inputs=inputs.fillna(inputs.mean(numeric_only=True))
print(inputs)
这样就能解决
2 Likes
小白来交作业
def drop_NaN_most(data):
count = 0
count_max = 0
labels = data.columns
for label in labels:
count = data[label].isna().sum()
if count > count_max:
count_max = count
flag = label
return data.drop(flag, axis=1)
new_data = drop_NaN_most(data)
inputs, outputs = new_data.iloc[:, 0], new_data.iloc[:, 1]
inputs = inputs.fillna(inputs.mean(numeric_only=True))
import torch
X, y = torch.tensor(inputs.values), torch.tensor(outputs.values)
print(X, y)
Submit my work
import os
import pandas as pd
import torch
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
file_path = os.path.join('..', 'data', 'score.csv')
with open(file_path, 'w') as f:
f.write('name,pol,eng,math,408\n')
f.write('mtj,72,54,98,109\n')
f.write('mwj,78,68,100,106\n')
f.write('lbh,NA,NA,NA,NA\n')
f.write('rx,66,NA,NA,NA\n')
data = pd.read_csv(file_path)
print(data)
outputs = data.iloc[:, 1:5]
outputs = outputs.fillna(outputs.mean())
print(outputs)
x = torch.tensor(outputs.values)
print(x)
1 Like
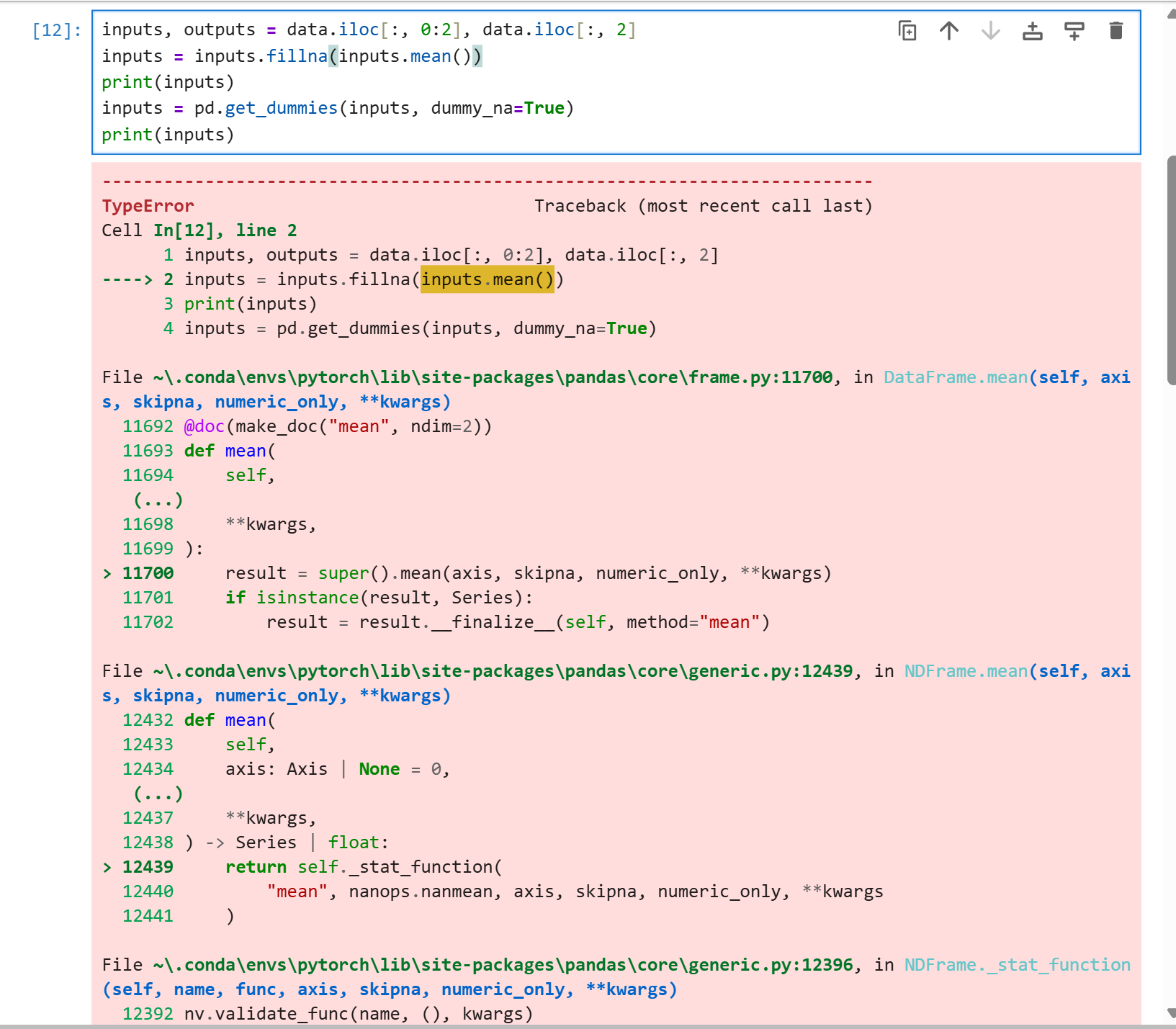
应该是pandas版本更新了,我看讨论说要加inputs.mean(numeric_only=True)才可以
请问作业在哪里看,一直找不到作业,请问是在教材里面吗
pandas 在新版里对非数值列求 mean 不再默认忽略非数值列。
所以这里会报错:
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean())
print(inputs)
2 Likes
我的练习:在原本的数据集上加了两列可能影响房价的数据:高度height,和距离distance,后删除缺失值最大的一列,直接对nan求均值目前的版本会报错,需要分开处理:对数值列填充均值,对分类列进行独热编码,下面的完整代码:
import os
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
# 写入包含四个特征的数据
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Height,Distance,Price\n') # 列名
f.write('NA,Pave,3.5,5,127500\n') # 每行表示一个数据样本
f.write('2,NA,2.6,6,106000\n')
f.write('4,NA,1.5,10,178100\n')
f.write('NA,NA,2.6,NA,140000\n')
import pandas as pd
# 读取数据
data = pd.read_csv(data_file)
print("原始数据:")
print(data)
# 分割输入和输出
inputs, outputs = data.iloc[:, 0:4], data.iloc[:, 4]
#删除缺失值最大的一列
missing_counts = inputs.isnull().sum()
max_missing_col = missing_counts.idxmax()
max_missing_count = missing_counts.max()
if max_missing_count > 0: # 只有当有缺失值时才删除
print(f"删除列: '{max_missing_col}'")
inputs = inputs.drop(columns=[max_missing_col])
else:
print("没有列有缺失值,无需删除")
# 只对数值列填充均值
numeric_cols = inputs.select_dtypes(include=['float64', 'int64']).columns
inputs[numeric_cols] = inputs[numeric_cols].fillna(inputs[numeric_cols].mean())
print("填充缺失值后:")
print(inputs)
# 对分类列进行独热编码
inputs = pd.get_dummies(inputs, dummy_na=True)
print("独热编码后:")
print(inputs)
# 转换为张量
import torch
X = torch.tensor(inputs.to_numpy(dtype=float))
y = torch.tensor(outputs.to_numpy(dtype=float))
print("X 形状:", X.shape)
print("y 形状:", y.shape)
运行代码后的结果:
原始数据:
NumRooms Alley Height Distance Price
0 NaN Pave 3.5 5.0 127500
1 2.0 NaN 2.6 6.0 106000
2 4.0 NaN 1.5 10.0 178100
3 NaN NaN 2.6 NaN 140000
删除列: ‘Alley’
填充缺失值后:
NumRooms Height Distance
0 3.0 3.5 5.0
1 2.0 2.6 6.0
2 4.0 1.5 10.0
3 3.0 2.6 7.0
独热编码后:
NumRooms Height Distance
0 3.0 3.5 5.0
1 2.0 2.6 6.0
2 4.0 1.5 10.0
3 3.0 2.6 7.0
X 形状: torch.Size([4, 3])
y 形状: torch.Size([4])
Hi,我使用的pandas版本为3.0.0,我想分享另一个解决方案!
通过显式设置numeric_only参数也能实现!
imputs ,outputs = data.iloc[:,0:2],data.iloc[:,2]
inputs = inputs.fillna(inputs.mean(numeric_only=True))
print(input)
1 Like
import os
os.makedirs(os.path.join("..","data"), exist_ok=True)
data_file = os.path.join("..", "data", "house_tiny.csv")
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Key,Bathroom,Yard,Balcony,Price\n')
f.write('1,Pave,1,1,NA,1,100000\n')
f.write('NA,NA,NA,NA,NA,1,100000\n')
f.write('2,Pave,1,1,NA,NA,100000\n')
f.write('2,Pave,1,1,NA,1,100000\n')
f.write('3,Pave,1,1,NA,1,100000\n')
f.write('4,Pave,1,1,NA,1,100000\n')
f.write('NA,Pave,1,1,NA,1,100000\n')
f.write('6,Pave,1,1,NA,3,100000\n')
f.write('NA,Pave,1,1,NA,4,100000\n')
f.write('7,Pave,1,1,1,2,100000\n')
f.write('2,Pave,1,1,2,5,100000\n')
f.write('3,Pave,1,1,NA,NA,100000\n')
f.write('4,Pave,1,1,NA,NA,100000\n')
f.write('NA,Pave,1,1,NA,NA,100000\n')
f.write('5,Pave,1,1,NA,NA,100000\n')
f.write('1,Pave,1,1,NA,NA,100000\n')
f.write('2,Pave,1,1,NA,NA,100000\n')
f.write('3,Pave,1,1,NA,NA,100000\n')
f.write('3,Pave,1,1,NA,NA,100000\n')
f.write('4,Pave,1,1,NA,NA,100000\n')
f.write('2,Pave,1,1,NA,NA,100000\n')
f.write('1,Pave,1,1,NA,NA,100000\n')
import pandas as pd
data = pd.read_csv(data_file)
print(data)
inputs, outputs = data.iloc[:,0:6], data.iloc[:,-1]
need_to_drop = inputs.isnull().sum().idxmax()
inputs = inputs.drop(labels=need_to_drop,axis=1)
print(inputs)
inputs = inputs.fillna(inputs.mean(numeric_only=True))
print(inputs)
inputs = pd.get_dummies(inputs, dummy_na=True, dtype=int)
print(inputs)
X,y = torch.tensor(inputs.values), torch.tensor(outputs.values)
X,y
踩过的坑:
- 新版pandas get_dummies默认展示True False需要指定下类型,否则转tensor会报错
- 找na最大列的时候忘记用idxmax 获取当前列,导致drop报错
- 新版pandas mean 不默认忽略非数字列要显示指定
2.2.2 inputs.mean()调用会报错,因为inputs里面有字符串类型,应该使用inputs.iloc[:,0]去操作才能得到书上的结果
看讨论,mean里面直接加参数numberic_only=True也可以
现在pandas 的get_dummies默认返回bool,如果要返回0,1需要指定参数dtype=numpy.int8