param是一个列表,里面是要优化的参数
关于sgd为啥没有return,因为是引用传递,直接会在原数上修改
真实的权重,目的是生成本章练习用的数据,最后和计算出来的权重(w)进行对比,即,如果数据是线性相关的,线性回归算法可以得到接近真实的线性关系。 ![]()
你没有算噪声,e。y=wX+b+e , e是:torch.normal(0, 0.01, y.shape) ![]()
from d2l import torch as d2l,这个地方的torch是指什么?

把2个特征形状通过线性回归后绘制出来2个图表(不太熟悉怎么绘制3D图 这样的话 整个线性分割会是一个面)
#绘制图表
d2l.plt.figure(figsize=(14,10))
#特征1的图
d2l.plt.subplot(2,2,1)
features0 = features[:, 0].detach().numpy()
labels1 = labels.detach().numpy()
d2l.plt.scatter(features0, labels1, 1);
#将第一个特征和权重的第一个组合成线性函数
rlt0 = features[:, 0]*w[0] + b
rlt0z = rlt0.reshape(features[:, 0].shape)
d2l.plt.plot(features0, rlt0z.detach().numpy());
#特征2的图
d2l.plt.subplot(2,2,2)
features1 = features[:, 1].detach().numpy()
d2l.plt.scatter(features1, labels1, 1);
#将第二个特征和权重的第二个组合成线性函数
rlt1 = features[:, 1]*w[1] + b
rlt1z = rlt1.reshape(features[:, 1].shape)
d2l.plt.plot(features1, rlt1z.detach().numpy());
with torch.no_grad() 之后为什么还要清零grad?
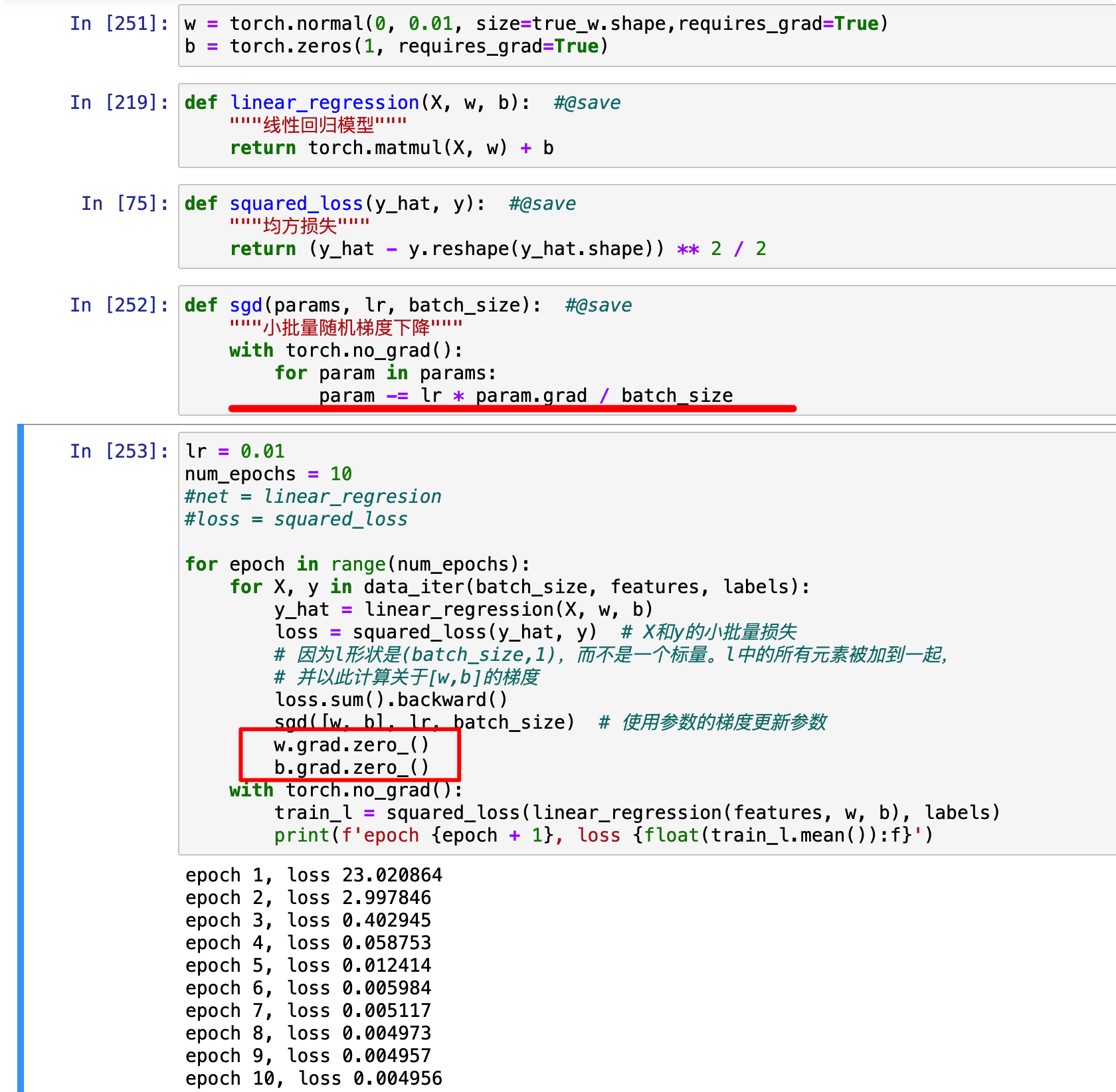
哦哦明白了,谢谢你啦,看来我是把清零和暂停搞混了哈哈
我也遇到这个问题了,大佬后面解决了吗?
RuntimeError: Trying to backward through the graph a second time (or directly access saved tensors after they have already been freed). Saved intermediate values of the graph are freed when you call .backward() or autograd.grad(). Specify retain_graph=True if you need to backward through the graph a second time or if you need to access saved tensors after calling backward.
我有一个问题sgd函数中为什么要with torch.no_grad()呢
这里应该没有进行广播,运行help(torch.matmul)可以看到当左边是矩阵,右边是向量时,matmul函数会直接返回mv函数的值。广播应该说的是后面的标量b?
這是一個人造的綫性回歸模型.
true_w = [2, -3.4] 就是說設定的模型權重為[2, -3.4],沒有特殊意義
最後可以用來檢測生成的權重與true_w的接近程度
我不理解的是为什么要“二次定义”,而不是直接调用linreg 和 squared_loss?
他意思是说区分1行n列和n行1列,比如
a = torch.tensor([[1,2]])
a, a.T
不用len()肯定是如你说的加快运算。但本身就没必要每批次都len一下,顶多for少循环一批,最后一批单独处理。
但这也没什么必要,原因是学习率lr本来就是人工调参,每执行100次(大规模数据中就更大)梯度下降,只有最后一次lr变小显然不影响整个搜索(训练)过程(很多算法中lr本来就是逐渐减小的)。
请问一下代码中的yield关键字和return有什么区别?
这个在python基础语法里有讲,我建议你自己找一个视频教程去看一遍印象会更深刻
只是为了只打印一次,否则打印太多了影响下面内容的阅读。