoch数目,弱化了batch_size的作用。这也表明,如果batch_size是随机采样的数据而不是依次采样的数据,那么模型的loss很可能波动较大,甚至是不收敛。
sorry,这里我又看了一下,内部batch_size数据集是做过shuffle处理的,但是其他部分应该是这样的
Aikoin
105
!pip install matplotlib==3.0.0
运行这一步之后既可正常画图
主要是之前用了tensor.matmul 函数,这个矩阵乘法函数如果调换一下相乘的次序,会从行向量变成列向量。为了不去追踪这个矩阵乘法的次序,用reshape就确保万无一失了。不过我个人觉得用reshape是会掩盖细致的计算bug的。还是尽量严谨些。这样至少在代码量上去之后保证计算bug不会出现。否则出了计算的bug也找不到在哪。
yufu5
108
了解下python变量类型中的不可变类型和可变类型
zzzz
109
改了之后我后面 l.sum().backward() 这里还是会报错