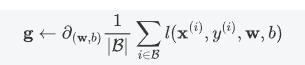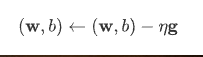不太明白,题目中是附加噪声满足指数分布,第一个式子|y|应该写成|$\ibson$|=|y-wx-b|吧
请问 Import torch 和from d2l import torch as d2l有什么区别和关系吗?

Thanks a lot, it really helps!
第一小问不是1/2是log2吧?是不是忘了加log了
请问习题3.3
提出一种随机梯度下降算法来解决这个问题。哪里可能出错?(提示:当我们不断更新参数时,在驻点附近会发生什么情况)请尝试解决这个问题。
有同学知道怎么解嘛?
1.1 将所求最小化函数对b求导使导函数为0得到b即为最优值b的解析解(最大似然法)
1.2 这个问题与正态分布的关系是:对于一个具有均值为μ和方差为σ^2的正态分布,它的最大似然估计就是其均值μ。在这个问题中,我们需要最小化平方差的和,也就是最大似然估计的负数。因此,我们也可以将这个问题视为对一个假设的正态分布的参数(均值)进行最大似然估计的问题,并得到其解析解为数据的平均值。
2.4 当数据集非常小的时候比使用随机梯度下降更好,因为每个epoch的梯度更新时,数据的随机性会导致噪声变大。此外,当我们的数据集中存在非常大的异常值或者噪声点时,随机梯度下降可能会受到影响,导致模型的性能下降,因为它更容易被这些点所影响。
1 Like
请问3.1.12是怎么推到3.1.13的呀?
不用小batch会过拟合,batch size是个超参数,你确实可以选择为1,但不是说你‘应该’选择更小的batch size
你好,我认为你的似然概率和我的不一样,绝对值里应该是拟合值和实际值的差

我认为2.4是这样的,当X⊤X不可逆时无法使用公式直接求解最优参数,不可逆的情况可能是因为样本个数小于样本的特征数。sgd方法更加通用,某些模型可能只要求到局部最优解即可,现实中很少用神经网络求解凸优化问题的全局最优解。
1 Like
也可以用沐神视频中讲的亚导数替代,在不可导点可取两侧导数范围中的随机值
绝对值前面应该是加号吧?
Should it be add before the absolute number ?
1 Like
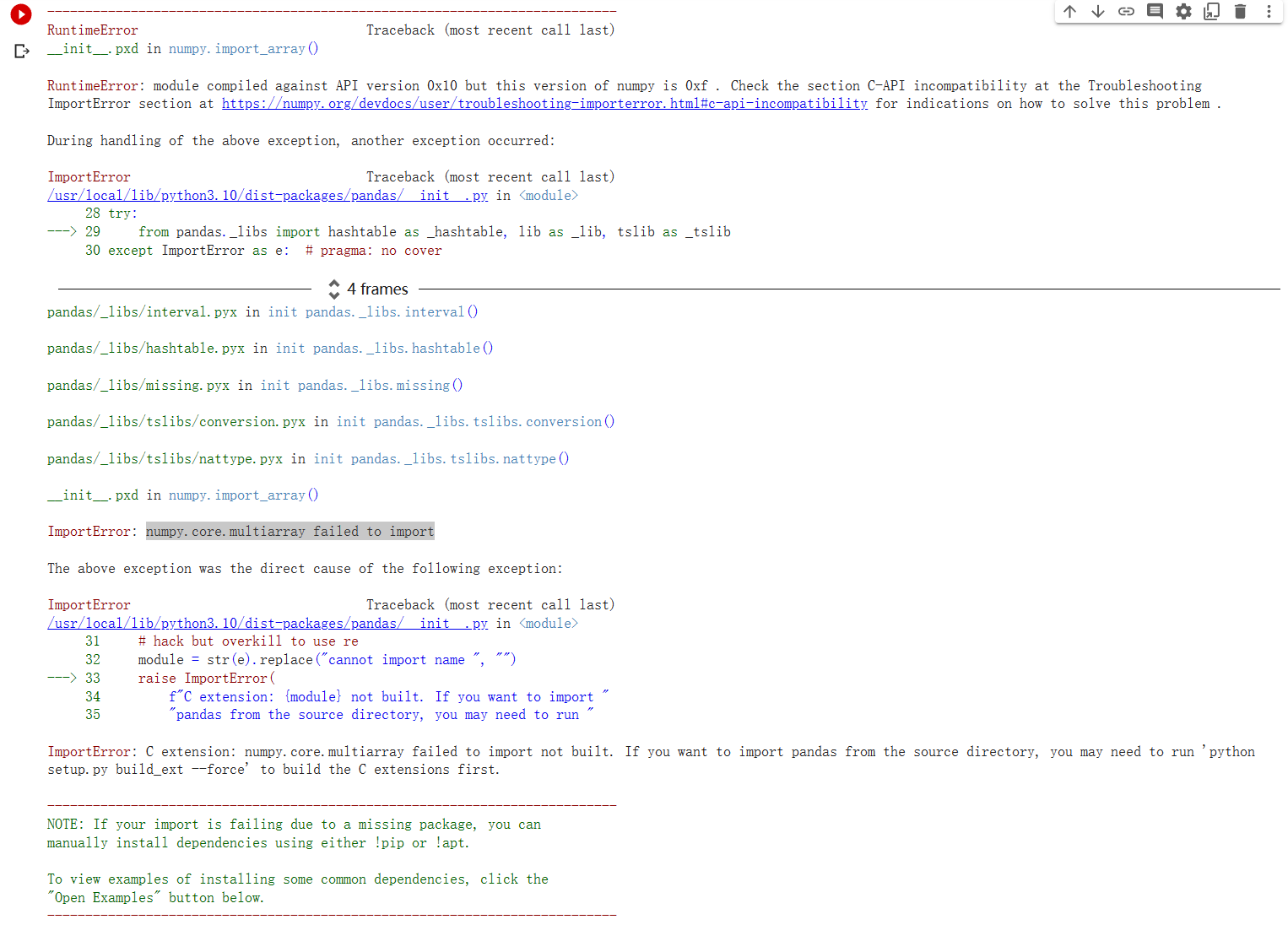
问题已解决
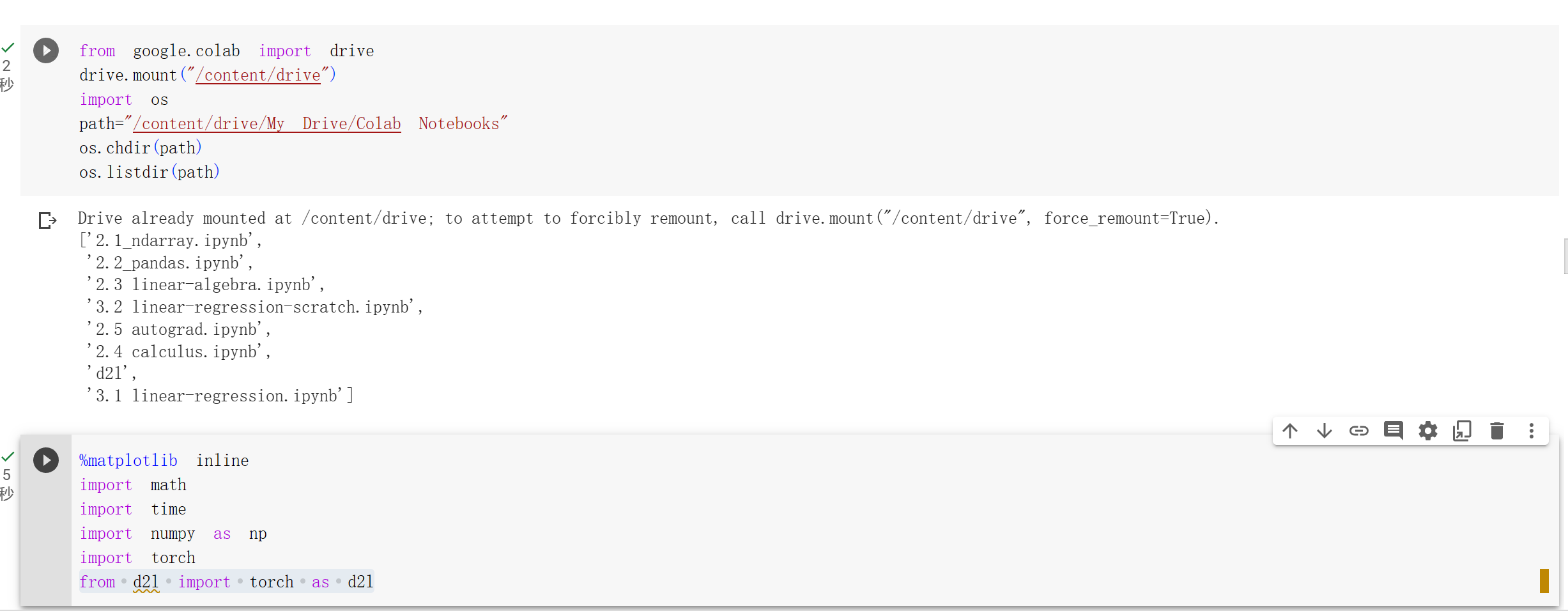
1.将d2l文件夹(包含torch.py)上传到 Google drive, 下载地址。
2.在colab中运行以下代码,调用d2l文件夹中的torch.py。随后运行 from d2l import torch as d2l 将不会报错。
from google.colab import drive
drive.mount("/content/drive")
import os
path="/content/drive/My Drive/Colab Notebooks"
os.chdir(path)
os.listdir(path)
1 Like

用这个也可以解决

这个没什么实际用处,是和书上引用前面章节内容相对应的,觉得不舒服看教材就可以了。