lr = 0.03
for epoch in range(num_epochs):
ImportError Traceback (most recent call last)call (self, obj)
12 frames
ImportError: cannot import name ‘_check_savefig_extra_args’ from ‘matplotlib.backend_bases’ (/usr/local/lib/python3.7/dist-packages/matplotlib/backend_bases.py)
1 Like
因为他已经训练到一个符合要求的水准了,除非你重置一下w和b#初始化参数权重w ,偏置b=0
Byran
May 31, 2022, 8:20am
69
我觉得就是重命名一个接口把,net指代一切算法,这样你训练的代码就不用调整了,只要把net指向对应的算法即可
因为python的机制不用于C的函数传参,python传进去的是参数本身也可以说是C++中参数的引用,因此在函数中对参数进行操作会影响函数域外的变量
class Tes(object):
def __init__(self):
self.num = 10
pass
pass
def func(inc: Tes) -> Tes:
inc.num += 10
print(id(inc))
return inc
def func2(inc):
inc += 10
print(id(inc))
return inc
a1 = Tes()
print(id(a1))
a2 = func(a1)
print(id(a2) == id(a1)) #此输出为True 对于非python基础类型的成立
b1 = 9999
print(id(b1))
b2 = func2(b1)
print(id(b2) == id(b1)) #此输出为False
batch_size为标量 所以除法是没问题的
a = torch.ones((2, 1))
b = torch.ones((1, 2)) * 0.6
c=a-b
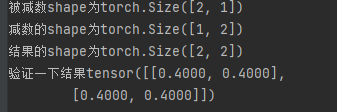
print(f'被减数shape为{a.shape}\n'
f'减数的shape为{b.shape}\n'
f'结果的shape为{c.shape}\n'
参数的梯度值和参数本身,其shape是一致的,那么也就不存在之前的广播,但是这又和沐神3之前PPT上的分子布局不同。先埋个坑 等我回来填
test1=torch.randn((1,2),requires_grad=True)
test2=torch.mm(test1,test1.T)
test2.shape
test2.backward()
test1.grad.shape == test1.shape
data_iter的最后一次取的样本个数可能小于batch size,那这样的话在sgd的时候还是除以batch size是不是不合适?感觉还是在计算loss的时候直接给出均值好一点
我也想知道,如果不导入dl2,会影响学习吗?或者代码实现吗?
pkupzl
August 4, 2022, 5:31am
78
因为优化算法中用了‘-=’,pytorch规定tensor带require_grad 不能进行“+=”或者“-=”(in-place操作),如果不进行in-place操作而是写成param =param-lr * param.grad / batch_size会导致param地址变动,后面对导数清零的时候就会报错,因为此时w.grad已经是’Nonetype’了with torch.no_grad():封装可以暂时关闭计算图,也就是在语句内进行的张量运算不改变已有的计算图,这样就可以进行in-place操作了
1 Like
有大佬能解释一下这里来wx+b的元素中第一个数-0.3525x2+3.4x0.6474+4.2应该是5.69616,但为什么结果是5.6990,同理第二个数应该是0.24564,但结果是0.2538,同理后面的结果都不对,为什么精度这么差,会对后面模型造成影响吗
我当时情况是x1>x2就交换两元素值。也可以理解,如果两个元素交换值之后,梯度确实依然可以计算,但这个梯度相对的就不再是原来的值了,所以会报错
param 有维度的情况下
比如:
a = lst # 传递引用
经过我的测试保持一致 的 我还测试了向量对矩阵进行求导,最后变量的梯度仍保持原来的shape,那么我们就可以认识 变量的梯度是与其同shape的一个成员。
在绘制features和labels的散点图时,为什么要使用labels.detach().numpy()呢?将detach().numpy()去掉也不会报错呀?比如这样:d2l.plt.scatter(features[:, (1)], labels, 1);
ZL_CHEN
September 15, 2022, 8:23am
84
避免重复造轮子,每次用都去导包定义,更方便统一些吧
ZL_CHEN
September 15, 2022, 8:28am
85
这个前面课程好像也提到过,改成 x[:] = x - k 应该就可以了
1 Like
tonyma
October 30, 2022, 11:20pm
86
关于你说的shape是否一样的问题,这里在机器学习中尤其是编程实现和数学上矩阵论的定义是不相同的,从矩阵的定义上来说,shape一定是不一样的
tonyma
October 30, 2022, 11:28pm
87
我也有相同的疑问,我就是用的批量和的梯度,但是最后的训练效果比沐神差不少,具体原因未知,