交作业:
代码:
我假设是酒店的数据:有钥匙,房间号,床数,是否有窗,浴室类型
#创建包含更多行的原始数据集
import os
import pandas as pd
import torch
os.makedirs(os.path.join(‘…’,‘深度学习’,‘数据预处理’,‘data’),exist_ok=True)
data_file = os.path.join(‘…’,‘深度学习’,‘数据预处理’,‘data’,‘hotel.csv’)
with open(data_file,‘w’) as f:
f.write(‘key,room,bed,wind,bath\n’)
f.write(‘ELE,NA,1,YES,Shower\n’)
f.write(‘NA,202,2,NA,Shower\n’)
f.write(‘ELE,NA,2,NO,NA\n’)
f.write(‘ELE,204,1,NA,NA\n’)
f.write(‘ELE,205,2,NO,Shower\n’)
f.write(‘NA,206,NA,YES,Bathtub\n’)
f.write(‘ELE,NA,1,YES,NA\n’)
f.write(‘NA,208,NA,NA,Shower\n’)
f.write(‘ELE,NA,1,NO,Bathtub\n’)
f.write(‘NA,210,1,YES,NA\n’)
f.write(‘ELE,211,1,NO,Shower\n’)
f.write(‘NA,212,2,YES,NA\n’)
f.write(‘ELE,213,1,NA,Shower\n’)
f.write(‘ELE,NA,1,YES,NA\n’)
f.write(‘ELE,215,2,YES,Shower\n’)
f.write(‘NA,216,1,NA,Bathtub\n’)
f.write(‘NA,217,1,YES,NA\n’)
f.write(‘ELE,NA,NA,NO,Shower\n’)
f.write(‘NA,219,NA,YES,Bathtub\n’)
f.write(‘NA,220,1,YES,NA\n’)
data = pd.read_csv(data_file)
print(data)
#删除缺失值最多的列
to_drop = data.isna().sum().idxmax()
data = data.drop(columns=to_drop)
#print(data)
x, y, z = data.iloc[:, 0:2], data.iloc[:, 2], data.iloc[:, -1]
y = pd.get_dummies(y, dummy_na=True)
z = pd.get_dummies(z, dummy_na= True)
#print(x, y, z)
print(x)
print(y)
print(z)
#将预处理后的数据集转换为张量格式
a, b, c = torch.tensor(x.to_numpy(dtype = float)), torch.tensor(y.to_numpy(dtype = float)), torch.tensor(z.to_numpy(float))
#print(a, b, c)
print(a)
print(b)
print(c)
terminal得到:
tensor([[ nan, 1.],
[202., 2.],
[ nan, 2.],
[204., 1.],
[205., 2.],
[206., nan],
[ nan, 1.],
[208., nan],
[ nan, 1.],
[210., 1.],
[211., 1.],
[212., 2.],
[213., 1.],
[ nan, 1.],
[215., 2.],
[216., 1.],
[217., 1.],
[ nan, nan],
[219., nan],
[220., 1.]], dtype=torch.float64)
tensor([[0., 1., 0.],
[0., 0., 1.],
[1., 0., 0.],
[0., 0., 1.],
[1., 0., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 0., 1.],
[1., 0., 0.],
[0., 1., 0.],
[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.],
[0., 1., 0.],
[0., 1., 0.],
[0., 0., 1.],
[0., 1., 0.],
[1., 0., 0.],
[0., 1., 0.],
[0., 1., 0.]], dtype=torch.float64)
tensor([[0., 1., 0.],
[0., 1., 0.],
[0., 0., 1.],
[0., 0., 1.],
[0., 1., 0.],
[1., 0., 0.],
[0., 0., 1.],
[0., 1., 0.],
[1., 0., 0.],
[0., 0., 1.],
[0., 1., 0.],
[0., 0., 1.],
[0., 1., 0.],
[0., 0., 1.],
[0., 1., 0.],
[1., 0., 0.],
[0., 0., 1.],
[0., 1., 0.],
[1., 0., 0.],
[0., 0., 1.]], dtype=torch.float64)
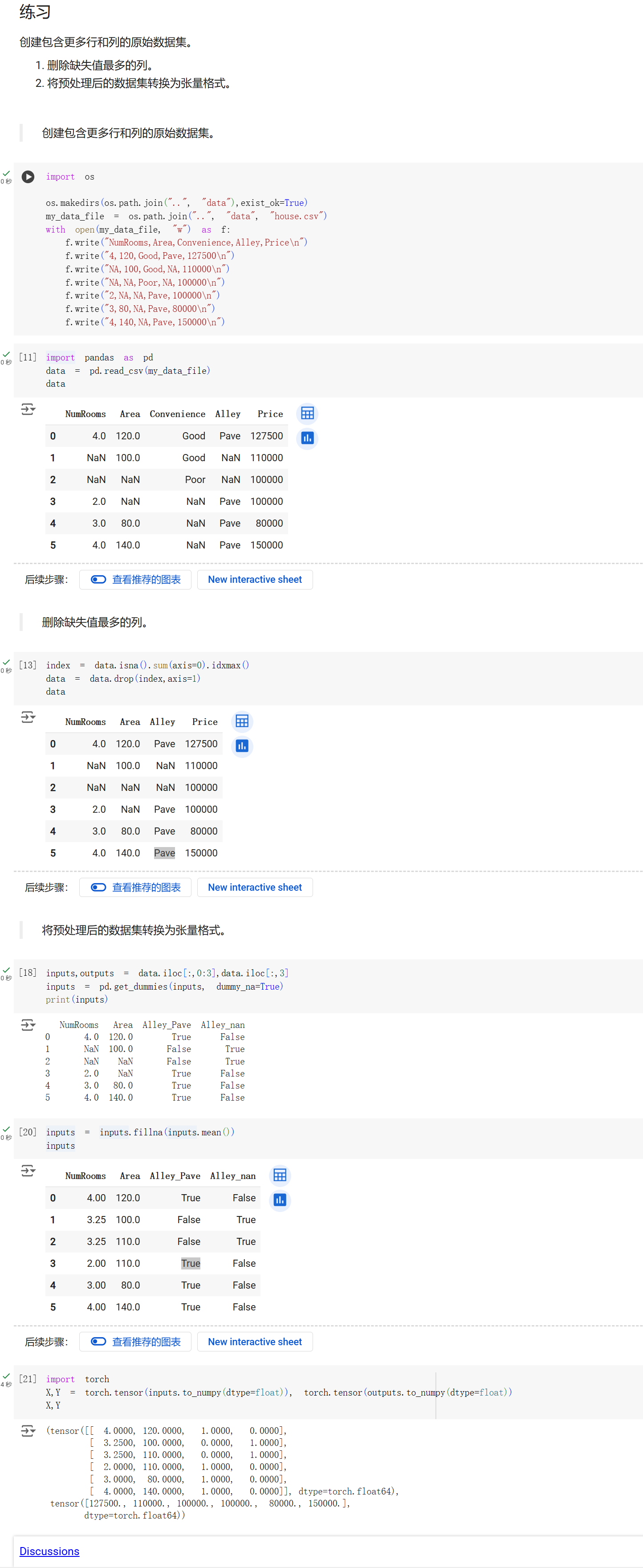
- 删除缺失值最多的列。
#删除缺失值最多的列
to_drop = data.isna().sum().idxmax()
新建变量to_drop为data里面有NAN且求和sum后为最大值的列(因为isna().sum()默认为列)的id
data = data.drop(columns=to_drop)
新的data为drop to_drop后的矩阵
- 将预处理后的数据集转换为张量格式。
a = torch.tensor(data.to_numpy(dtype = float))
print(a)
若直接对初步处理后的data直接用torch.tensor(data.to_numpy(dtype = float))转换成浮点数,会发现报错,提示ValueError: could not convert string to float: ‘YES’。所以我想:把data含yes的部分通过
x, y, z = data.iloc[:, 0:2], data.iloc[:, 2], data.iloc[:, -1]
对data切割后用
y = pd.get_dummies(y, dummy_na=True)
z = pd.get_dummies(z, dummy_na= True)
进行布尔型的转换
最后成功转换成tensor的float:
a, b, c = torch.tensor(x.to_numpy(dtype = float)), torch.tensor(y.to_numpy(dtype = float)), torch.tensor(z.to_numpy(float))
但有可以改进之处:对于x本来属于浮点类型的列,我并未再进一步处理,对于房间号,可以按照顺序补全。对于床数,应该删除含有NAN的行。
——初学者rookie